Goedemorgen! Vandaag ga ik aan een artikel werken wat al een paar maanden praktisch af op de plank ligt. Extra leuk: ik schrijf dit stuk met mijn vader, biomedisch ingenieur en sinds kort ook werkzaam als UHD bij nefrologie @UMCUtrecht! We zijn dus collega's! Maar hoe kan dat?
Onze vakgebieden zijn heel erg verschillend toch? Ja, dat klopt! Het gaat om een artikel waarin we mijn methodologie voor het doen van een 'fuzzy' literatuurstudie operationaliseren voor alle disciplines: alfa, beta, gamma.
Eerst even iets over die methodologie. Toen ik begon met mijn promotieonderzoek was er nog geen definitie van algorithmic accountability. Knap onhandig als je er onderzoek naar wil doen. De term was te nieuw, maar komt natuurlijk niet uit het luchtledige vallen.
Er was dus een hoop materiaal wat ermee te maken had of het besprak zonder die term te gebruiken. Maar hoe vindt je dat zonder zoekterm? Ik bedacht een truc. Artikelen worden veelal voorzien van keywords: dat wat de auteur de kortste beschrijving van de inhoud/het thema vindt.
Ik gebruik deze termen om verwante artikelen te zoeken. Door te beginnen met een kleine set relevante artikelen, die keywords te verzamelen, een 'query' (zoekterm) te bouwen. Dat doe ik een aantal keer. In deze blog leg ik het uit. datafiedsociety.nl/doing-a-system…
In het kort: ik verzamelde al die keywords, en ik keek naar de sterkte van relaties tussen keywords. Levert mooie plaatjes, maar belangrijker nog interessante patronen in de relaties tussen artikelen op. De gevonden artikelen las ik door de les van accountability theorie. 
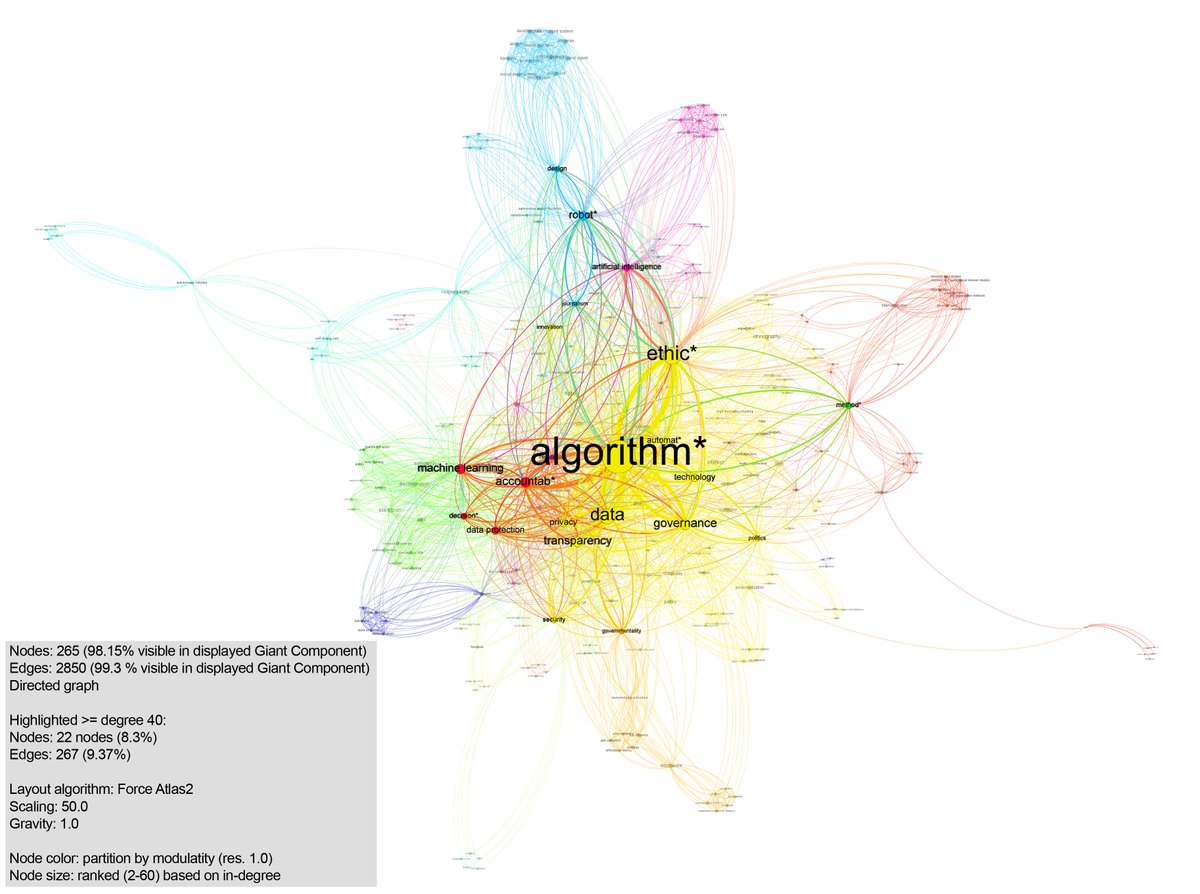
Waarom is dat nuttig? Nou, ik heb op deze manier een heel goed overzicht gekregen van wat er gezegd is over algorithmic accountability over vakgebieden heen. Je vindt de rode draad. Ik presenteerde dit op ACM FAT*, voor mij de belangrijkste conferentie. 👇
En niet onverdienstelijk! Ik won de prijs voor beste niet-computerwetenschappelijke student paper. 🎉
Het paper vindt je hier: dl.acm.org/doi/abs/10.114…
Het paper vindt je hier: dl.acm.org/doi/abs/10.114…
https://twitter.com/FAccTConference/status/1222945357425991681
Een paar maanden eerder had ik het er aan de spreekwoordelijke keukentafel over met mijn vader. Ik legde mijn probleem en oplossing uit. Hij viel praktisch met open mond van zijn stoel. Net als ik bevindt hij zich ook vaak op het kruispunt van disciplines.
Net als ik worstelt hij ook regelmatig met de verschillende termen die gebruikt worden, of een fenomeen wat zo nieuw is dat er nog maar net een woord voor is. Maar wetenschap ontstaat niet in een vacuüm. We staan op de schouders van reuzen. Er is altijd eerder/gerelateerd werk.
Hij zag potentie in de methodologie voor zijn werk, eigen vakgebied en beiden zagen we ook het bredere nut. Ondertussen zou het methodologiestuk teveel zijn voor mijn dissertatie, maar het was na 1,5 jaar wel mijn kindje geworden en ik wou het niet ergens laten verstoffen.
En zo geschiedde deze bijzondere samenwerking: ik lever de methodologie, en mijn vader helpt om dit te generaliseren.
Leuk om te doen, want we kennen elkaar natuurlijk heel goed. De helft van de tijd maken we elkaars zinnen af. 😋 Nog belangrijker: het werk wordt er beter van!
Leuk om te doen, want we kennen elkaar natuurlijk heel goed. De helft van de tijd maken we elkaars zinnen af. 😋 Nog belangrijker: het werk wordt er beter van!
• • •
Missing some Tweet in this thread? You can try to
force a refresh