Semi-supervised learning with consistency regularization and pseudo-labeling works great for CLASSIFICATION.
But how about STRUCTURED PREDICTION tasks? 🤔
Check out @ylzou_Zack's #ICLR2021 paper on designing pseudo-labels for semantic segmentation.
yuliang.vision/pseudo_seg/
But how about STRUCTURED PREDICTION tasks? 🤔
Check out @ylzou_Zack's #ICLR2021 paper on designing pseudo-labels for semantic segmentation.
yuliang.vision/pseudo_seg/
How do we get pseudo labels from unlabeled images?
Unlike classification, directly thresholding the network outputs for dense prediction doesn't work well.
Our idea: start with weakly sup. localization (Grad-CAM) and refine it with self-attention for propagating the scores.
Unlike classification, directly thresholding the network outputs for dense prediction doesn't work well.
Our idea: start with weakly sup. localization (Grad-CAM) and refine it with self-attention for propagating the scores.

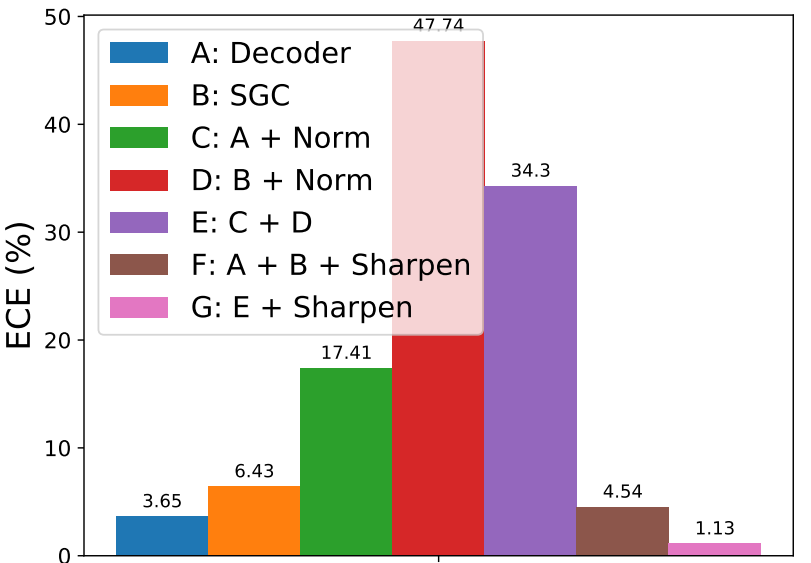
Using two different prediction mechanisms is great bc they make errors in different ways. With our fusion strategy, we get WELL-CALIBRATED pseudo labels (see the expected calibration errors in E below) and IMPROVED accuracy under 1/4, 1/8, 1/16 of labeled examples.
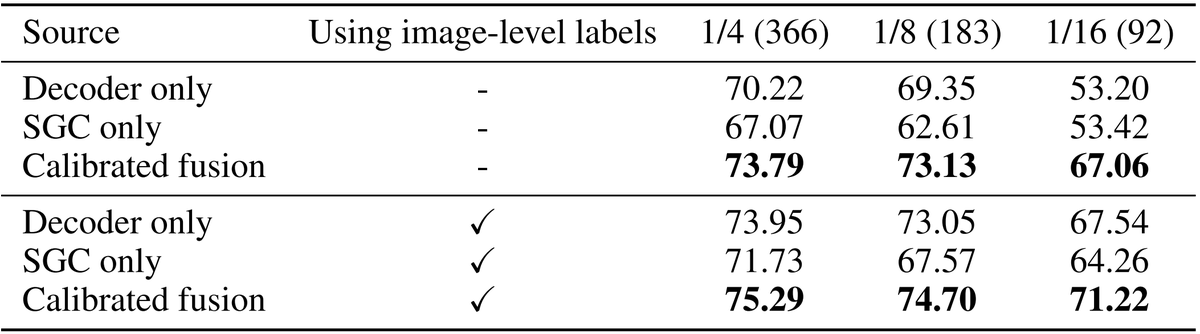
Evaluation of VOC12 and COCO datasets show consistent improvement over the supervised approach under different portions of labeled examples.

One cool thing is that our method can also further improve fully supervised models trained on a FULL DATASET with additional *unlabeled* data.
Isn't that awesome?
Isn't that awesome?
Check out the more details in the paper, supp material, and code.
Paper: openreview.net/forum?id=-TwO9…
Web: yuliang.vision/pseudo_seg/
Code: github.com/googleinterns/…
Work led by @ylzou_Zack with friends at Google (@ZizhaoZhang, Han Zhang, @chunliang_tw, Xiao Bian, and @tomaspfister).
Paper: openreview.net/forum?id=-TwO9…
Web: yuliang.vision/pseudo_seg/
Code: github.com/googleinterns/…
Work led by @ylzou_Zack with friends at Google (@ZizhaoZhang, Han Zhang, @chunliang_tw, Xiao Bian, and @tomaspfister).
• • •
Missing some Tweet in this thread? You can try to
force a refresh