⚔️ FastNeRF vs NeX ⚔️
Smart ideas do not come in the only head. FastNeRF has the same idea as in NeX, but a bit different implementation. Which one is Faster?
Nex nex-mpi.github.io
FastNeRF arxiv.org/abs/2103.10380
To learn about differences between the two -> thread 👇
Smart ideas do not come in the only head. FastNeRF has the same idea as in NeX, but a bit different implementation. Which one is Faster?
Nex nex-mpi.github.io
FastNeRF arxiv.org/abs/2103.10380
To learn about differences between the two -> thread 👇

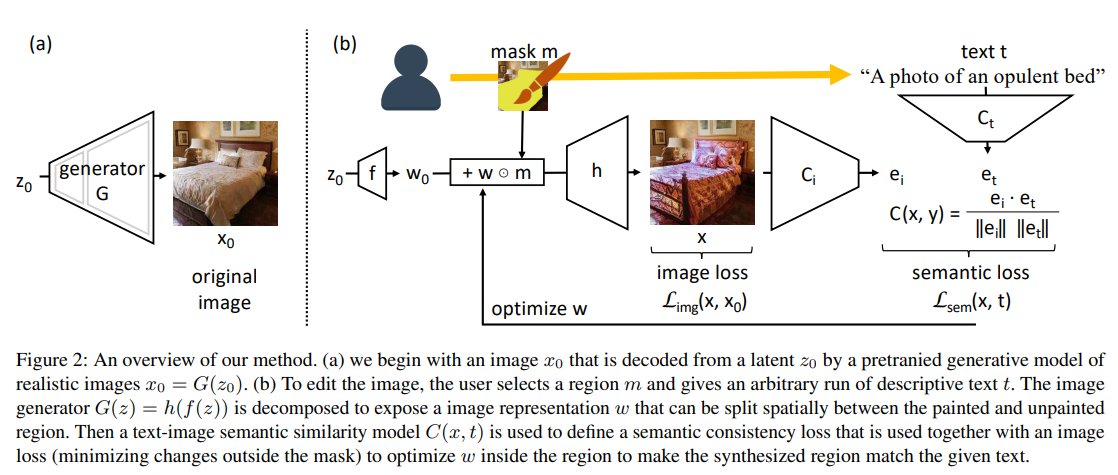
1/ The main idea is to factorize the voxel color representation into two independent components: one that depends only on positions p=(x,y,z) of the voxel and one that depends only on the ray directions v.
Essentially you predict K different (R,G,B) values for ever voxel...
Essentially you predict K different (R,G,B) values for ever voxel...
2/ Essentially you predict K different (R,G,B) values for ever voxel and K weighting scalars H_i(v) for each of them:
color(x,y,z) = RGB_1 * H_1 + RGB_2 * H_2 + ... + RGB_K * H_K. This is inspired by the rendering equation.
...
color(x,y,z) = RGB_1 * H_1 + RGB_2 * H_2 + ... + RGB_K * H_K. This is inspired by the rendering equation.
...
https://twitter.com/artsiom_s/status/1373464655935471616?s=20
3/ Then 2 neural networks f(x,y,z) = [RGB_1, ... RGB_K] and h(v) = [H1, .. H_K] are learn to predict color components an their weights. After that the values of these functions are cached for every voxel in the volume which enables swift online rendering.
...
...
4/ Now ⚔️ NeX(➖) vs FastNeRF(➕):
➖NeX achieves ~60Fps and PSNR 27 on the Real Forward-Facing dataset using Nvidia 2080Ti . While FastNeRF - 50-80 fps and PSNR 26 using RTX 3090 GPU, fps rate varies from scene to scene. 200fps is only achieved on synthetic datasets or lower res
➖NeX achieves ~60Fps and PSNR 27 on the Real Forward-Facing dataset using Nvidia 2080Ti . While FastNeRF - 50-80 fps and PSNR 26 using RTX 3090 GPU, fps rate varies from scene to scene. 200fps is only achieved on synthetic datasets or lower res
5/
➖FastNeRF requires a bit more memory to cache their scene representation because NeX uses sparse representation along the depth direction (only 192 slices) and share RGB_i values between every 12 consecutive depth planes.
➖FastNeRF requires a bit more memory to cache their scene representation because NeX uses sparse representation along the depth direction (only 192 slices) and share RGB_i values between every 12 consecutive depth planes.
6/
➖ The same idea - factorize color representation. Predict K RGB values for every voxel and their weights instead of a single RGB.
➕FastNeRF attempted to justify such factorization by the Rendering equation (see the image above for an intuitive explanation).
...
➖ The same idea - factorize color representation. Predict K RGB values for every voxel and their weights instead of a single RGB.
➕FastNeRF attempted to justify such factorization by the Rendering equation (see the image above for an intuitive explanation).
...
7/
➕ Very similar architecture. NeX has one extra learnable Tensor which represents average RGB colors independent of ray direction. All other components are learned by neural networks. FastNeRF learns everything with neural nets.
...
➕ Very similar architecture. NeX has one extra learnable Tensor which represents average RGB colors independent of ray direction. All other components are learned by neural networks. FastNeRF learns everything with neural nets.
...
8/➖ NeX has more extensive experiments and also experiments on fixed basis functions (i.e., compute H_i(v) using the Fourier’s series, spherical harmonics, etc). Interestingly, using the Fourier's series instead of neural network g(v) yields only a slightly worse PSNR score...
9/ ... and even better LPIPS score.
➖ NeX introduces and evaluated on more challenging Shiny objects dataset. Would be interesting to see the results on FastNeRF on the same dataset as well.
...
➖ NeX introduces and evaluated on more challenging Shiny objects dataset. Would be interesting to see the results on FastNeRF on the same dataset as well.
...
❗️👉 Overall, I would say the approaches are very similar with some minor implementation differences. One would need to combine both implementations to get the best result.
Checkout full comparison NeX vs FastNrRF in my telegram channel t.me/gradientdude/2…
Checkout full comparison NeX vs FastNrRF in my telegram channel t.me/gradientdude/2…
• • •
Missing some Tweet in this thread? You can try to
force a refresh