
Here’s a brief follow-up thread answering a sidebar question to the last 2 weeks’ threads on interim analyses in RCT’s and stopping when an efficacy threshold is crossed
https://twitter.com/rafaelmourao29/status/1319968783101026307
The “TL;DR” summary of the previous lesson(s): yes, an RCT that stops early based on an efficacy threshold will tend to overestimate the treatment effect a bit, but that doesn’t actually mean the “trial is more likely to be a false positive result”
(Also, it seems that this is generally true for both frequentist and Bayesian analyses, though the prior may mitigate the degree to which this occurs in a Bayesian analysis)
Anyway, this follow-up question intrigued me: does it matter if the interim analyses are scheduled based on a # of events rather than at fixed # of patients enrolled?
Same basic setup: binary outcome, 40% mortality in control, 30% mortality with intervention, meaning “true” effect in this example is OR=0.65
This time: frequentist trial will take one look at “200 deaths” (rather than 500 patients) and stop if p<0.0054 at interim, otherwise proceeding to recruit until a total N=1000 recruited
In prior threads I plotted the OR estimated every 100 patients; this time, I’ll plot the OR estimated every 50 deaths (though remember, this is just for illustration, we wouldn’t actually be performing interim analyses with efficacy stopping at those points)
45 of the 100 trials with the frequentist approach would cross the efficacy threshold at the “200 events” interim analysis: 

The median OR of the 45 trials that stopped early is 0.56 with a range from 0.42-0.61 (pretty similar results to what we saw with the interim analysis scheduled “500 patients” rather than “200 events”)
I don’t think we would have expected this approach to yield much different results than an interim scheduled for “500 patients” but anyways, here it is. Pretty similar.
If you’re curious about the fully Bayesian equivalent, now let’s do it fully Bayesian where we look every 50 events and stop if Pr(OR<1) >= 0.975 at each respective interim
(Remember, this isn’t set up to perform similarly to the frequentist approach, it’s just a quick “what happens with this design” question)
In this case, 92 trials would conclude efficacy at one of the “every 50 events…” interim analyses before reaching the max total N=1000 patients
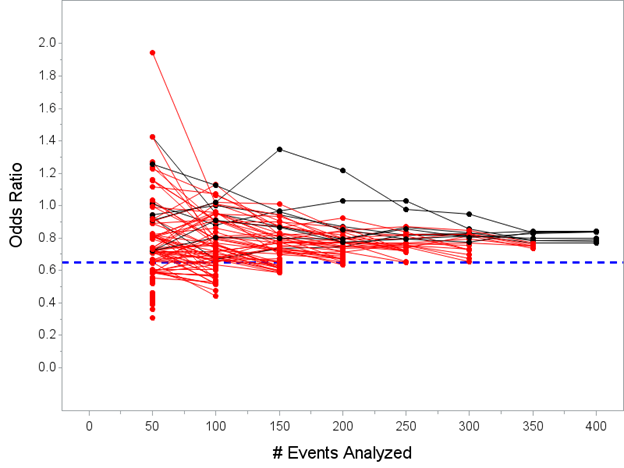
The median of the posterior mean OR’s for those 92 trials is 0.61 (range from 0.31 to 0.77) so again, the Bayesian approach (thanks to prior) slightly mitigates the tendency to overestimate but doesn’t eliminate entirely
In closing: this is one fairly simple simulation of one fairly simple scenario, and you should keep in mind that the specifics of performance characteristics discussed here will vary depending on all of the dials one can twist…
…number of patients, number of interims, timing of interims, stopping thresholds, etc will all influence the degrees to which these things are true.
So please, keep in mind the all-important caveat: It’s Complicated.
So please, keep in mind the all-important caveat: It’s Complicated.
Happy to take requests to answer questions like this that can be illustrated fairly easily via simulation.
Also please note if your question is "What does this look like in the vaccine trials" @KertViele has already covered that very nicely here:
https://twitter.com/KertViele/status/1315011886002339840?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh


