
🔥New DALL-E? Paint by Word 🔥
Edit a generated image by painting a mask atany location of the image and specifying any text description. Or generate a full image just based on textual input.
📝arxiv.org/abs/2103.10951
1/
Edit a generated image by painting a mask atany location of the image and specifying any text description. Or generate a full image just based on textual input.
📝arxiv.org/abs/2103.10951
1/

2/ Point to a location in a synthesized image and apply an arbitrary new concept such as “rustic” or “opulent” or “happy dog.”

3/
🛠️Two nets:
(1) a semantic similarity network C(x, t) that scores the semantic consistency between an image x and a text description t. It consists of two subnetworks: C_i(x) which embeds images and C_t(t) which embeds text.
(2) generative network G(z) that is trained to ...
🛠️Two nets:
(1) a semantic similarity network C(x, t) that scores the semantic consistency between an image x and a text description t. It consists of two subnetworks: C_i(x) which embeds images and C_t(t) which embeds text.
(2) generative network G(z) that is trained to ...
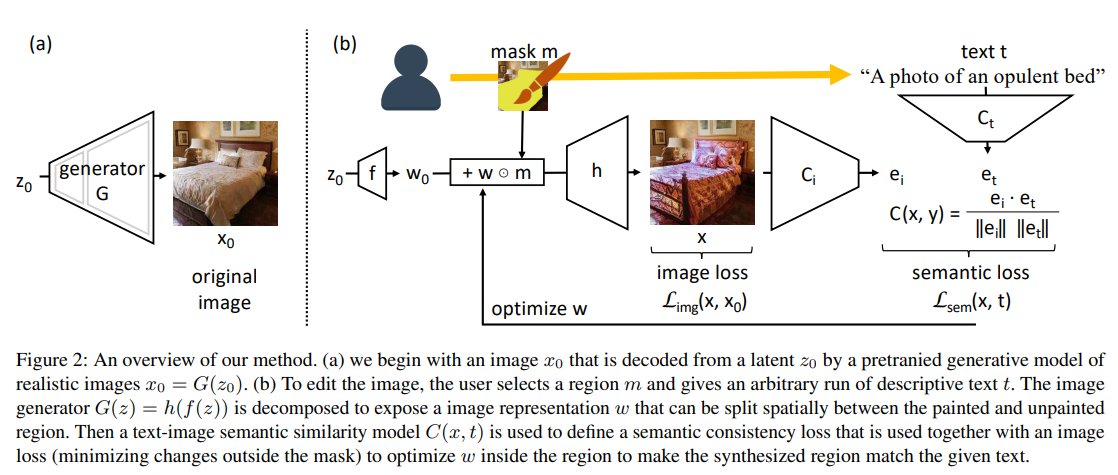
4/ ...to synthesize realistic images given a random z; this network enforces realism.
We generate a realistic image G(z) that matches descriptive text t by optimizing:
z∗ = arg min_z L_sem(z) = arg min_z C(G(z), t)
We generate a realistic image G(z) that matches descriptive text t by optimizing:
z∗ = arg min_z L_sem(z) = arg min_z C(G(z), t)

5/
To focus on changes in a local area, we direct the matching network C to attend to only the region of the user’s brushstroke instead of the whole image. To do this we extract the latent representation w=f(z) of the image and ...
To focus on changes in a local area, we direct the matching network C to attend to only the region of the user’s brushstroke instead of the whole image. To do this we extract the latent representation w=f(z) of the image and ...

6/ ... and mask it using the user's input and optimize only the masked region of the representation. To match the input textual description: we embed the output image and the text using networks C_i(x) and C_t(t) and maximize the similarity between these embeddings ...

7/ ...by backpropagating the gradients to the masked latent representation w.
Here is the loss ablation study. Mask the outout image vs mask the latent representation for backprop.
Here is the loss ablation study. Mask the outout image vs mask the latent representation for backprop.

8/
Full image generation:
"Paint by Word" ⚔️vs DALL-E
The poposed method has a simpler architecturethan DALL-E and it does not explicitly train the generator to take textual description as inpu to the generatort. The textual information comes only from the semantic loss.
Full image generation:
"Paint by Word" ⚔️vs DALL-E
The poposed method has a simpler architecturethan DALL-E and it does not explicitly train the generator to take textual description as inpu to the generatort. The textual information comes only from the semantic loss.
9/
For G authors train a 256-pixel StyleGAN2 on CUB dataset. And for C(x, t) authors use use an off the-shelf CLIP model.
The network is trained only on birds and it utterly fails to draw any other type of subject. Because of this narrow focus, it is unsurprising ...
For G authors train a 256-pixel StyleGAN2 on CUB dataset. And for C(x, t) authors use use an off the-shelf CLIP model.
The network is trained only on birds and it utterly fails to draw any other type of subject. Because of this narrow focus, it is unsurprising ...

10/
that it might be better at drawing realistic bird images than the DALL-E model, which is trained on a far broader variety of unconstrained images. Nevertheless, this experiment demonstrates that it is possible to obtain state-of-the-art semantic consistency, ...
that it might be better at drawing realistic bird images than the DALL-E model, which is trained on a far broader variety of unconstrained images. Nevertheless, this experiment demonstrates that it is possible to obtain state-of-the-art semantic consistency, ...

11/
at least within a narrow image domain, without explicitly training the generator to take information
about the textual concept as input.
More resutls when trained generator G(z) on ImageNet or Places:
at least within a narrow image domain, without explicitly training the generator to take information
about the textual concept as input.
More resutls when trained generator G(z) on ImageNet or Places:

12/
☑️To conclude, this paper shows that even such a simple method can produce pretty amazing results.
🔥Just train your styleGAN / BigGAN generator and then to edit an image region just optimize the masked latent code using pretrained CLIP as a loss. That's it!
☑️To conclude, this paper shows that even such a simple method can produce pretty amazing results.
🔥Just train your styleGAN / BigGAN generator and then to edit an image region just optimize the masked latent code using pretrained CLIP as a loss. That's it!
Subscribe to my Telegram channel not to miss other novel paper reviews like this! 😉
t.me/gradientdude
t.me/gradientdude
@threadreaderapp unroll
P.S. The full mage generation with BigGAN is very similar to #BigSleep and here is the colab notebook that can guide BigGAN generation using CLIP 👇
https://twitter.com/advadnoun/status/1351038053033406468?s=20
I wrote a blogpost based on this thread
https://twitter.com/artsiom_s/status/1374683007928442885?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh







