Mean Square Error is one of the most ubiquitous error functions in machine learning.
Did you know that it arises naturally from Bayesian estimation? That seemingly rigid formula has a deep probabilistic meaning.
💡 Let's unravel it! 💡
Did you know that it arises naturally from Bayesian estimation? That seemingly rigid formula has a deep probabilistic meaning.
💡 Let's unravel it! 💡
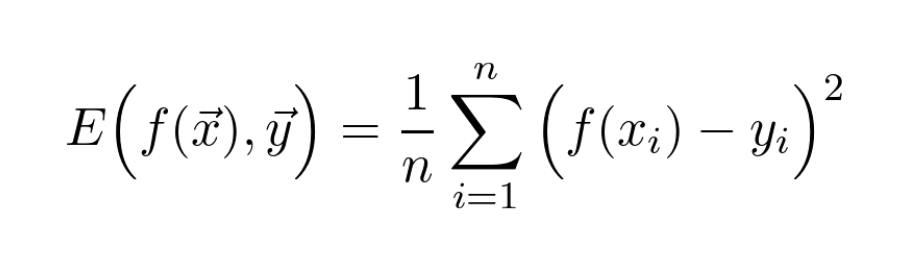
If you are not familiar with the MSE, first check out this awesome explanation by @haltakov!
In the following, we are going to dig deep into the Bayesian roots of the formula!
(
In the following, we are going to dig deep into the Bayesian roots of the formula!
(
https://twitter.com/haltakov/status/1358852194565558276)
Suppose that you have a regression problem, like predicting apartment prices from square foot.
The data seems to follow a clear trend, although the variance is large. Fitting a function could work, but it seems wrong.
The data seems to follow a clear trend, although the variance is large. Fitting a function could work, but it seems wrong.
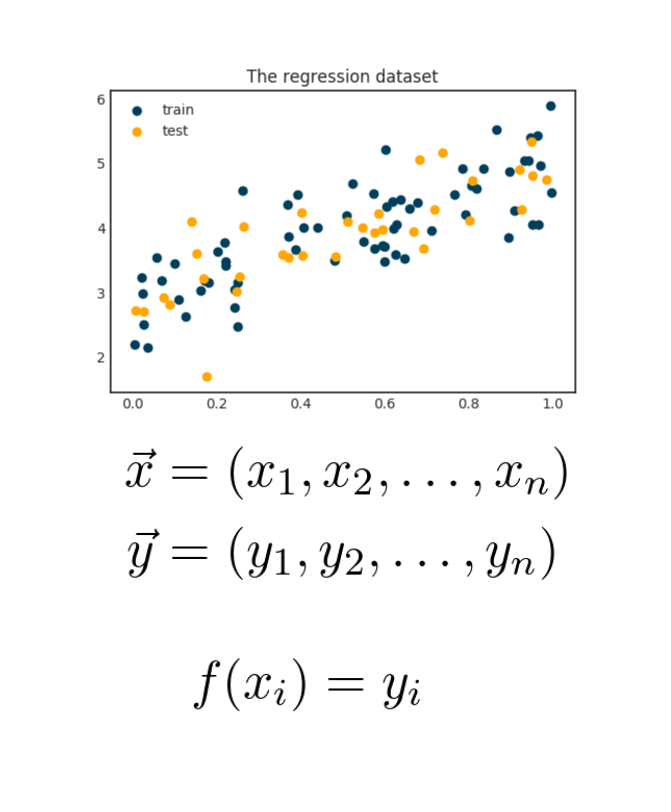
We need a model that can explain the variance of the data, not just its mean. (Unlike a linear regression would.)
💡 Let's model it with probability distributions instead of just a function! 💡
Suppose that both variables we observe are from the distributions 𝑋 and 𝑌.
💡 Let's model it with probability distributions instead of just a function! 💡
Suppose that both variables we observe are from the distributions 𝑋 and 𝑌.
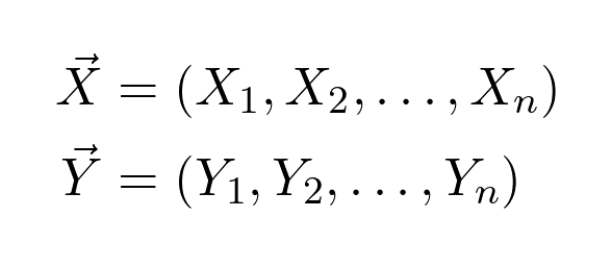
What we are looking for is the conditional distribution of 𝑌, given 𝑋!
This would provide complete information about our data.
How can we find this? 🤔
This would provide complete information about our data.
How can we find this? 🤔
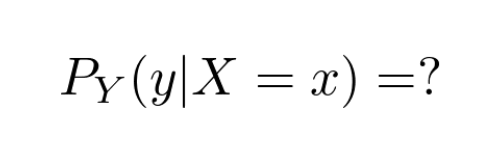
Now it is finally the time to do some modelling!
Let's assume that for each 𝑥, the conditional distributions we are looking for are Gaussians, with the mean as some function of the observations!
Let's assume that for each 𝑥, the conditional distributions we are looking for are Gaussians, with the mean as some function of the observations!
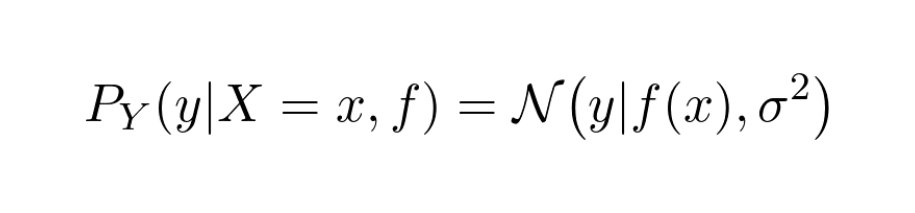
How do we fit our model? 🤔
Think about this. How likely is it that our observation given a parametrized function 𝑓 and 𝑥 is 𝑦?
💡 We want to find the estimator 𝑓 that maximizes the chance! 💡
This quantity is described by the so-called likelihood function.
Think about this. How likely is it that our observation given a parametrized function 𝑓 and 𝑥 is 𝑦?
💡 We want to find the estimator 𝑓 that maximizes the chance! 💡
This quantity is described by the so-called likelihood function.
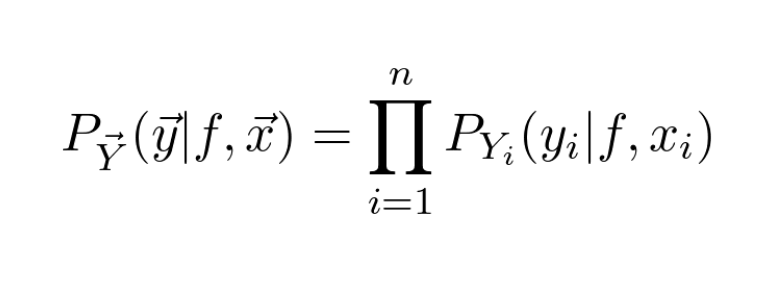
Let's see how can we maximize the likelihood function!
In the first step, we just simply write out the Gaussian density function by hand.
(I encourage you to follow along in the calculations! They might be scary, but you'll get it, I am sure.)
In the first step, we just simply write out the Gaussian density function by hand.
(I encourage you to follow along in the calculations! They might be scary, but you'll get it, I am sure.)
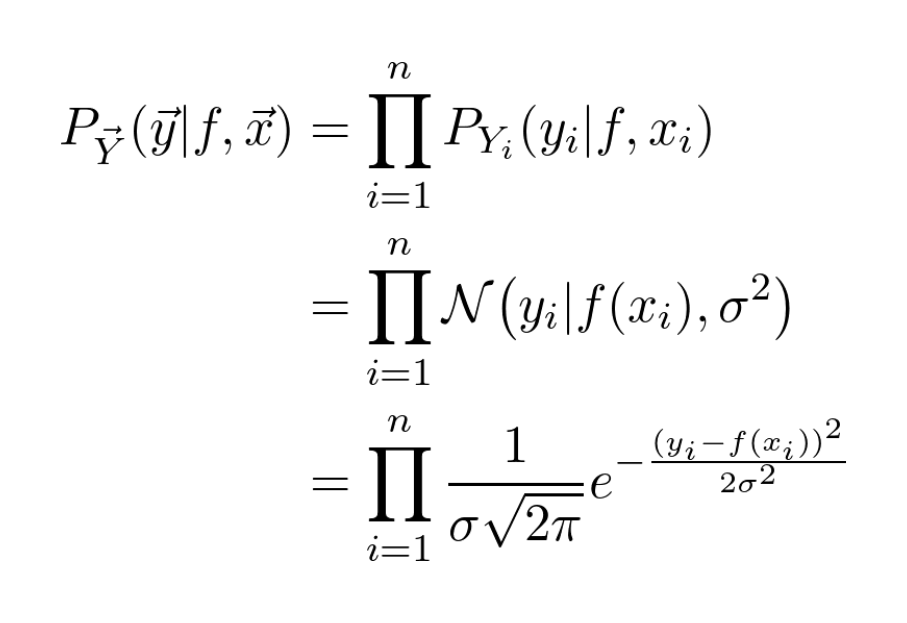
Now we do a neat trick: maximizing a function is the same as maximizing its logarithm. (Since the logarithm is monotone increasing.)
We do this because taking the logarithm turns the product into a nice sum!
We do this because taking the logarithm turns the product into a nice sum!
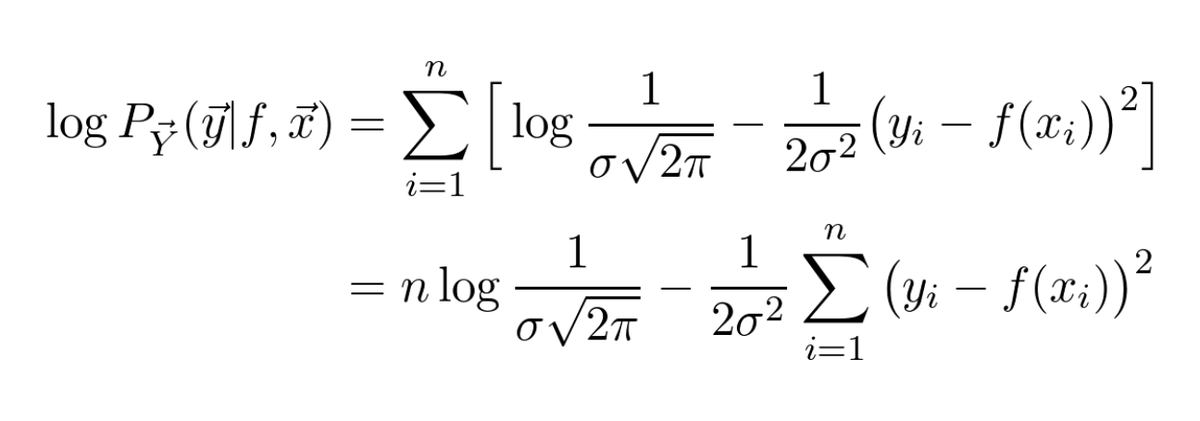
Recall that we want to maximize the above formula in 𝑓.
This means that we can discard a bunch of terms! Practically anything that doesn't contain 𝑓.
In the end, we are left with the one below.
This means that we can discard a bunch of terms! Practically anything that doesn't contain 𝑓.
In the end, we are left with the one below.
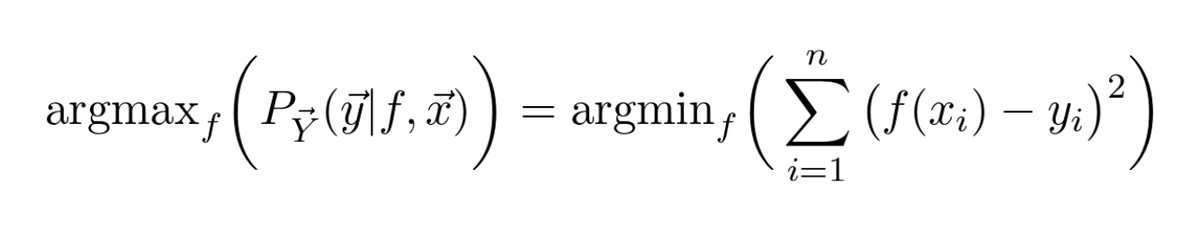
Is the formula on the right familiar?
That is essentially the Mean Square Error!
💡 Thus, fitting a Gaussian model by optimizing the maximum likelihood is the same as minimizing MSE! 💡
In machine learning, probability theory is present everywhere behind the scenes.
That is essentially the Mean Square Error!
💡 Thus, fitting a Gaussian model by optimizing the maximum likelihood is the same as minimizing MSE! 💡
In machine learning, probability theory is present everywhere behind the scenes.
Update! I'll add a small note here to explain why I said that this estimation is Bayesian. I sort of skimmed that one, so here is a short one!
Here, we actually want to estimate the posterior distribution of the model parameters, given all the data.
Here, we actually want to estimate the posterior distribution of the model parameters, given all the data.
According to the Bayes' theorem,
posterior distribution ∝ (likelihood function) x (prior distribution).
In this case, by optimizing the likelihood function, we also optimize the posterior. (The result is called Maximum Posterior, or MAP in short.)
posterior distribution ∝ (likelihood function) x (prior distribution).
In this case, by optimizing the likelihood function, we also optimize the posterior. (The result is called Maximum Posterior, or MAP in short.)
• • •
Missing some Tweet in this thread? You can try to
force a refresh