I'm going to attempt to summarize the AWS outage on 25 Nov that impacted a good part of the internet in 6 drawings (from the 2,000+ word detailed postmortem by @awscloud at aws.amazon.com/message/11201/). A thread.
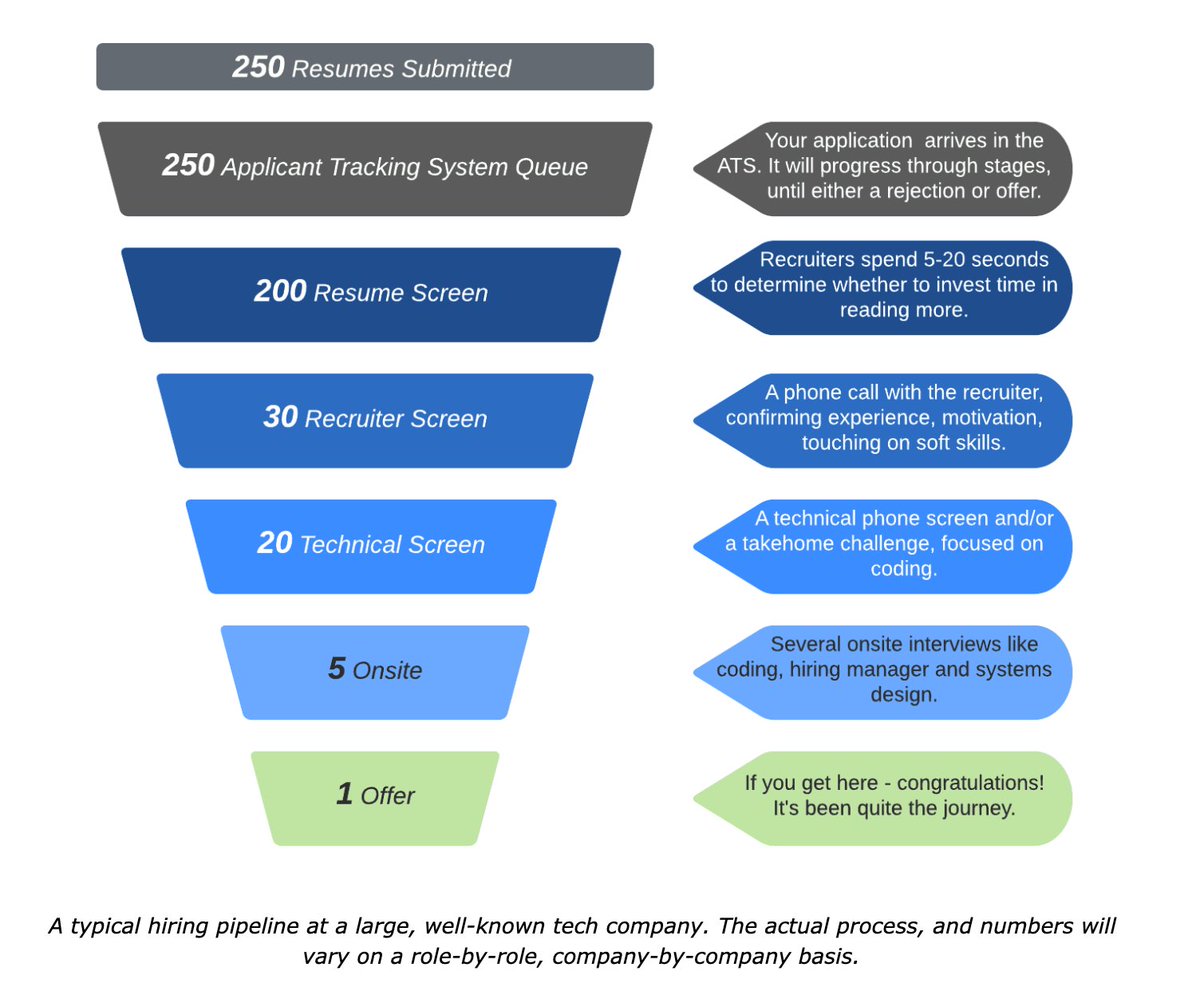
1. Meet AWS Kinesis, the realtime processing backbone of AWS:
1. Meet AWS Kinesis, the realtime processing backbone of AWS:
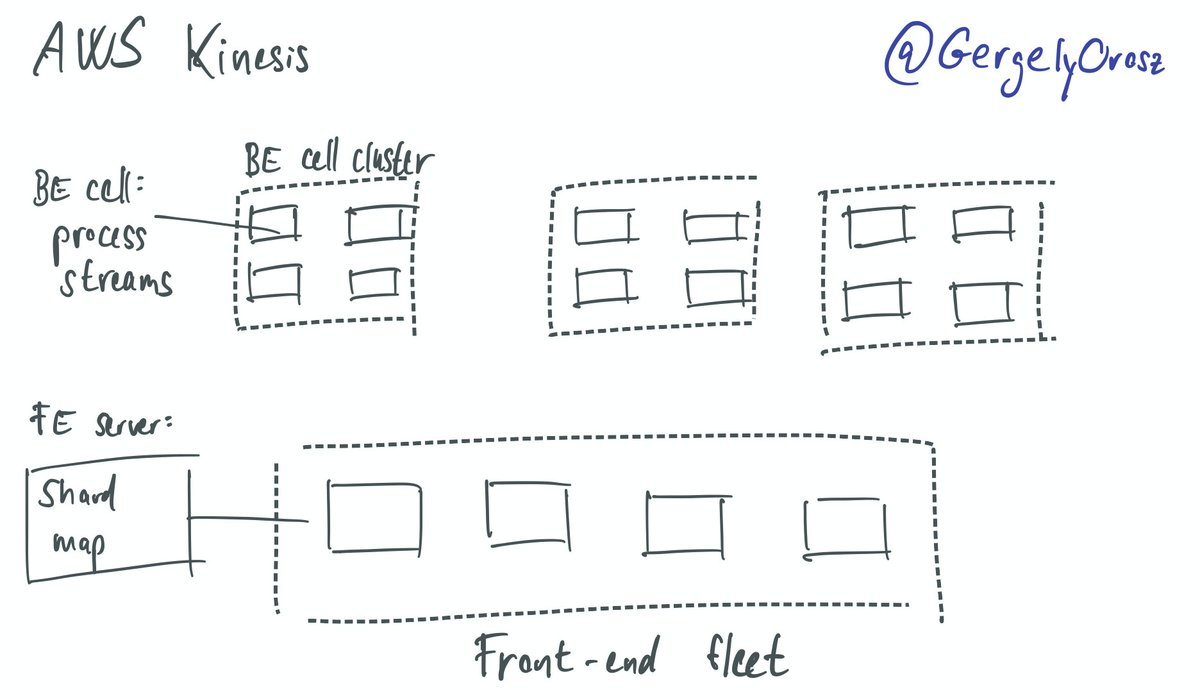
2. Incoming requests hit the FE fleet. Each FE machine maintains a shardmap to BE clusters. Machines in this cluster do the realtime processing.
Classic setup. Except for the scale, which we can assume is massive. That "frontend fleet" is likely large. The BE fleet? Gigantic.
Classic setup. Except for the scale, which we can assume is massive. That "frontend fleet" is likely large. The BE fleet? Gigantic.

3. New FE machines were added to the FE fleet as per usual. A few hours later, things start to work odd. The team investigates and another few hours later they realize the root cause. It's to do with how the FE fleet works.
Each FE machine has a thread open to sync in the fleet:
Each FE machine has a thread open to sync in the fleet:

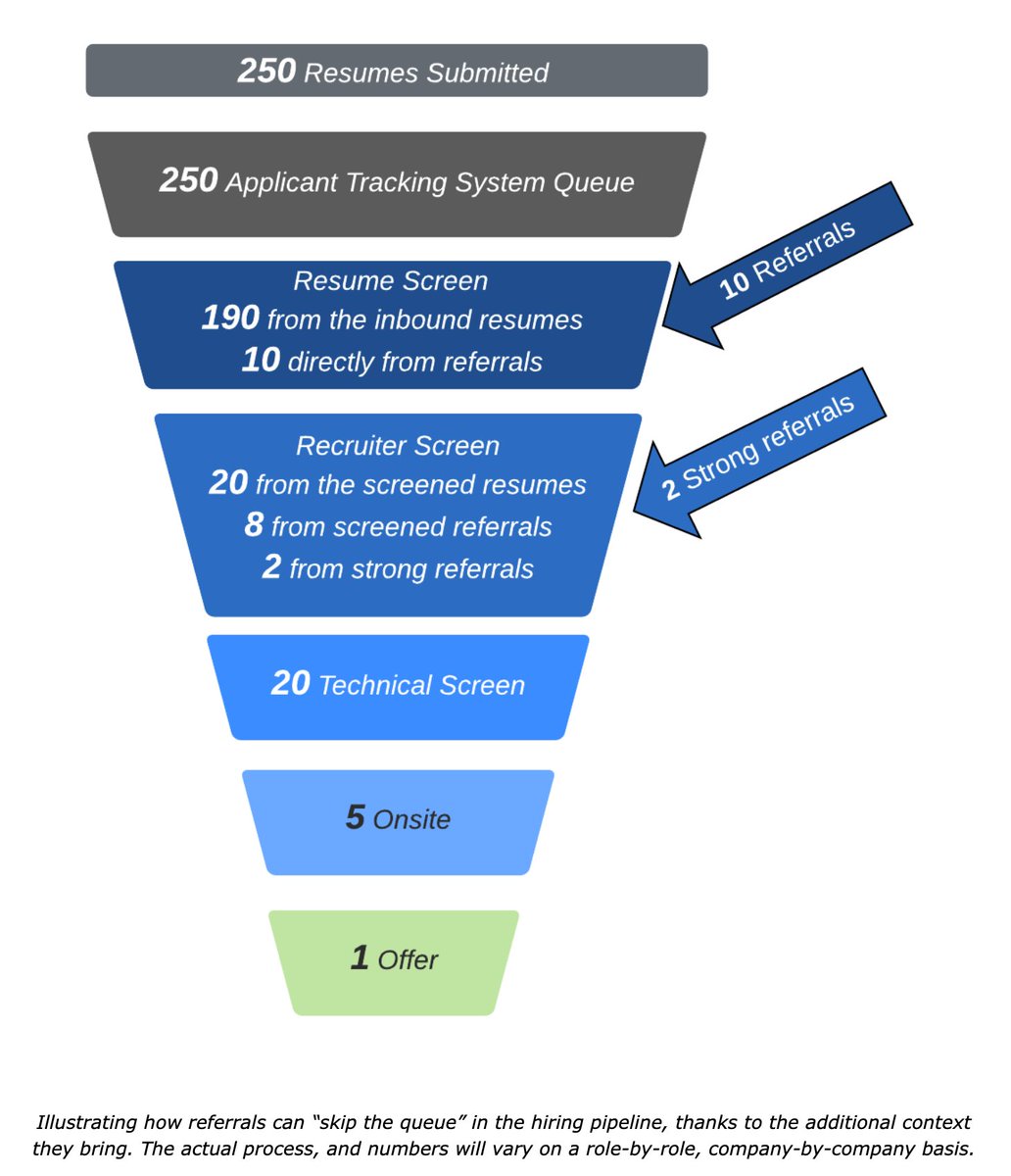
4. Remember how we noted the FE fleet is likely large at Amazon scale? Well it was so large that FE machines ran out of threads to talk with the new machines. Now this is an issue because...

5. ... the shard maps (very) slowly start to become corrupted. When a FE machine reshards a BE cluster, it cannot reach a few machines in the cluster and the other way around. It apparently took a few hours for this to trigger an alarm.
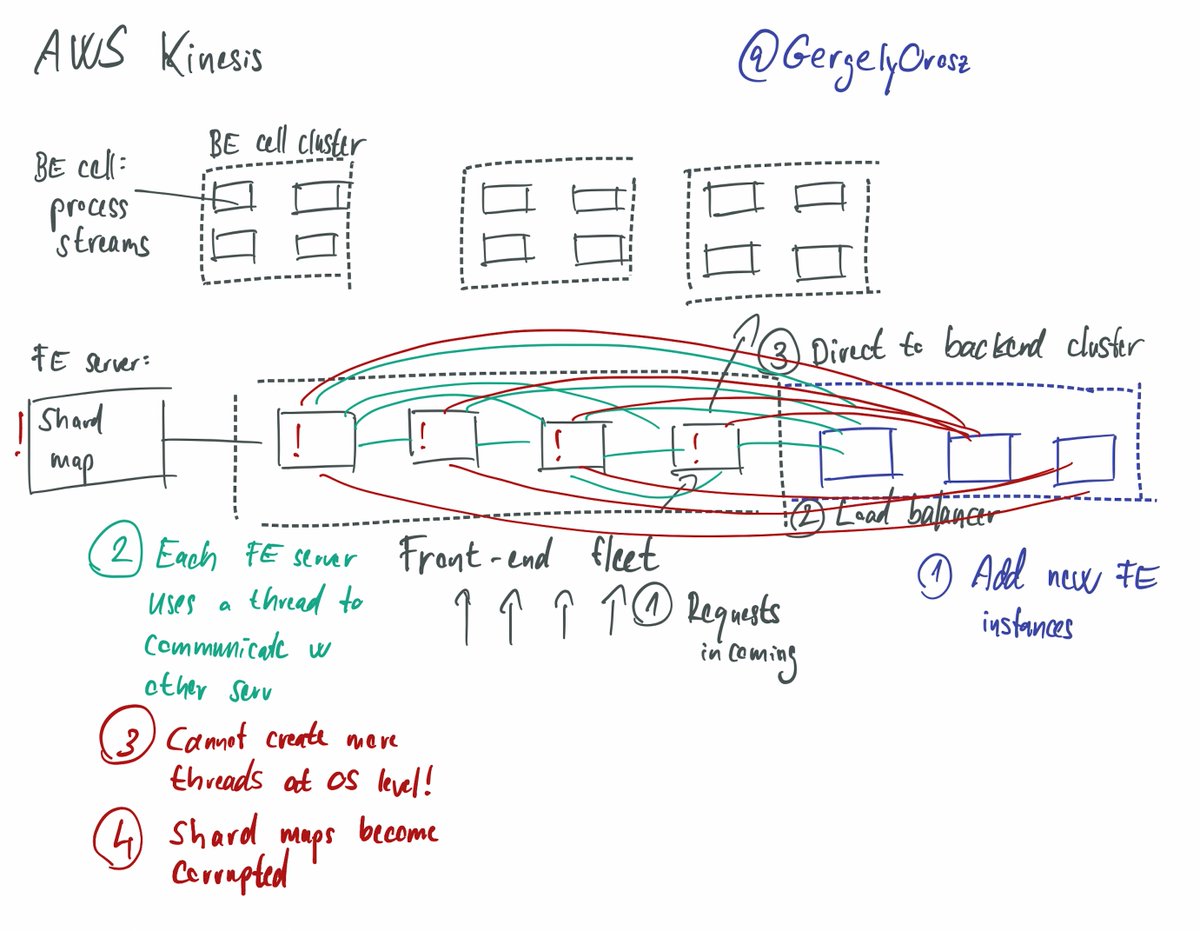
6. Once the damage was done, unlucky requests did not have correct routing to the process streams.
The solution was to remove the new instances and reset the FE fleet (which itself is complicated).
Crazy the # machines hit the OS thread limit. Don't know what this number was.
The solution was to remove the new instances and reset the FE fleet (which itself is complicated).
Crazy the # machines hit the OS thread limit. Don't know what this number was.

The future prevention is to use bigger machines, and have alerts to not get close to this thread issue. I wonder though if it's feasible to not have the one-thread-per-machine protocol. Probably too big of a change.
Kudos for the transparency @awscloud! aws.amazon.com/message/11201/
Kudos for the transparency @awscloud! aws.amazon.com/message/11201/
• • •
Missing some Tweet in this thread? You can try to
force a refresh