This was a nightmare project to work on, with a frankenstein audio recording mash up but I can't muster the strength and necessary time to re-record+cut the thing again.
Topic and details are quite interesting though.
Summary pictures follow this thread.
Topic and details are quite interesting though.
Summary pictures follow this thread.
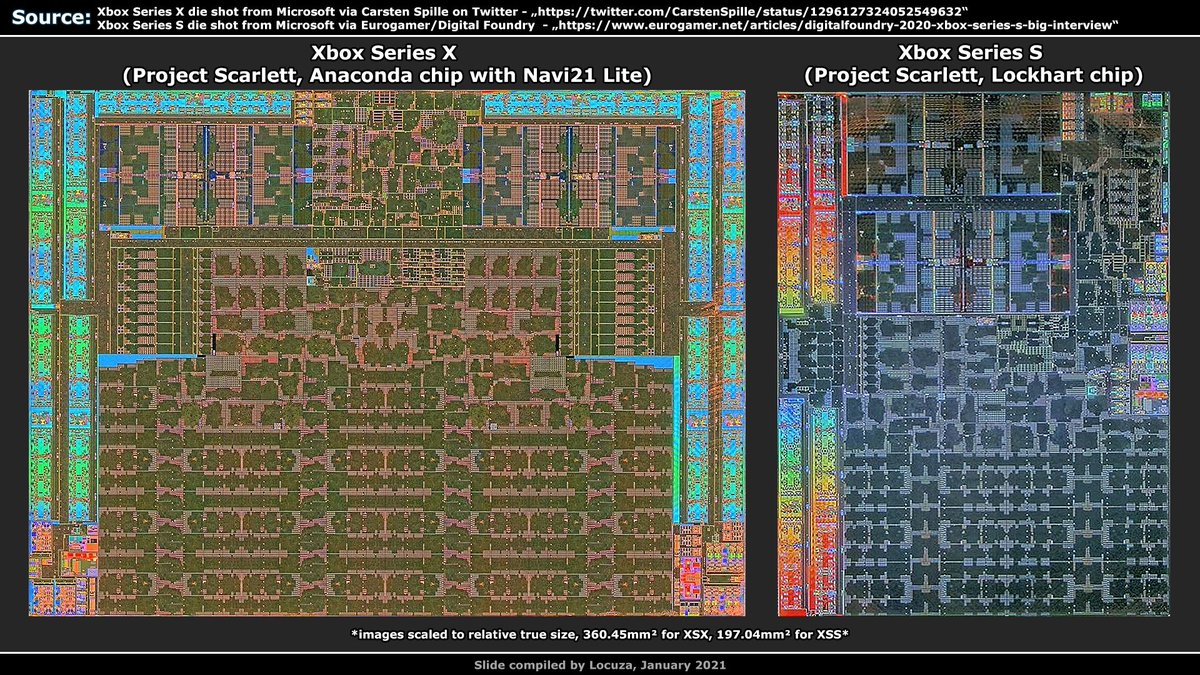
1) Xbox Series X/S die shots scaled to relative true size.
(It's not super accurate though)
2) PS4&Xbox One die shots scaled to relative true size
3.) ^ with annotations
If people are curious about the PS4/Xbox One gen, I could make an extra video for them.
(It's not super accurate though)
2) PS4&Xbox One die shots scaled to relative true size
3.) ^ with annotations
If people are curious about the PS4/Xbox One gen, I could make an extra video for them.


1) PS4 Pro and Xbox One X die shots scaled to relative true size.
2) ^ with annotations
Again, if someone wants a deep dive on those chips, I could make a video on it.
2) ^ with annotations
Again, if someone wants a deep dive on those chips, I could make a video on it.


Thanks to stblr's firmware extraction we got a great insight into the fine mixture of many different hardware IP blocks used for one GPU or APU chip.
This enables us to make a relatively precise comparison between RDNA1, 2 and the Xbox Series chips and verify the claim, if ...
This enables us to make a relatively precise comparison between RDNA1, 2 and the Xbox Series chips and verify the claim, if ...
..the Xbox Series X/S are really based on RDNA2 or what differences exist.
There are multiple differences and aspects which differ and are quite interesting to talk about.
For example the codename Navi21 Lite is pointless, in the sense that the XSX has no direct relationship...
There are multiple differences and aspects which differ and are quite interesting to talk about.
For example the codename Navi21 Lite is pointless, in the sense that the XSX has no direct relationship...

..with Navi21.
It uses a very unique hw configuration and different hw IPs in many places.
The codename also could have been Navi22 Lite, Navi X Lite or Ketchup 27, since there is little to no meaning behind it.
---
Many IP blocks on the XSX are older than on Navi2X, however..
It uses a very unique hw configuration and different hw IPs in many places.
The codename also could have been Navi22 Lite, Navi X Lite or Ketchup 27, since there is little to no meaning behind it.
---
Many IP blocks on the XSX are older than on Navi2X, however..
...some are also newer than on Navi2X and some even older than on Navi1X GPUs.
Probably many hw IP blocks have their own development timeline and depending on the dynamics during the whole chip project, some aspects are settled down sooner than on other chips, leading to such..
Probably many hw IP blocks have their own development timeline and depending on the dynamics during the whole chip project, some aspects are settled down sooner than on other chips, leading to such..

..a funny mixture of older and newer IP blocks per chip project.
Though it also should be noted that not every IP version is directly comparable.
For example the UMC version for HBM memory on Navi12 is 6.5 in comparison to 8.X on GDDR6 UMCs for Navi1/2X GPUs...
Though it also should be noted that not every IP version is directly comparable.
For example the UMC version for HBM memory on Navi12 is 6.5 in comparison to 8.X on GDDR6 UMCs for Navi1/2X GPUs...
The NBIF block is also such a candidate.
It starts with 2.x or 3.x on Navi1X and Navi2X but has the version number 7.4.2 on the Xbox Series X.
AMD's upcoming Van Gogh and Rembrandt APUs are also starting with 7.X.
It starts with 2.x or 3.x on Navi1X and Navi2X but has the version number 7.4.2 on the Xbox Series X.
AMD's upcoming Van Gogh and Rembrandt APUs are also starting with 7.X.
The XSX is using the Graphics Core version 10.2.
The PS5 10.0.
Some people probably wondered, why RDNA1 GPUs from AMD start with 10.1 and not 10.0 and why do we have the jump to 10.3 on RDNA2 GPUs?
Custom chips are using 10.0 and 10.2 GC IP.
So what's the difference there?
The PS5 10.0.
Some people probably wondered, why RDNA1 GPUs from AMD start with 10.1 and not 10.0 and why do we have the jump to 10.3 on RDNA2 GPUs?
Custom chips are using 10.0 and 10.2 GC IP.
So what's the difference there?
That's not so easy to answer, since a couple of differences between RDNA1 and RDNA2 GPUs can't be checked on the XSX.
However there is one piece which AMDs open source drivers mention.
The pa_sc_tile_steering_override bit (PA = Primitive Assembly, SC = Scan Converter) is not...
However there is one piece which AMDs open source drivers mention.
The pa_sc_tile_steering_override bit (PA = Primitive Assembly, SC = Scan Converter) is not...

..programmable under GFX10.3 but on all GFX 10.X versions previously.
GFX10.3 also removed the DFSM hw for full primitive binning.
GFX10.1 still has it, potentially GFX10.2 too but it's unlikely that Microsoft will expose it, even if it is.
GFX10.3 also removed the DFSM hw for full primitive binning.
GFX10.1 still has it, potentially GFX10.2 too but it's unlikely that Microsoft will expose it, even if it is.
Other things which can't be confirmed/denied are larger SDMA copy sizes on GFX10.2, respectively on the SDMA version side.
Also if MSAA image load, global thread ID for loads&stores and the global atomic clamped substraction is included on GFX10.2, which came with GFX10.3.
Also if MSAA image load, global thread ID for loads&stores and the global atomic clamped substraction is included on GFX10.2, which came with GFX10.3.
Further and more interesting would be to know, if the allocation granularity for the register file and Local Data Share is also twice as large as on RDNA2 or the same as on RDNA1 GPUs?
I rather think that the latter is the case, to get a behavior more closely related to GCN.
I rather think that the latter is the case, to get a behavior more closely related to GCN.

Now we can talk about some differences we know about.
1.) The XSX uses 20 Wave Controllers per SIMD engine as RDNA1 GPUs.
Every RDNA2 chip from AMD only has 16.
I don't think this has any significant performance implications and it was an economic cut for RDNA2 however for the...
1.) The XSX uses 20 Wave Controllers per SIMD engine as RDNA1 GPUs.
Every RDNA2 chip from AMD only has 16.
I don't think this has any significant performance implications and it was an economic cut for RDNA2 however for the...

..Xbox Series it was probably desirable to support the same thread group size as on previous GCN versions for smoother backwards compatibility.
2.) The XSX uses the same rendering frontend setup as RDNA1 GPUs.
2 Primitive Units and 2 Scan Converter (each with 2 Packers) per SE.
2.) The XSX uses the same rendering frontend setup as RDNA1 GPUs.
2 Primitive Units and 2 Scan Converter (each with 2 Packers) per SE.

This doesn't necessarly mean that the rendering frontend is exactly the same as on RDNA1 GPUs, there are many sub-blocks which could be different however one can wonder why such a configuration was chosen?
New frontend design too late for the project or not desirable?
New frontend design too late for the project or not desirable?
I tend to the later because RDNA2 GPUs only have one Primitive Unit per SE instead of previously two.
Together with the new Rasterizer which is now working with 32 Pixels it could have been challenging in some cases to have good performance.
I'm very curious about N22 perf here.
Together with the new Rasterizer which is now working with 32 Pixels it could have been challenging in some cases to have good performance.
I'm very curious about N22 perf here.
3.) Also as on RDNA1 GPUs, the XSX uses two sub-arrays per Shader Array.
We have 4 WGPs on one sub-array (WGP0) and 3 on another (WGP1).
Currently not a single upcoming RDNA2 GPU/APU will use two sub-arrays. (Navi24 could be one?)
They all have their WGPs on only one sub-array.
We have 4 WGPs on one sub-array (WGP0) and 3 on another (WGP1).
Currently not a single upcoming RDNA2 GPU/APU will use two sub-arrays. (Navi24 could be one?)
They all have their WGPs on only one sub-array.

That's basically it in terms of differences.
Since the XSX does support ray tracing acceleration, Mesh Shaders, Sampler Feedback, Variable Rate Shading and is also showing great efficiency numbers, indicating that a lot of the physical design work for RDNA2 is used, I would ...
Since the XSX does support ray tracing acceleration, Mesh Shaders, Sampler Feedback, Variable Rate Shading and is also showing great efficiency numbers, indicating that a lot of the physical design work for RDNA2 is used, I would ...


..give the marketing guys a greenlight here.
It's fair to say that it's based on RDNA2 although some (larger) differences exist.
They just don't matter that much for the endresults and the most important features are included.
Nonetheless it's fasciniting to see how it differs.
It's fair to say that it's based on RDNA2 although some (larger) differences exist.
They just don't matter that much for the endresults and the most important features are included.
Nonetheless it's fasciniting to see how it differs.
• • •
Missing some Tweet in this thread? You can try to
force a refresh