
#rstats users who are planning to learn #python, welcome to another edition of tweetorial.
The idea is to leverage your experience with R to explain python concepts w/o going into too much detail. For details, refer the links attached at the bottom.
The idea is to leverage your experience with R to explain python concepts w/o going into too much detail. For details, refer the links attached at the bottom.
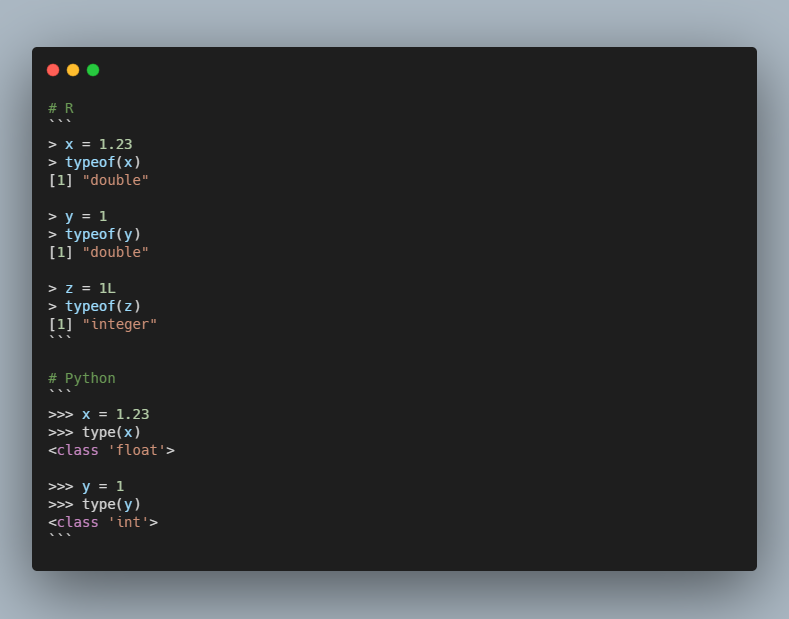
For today, I am covering the data types in python (except complex, binary types). R has data types: integer, double, character and boolean. Well python too has the same data types, although some names are different. In R `integer` cannot be a fractional and is written by
suffixing L, in python it's `int`. In R fractionals are called `double` (like 1.2), In python they are called `float`. In both R python it is not necessary to specify the type. While in R the type of a number is `double` unless specified by `L`, python infers it automatically. 
Just like in R, booleans in Python are straightforward (True, False, 1 and 0). For strings, python has some special tricks up it's sleeves. In python you can add and multiply strings.

While with base R, you have to use `paste()` to combine strings with strings (or variables) python provides special methods (think of as functions for strings) for that. The closest R package to python's method is {glue}.

The other builtin data types in python are lists, tuple, dictionary and sets. I think of them as collectibles, each can hold more than one value and have special properties. The closest data type to all these in R is lists.
Just like in R, lists can hold multiple values of different types, in python lists, tuple, dictionary, sets can hold multiple values of different types. In python lists and tuple are almost same except lists are mutable and tuple aren't i.e. once created you can change elements

of a list but not of tuple. Indexing lists (or tuple) in python is similar to R, using `[`, except lists are zero indexed and unlike R using single square brackets returns the elements not lists. So you don't have to use double square brackets.

Dictionaries are like named lists in R (or like JSONs) except names (or keys) has to be unique in a dictionary, If duplicate keys are there, the later occurrence will replace the previous one (as shown below) but in R, a list can have duplicate names.
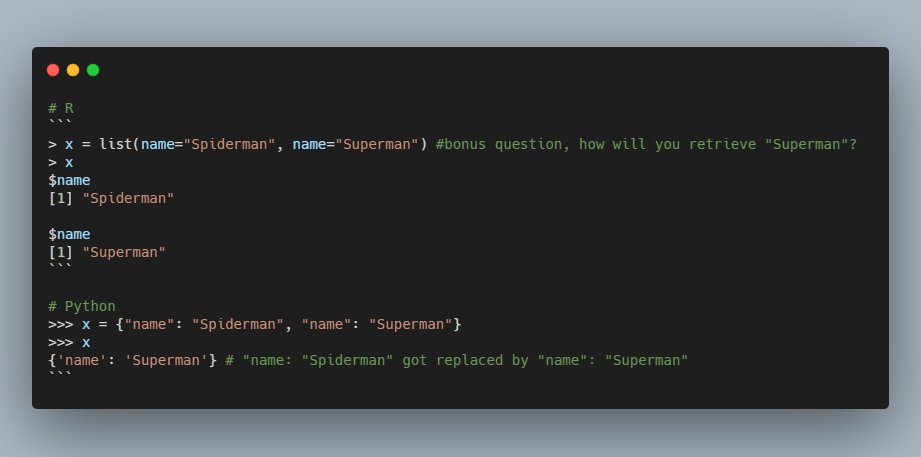
Retrieving elements from dictionaries is similar to that of R's. While in R, you use double brackets and a name to retrieve an element, in python you use single bracket and a name to get an element. (Although in R, you can also use `$` but not in python)

Sets in python are like applying `unique()` to a vector in R i.e. in python a set can only have unique values.

Links:
Vectors in R: bit.ly/3osuUAk
Data types in python: bit.ly/3t5XbAp & bit.ly/39xiIKz
code images generated using: carbon.now.sh
Vectors in R: bit.ly/3osuUAk
Data types in python: bit.ly/3t5XbAp & bit.ly/39xiIKz
code images generated using: carbon.now.sh
If you enjoyed this tweetorial, be sure to retweet and follow for more such content and a daily question on either of R/Python/DS.
And if you really really really like the tweetorial, you can support by making a contribution at: buymeacoffee.com/NgFs2zX
And if you really really really like the tweetorial, you can support by making a contribution at: buymeacoffee.com/NgFs2zX
• • •
Missing some Tweet in this thread? You can try to
force a refresh




