
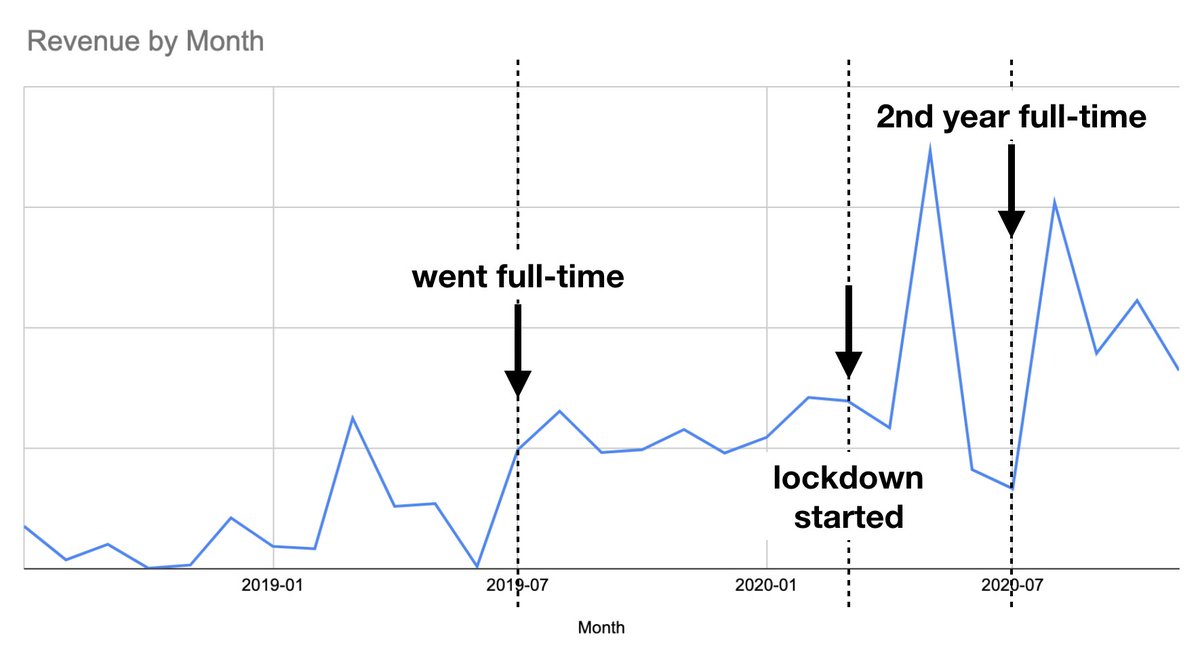
I sat down this weekend and had a look at my finances as I'm almost 5 months into my 2nd year as a full-time solo consultant, and noticed that my revenue streams have changed quite a bit over the last 3 years. 



This is the result of a conscious effort to reduce my reliance on a few large clients, and also to offset seasonalities and other factors that can affect revenue and create a healthy mix of active and passive income streams.
Overall revenue has grown over time, and my largest client now accounts for less than 20% of my revenue. And I haven't seen too much seasonality to my work yet - summer was quieter because Europeans went on holiday, but it was still OK.
I have learnt a lot from @jonathanstark about value pricing and I'm well on the way of moving away from hourly pricing for most of my engagements. I think developing passive income also helps with that, as it softens the blow when I had to say no to potential clients.
I briefly toyed with the idea of forming an agency with my closest friends but quickly realised that it'd take me away from doing what I love - teaching, solving problems and building stuff. So, solo consultant it is for the foreseeable future for me!
Honestly, this journey has been pretty wild, I'm still learning so much still on a daily basis, and it's still the best career decision I have made in a long time, and I'm excited by what lies ahead!
In hindsight, I should have explained what those categories meant to me since they often mean the same thing to many people.. oops! 😅
https://twitter.com/theburningmonk/status/1333113475376230403
• • •
Missing some Tweet in this thread? You can try to
force a refresh



