Docs are ROCs: A simple fix for a methodologically indefensible practice in medical AI studies.
Widely used methods to compare doctors to #AI models systematically underestimate doctors, making the AI look better than it is! We propose a solution.
lukeoakdenrayner.wordpress.com/2020/12/08/doc…
1/7
Widely used methods to compare doctors to #AI models systematically underestimate doctors, making the AI look better than it is! We propose a solution.
lukeoakdenrayner.wordpress.com/2020/12/08/doc…
1/7
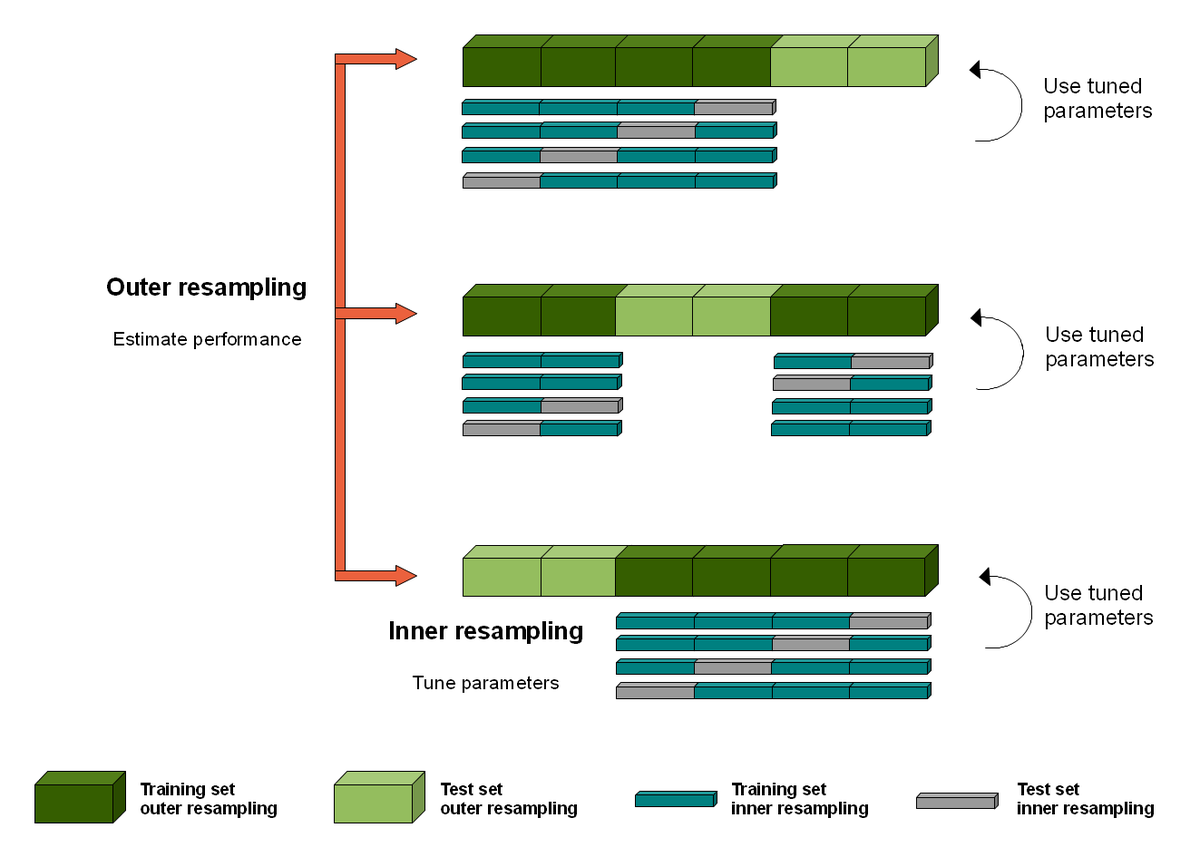
The most common method to estimate average human performance in #medical AI is to average sensitivity and specificity as if they are independent. They aren't though - they are inversely correlated on a curve.
The average points will *always* be inside the curve.
2/7
The average points will *always* be inside the curve.
2/7
The only solution currently is to force doctors to rate images using confidence scores. While this works well in the few tasks where these scales are used in clinical practice, what does it mean to say you are 6/10 confident that there is a lung nodule?
3/7
3/7
Most clinical tasks have 2 (or 3) decision options.
Treat or don't. Biopsy or not.
Forcing doctors to do things that aren't part of their clinical practice is a terrible way to test their performance. We think if a task is binary, test the doctors that way.
4/7
Treat or don't. Biopsy or not.
Forcing doctors to do things that aren't part of their clinical practice is a terrible way to test their performance. We think if a task is binary, test the doctors that way.
4/7
So we suggest a simple off-the-shelf method: SROC analysis. Widely used in the meta-analysis of diagnostic accuracy, SROC is a well understood and validated way to summarise performance across diagnostic experiments.
For AI-human comparisons, each reader is an experiment.
5/7
For AI-human comparisons, each reader is an experiment.
5/7
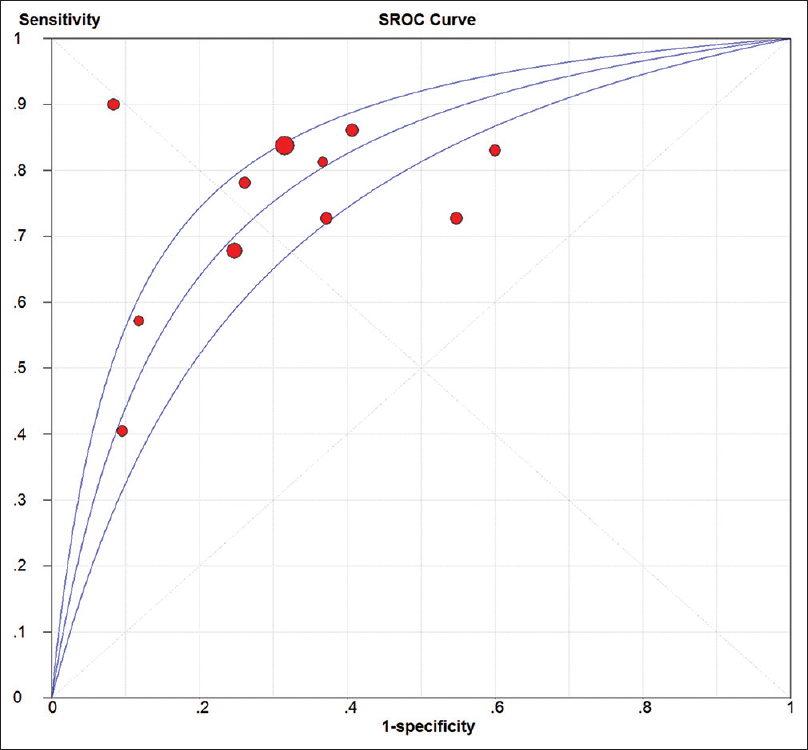
We show how it works be re-evaluating several famous medical AI papers, for example Esteva et al on melanoma (below).
We think this is something everyone can do, and will improve the quality of reporting for AI vs human medical studies.
Check out the blog for more details.
6/7
We think this is something everyone can do, and will improve the quality of reporting for AI vs human medical studies.
Check out the blog for more details.
6/7
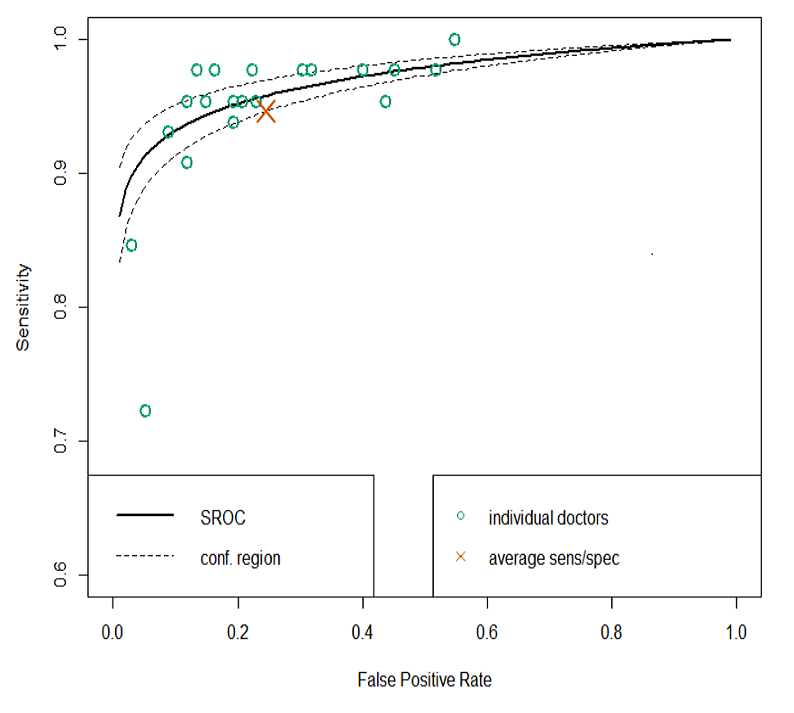
As a quick final note: this doesn't only apply to medical AI studies. We often use similar methods in the radiology literature when we try to determine the accuracy of a test. The SROC approach applies equally well in normal diagnostic research.
7/7
7/7
PS better mention @PalmerLyle who coauthored the paper with me, had the original idea, and inspired my favourite self made gif ever.
• • •
Missing some Tweet in this thread? You can try to
force a refresh