Neural Volume Rendering for Dynamic Scenes
NeRF has shown incredible view synthesis results, but it requires multi-view captures for STATIC scenes.
How can we achieve view synthesis for DYNAMIC scenes from a single video? Here is what I learned from several recent efforts.
NeRF has shown incredible view synthesis results, but it requires multi-view captures for STATIC scenes.
How can we achieve view synthesis for DYNAMIC scenes from a single video? Here is what I learned from several recent efforts.
Instead of presenting Video-NeRF, Nerfie, NR-NeRF, D-NeRF, NeRFlow, NSFF (and many others!) as individual algorithms, here I try to view them from a unifying perspective and understand the pros/cons of various design choices.
Okay, here we go.
Okay, here we go.
*Background*
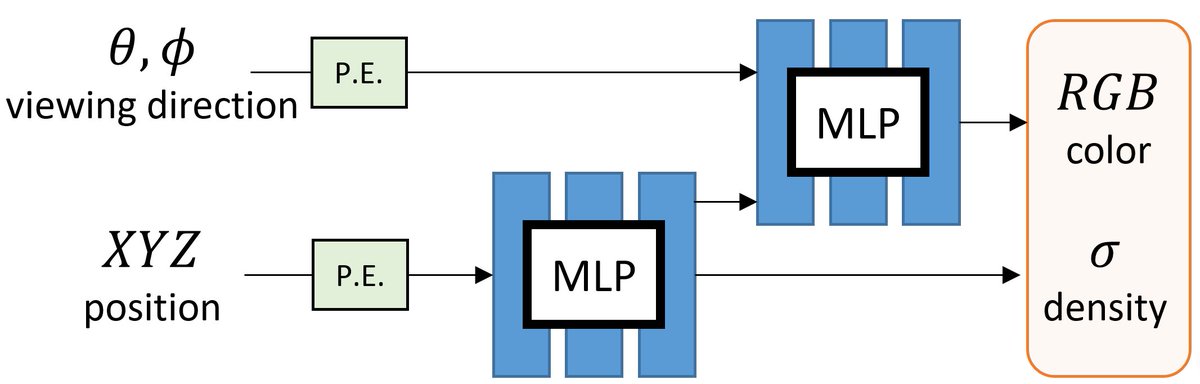
NeRF represents the scene as a 5D continuous volumetric scene function that maps the spatial position and viewing direction to color and density. It then projects the colors/densities to form an image with volume rendering.
Volumetric + Implicit -> Awesome!
NeRF represents the scene as a 5D continuous volumetric scene function that maps the spatial position and viewing direction to color and density. It then projects the colors/densities to form an image with volume rendering.
Volumetric + Implicit -> Awesome!
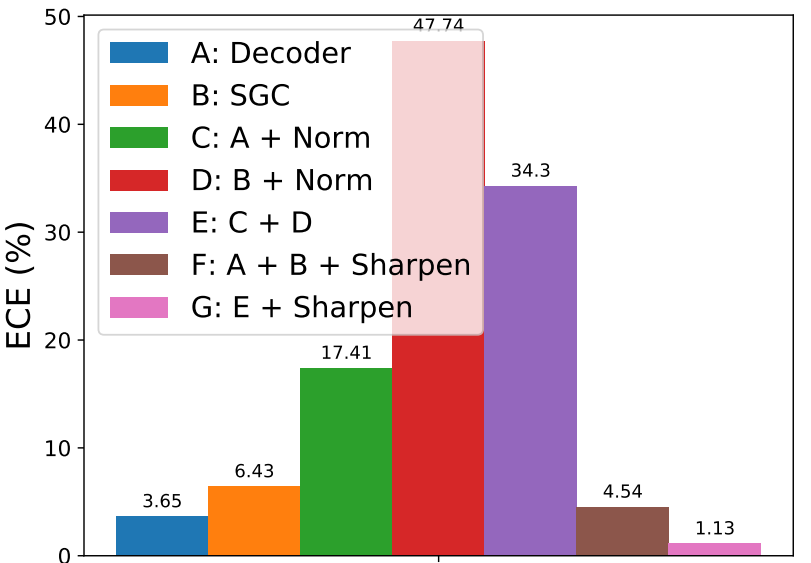
*Model*
Building on NeRF, one can extend it for handling dynamic scenes with two types of approaches.
A) 4D (or 6D with views) function.
One direct approach is to include TIME as an additional input to learn a DYNAMIC radiance field.
e.g., Video-NeRF, NSFF, NeRFlow
Building on NeRF, one can extend it for handling dynamic scenes with two types of approaches.
A) 4D (or 6D with views) function.
One direct approach is to include TIME as an additional input to learn a DYNAMIC radiance field.
e.g., Video-NeRF, NSFF, NeRFlow
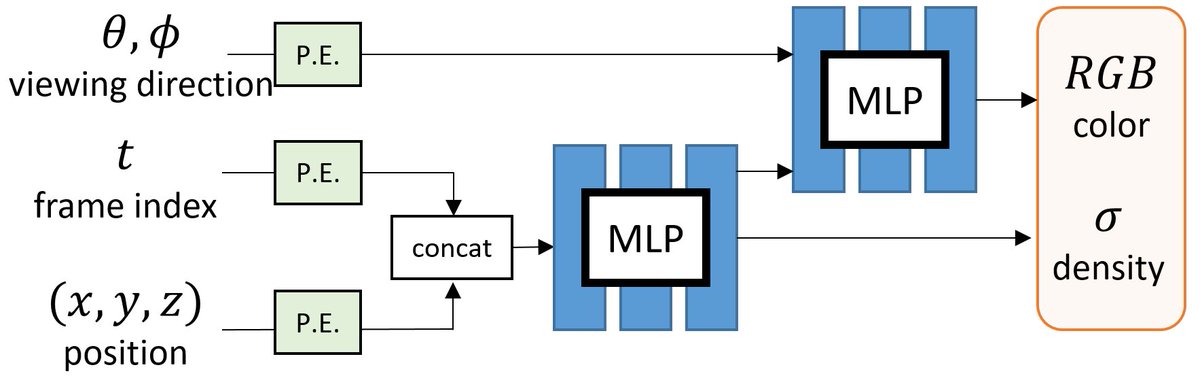
B) 3D Template with Deformation.
Inspired by non-rigid reconstruction methods, this type of approach learns a radiance field in a canonical frame (template) and predicts deformation for each frame to account for dynamics over time.
e.g., Nerfie, NR-NeRF, D-NeRF
Inspired by non-rigid reconstruction methods, this type of approach learns a radiance field in a canonical frame (template) and predicts deformation for each frame to account for dynamics over time.
e.g., Nerfie, NR-NeRF, D-NeRF
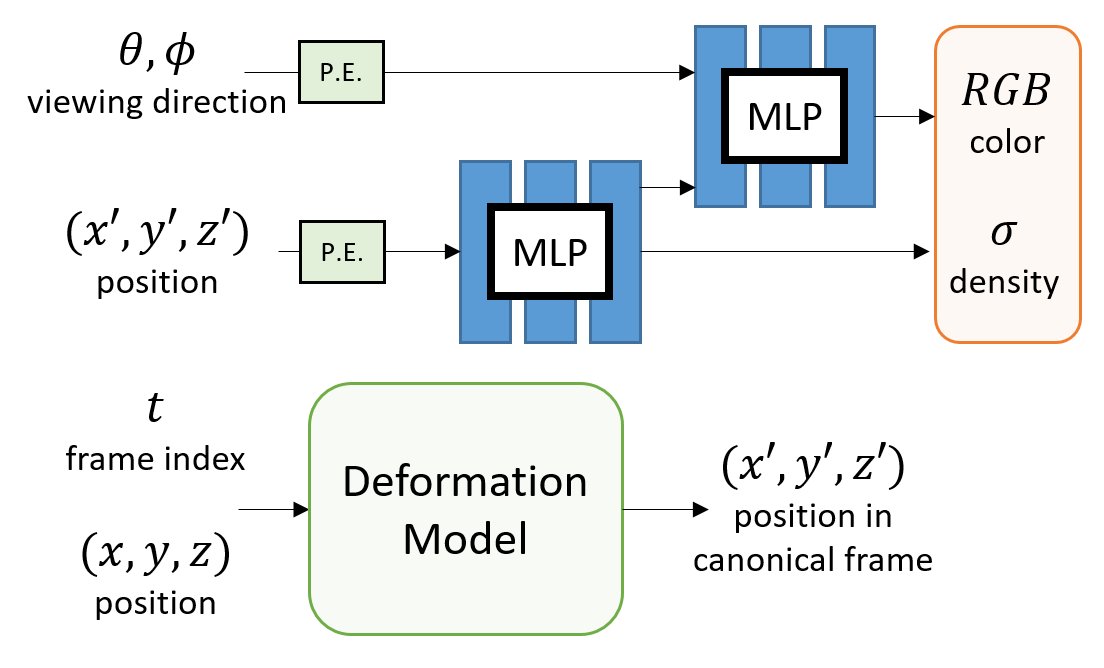
*Deformation Model*
All the methods use an MLP to encode the deformation field. But, how do they differ?
A) INPUT: How to encode the additional time dimension as input?
B) OUTPUT: How to parametrize the deformation field?
All the methods use an MLP to encode the deformation field. But, how do they differ?
A) INPUT: How to encode the additional time dimension as input?
B) OUTPUT: How to parametrize the deformation field?
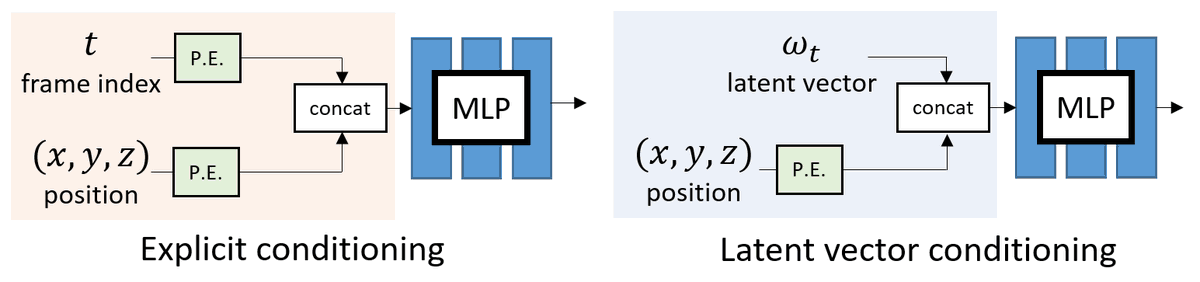
A) Input conditioning
One can choose to use EXPLICIT conditioning by treating the frame index t as input.
Alternatively, one can use a learnable LATENT vector for each frame.
One can choose to use EXPLICIT conditioning by treating the frame index t as input.
Alternatively, one can use a learnable LATENT vector for each frame.
B) Output parametrization
We can either use the MLP to predict
- dense 3D translation vectors (aka scene flow) or
- dense rigid motion field
We can either use the MLP to predict
- dense 3D translation vectors (aka scene flow) or
- dense rigid motion field
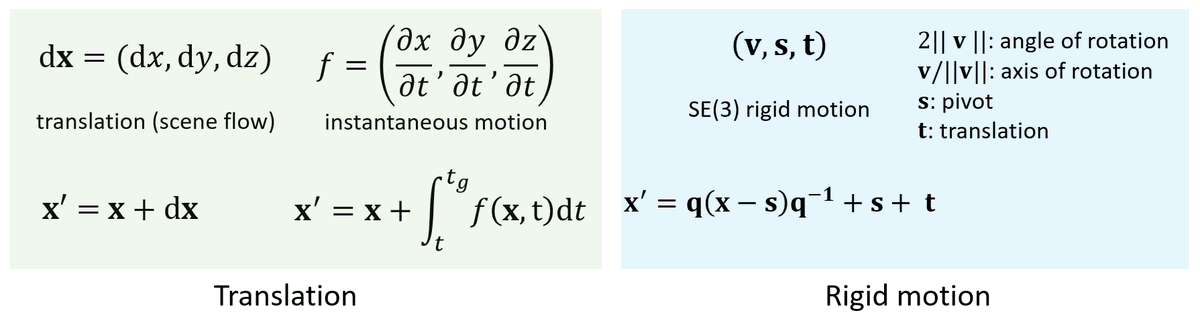
With these design choices in mind, we can mix-n-match to synthesize all the methods.

*Regularization*
Adding the deformation field introduces ambiguities. So we need to make it "well-behaved", e.g., the deformation field should be spatially smooth, temporally smooth, sparse, and avoid contraction and expansion.
Adding the deformation field introduces ambiguities. So we need to make it "well-behaved", e.g., the deformation field should be spatially smooth, temporally smooth, sparse, and avoid contraction and expansion.
*Depth supervision*
Unlike other methods above, Video-NeRF (shameless plug here) does not require a separate deformation field (and various other regularization terms) by using direct depth supervision to constrain the time-varying geometry.
Unlike other methods above, Video-NeRF (shameless plug here) does not require a separate deformation field (and various other regularization terms) by using direct depth supervision to constrain the time-varying geometry.
https://twitter.com/JPKopf/status/1331782087351754753
With further improvement on single video depth estimation (another shameless plug 🤩), I am very excited to see dynamic view synthesis on videos in the wild soon!
https://twitter.com/jbhuang0604/status/1337550494269583360
So...what are the best methods/practices 🤔? I don't know.
3D template-based methods can achieve really good visual quality but may have limitations on the amounts of dynamics.
4D function is more general, but it may require designing effective constraints for regularization.
3D template-based methods can achieve really good visual quality but may have limitations on the amounts of dynamics.
4D function is more general, but it may require designing effective constraints for regularization.
Check out these papers and their cool video demos!
Video-NeRF video-nerf.github.io
Nerfie nerfies.github.io
NR-NeRF gvv.mpi-inf.mpg.de/projects/nonri…
D-NeRF albertpumarola.com/research/D-NeR…
NeRFlow yilundu.github.io/nerflow/
NSFF cs.cornell.edu/~zl548/NSFF/
Video-NeRF video-nerf.github.io
Nerfie nerfies.github.io
NR-NeRF gvv.mpi-inf.mpg.de/projects/nonri…
D-NeRF albertpumarola.com/research/D-NeR…
NeRFlow yilundu.github.io/nerflow/
NSFF cs.cornell.edu/~zl548/NSFF/
This is by no means a complete list. Please let me know if you know of other relevant works in this domain.
For a border view of the "NeRF explosion" and background, check out @fdellaert's blog dellaert.github.io/NeRF/
and Frank and @yen_chen_lin's report
arxiv.org/abs/2101.05204
For a border view of the "NeRF explosion" and background, check out @fdellaert's blog dellaert.github.io/NeRF/
and Frank and @yen_chen_lin's report
arxiv.org/abs/2101.05204
To learn more about these, come and chat with us in the reading group at 13:00-14:00 EST on Jan 20.
yenchenlin.me/3D-representat…
yenchenlin.me/3D-representat…
• • •
Missing some Tweet in this thread? You can try to
force a refresh