
Melihat COVID-19 vaccine efficacy secara sederhana
Implementasi dasar Bayesian inference
.
.
.
A thread
Implementasi dasar Bayesian inference
.
.
.
A thread
Di thread kali ini, yuk kita bahas gimana cara mengestimasi efek dari vaksin secara keseluruhan. Nah, ini baru kita bakal mulai pake Bayesian inference. Apa tuh Bayesian inference? Kok bayes ada di mana-mana, sih? 

Sebelum memulai thread, disclaimer dlu nih! Data yang kita gunakan itu data yang masih belum lengkap, sehingga kesimpulan dari thread ini bisa jadi belum akurat. Kita bakal fokus ke gimana caranya mengimplementasikan Bayesian inference di kasus vaksin COVID-19 saja, ya!
Jadi, si Bayesian inference ini tuh metode inferensi statistik yang make teorema Bayes buat memperbarui probabilitas hipotesis saat lebih banyak bukti atau informasi tersedia. Nah kenapa sih kita pake Bayesian inference ini? 🤔
Informasi data vaksin COVID-19 itu akan terus bertambah dan berkembang seiring berjalannya waktu. Jadi, pemodelan bakal terus dilakukan berulang kali supaya distribusinya sesuai dengan data yang ada.
Nah, bayes ini bisa bantu kita buat memperbarui probabilitas kalo data yang kita punya makin banyak.
Sebelumnya, pasti udah pada tau teorema bayes, kan? Atau belum? Kalo belum, yuk baca thread kita sebelumnya tentang Bayesian!
https://twitter.com/pacmannai/status/1375055183709831171

Jadi kalau teorema bayes diaplikasikan jadi bayes inference, kurang lebih bakal jadi begini. Pusing? Sama! Yuk kita kupas bareng bareng.

Misalnya kita punya sejumlah orang yang sudah vaksinasi. Dari orang-orang yang telah divaksin itu, ada yang tidak sakit (kebal) dan ada yang tetap sakit karena virus COVID-19.
Nah, kita mau liat estimasi berapa persen sih orang yang kebal virus jika kita terus memberikan vaksin kedepannya?
Kalau dilihat dari kejadian itu, kita punya dua kejadian, nih: vaksin berhasil dan vaksin gagal. kita bakal asumsikan data berbentuk biner dengan 1: vaksin berhasil dan 0: vaksin gagal. Jadi, kejadian vaksin bakal mengikuti distribusi Bernoulli.

Nah untuk menggunakan Bayesian inference untuk memodelkan efek vaksin ini, kita perlu ngerti dulu nih terkait si Bayesian inference itu sendiri.
Bayesian inference ini terdiri dari tiga tahap: menentukan prior model, menentukan likelihood model, dan menentukan posterior model maksimal.
Inti dari prior probability itu kita bakal cari distribusi dari kemungkinan suatu kejadian sebelum kita melihat datanya (X). Kalau kasus kita, berarti prior itu distribusi kemungkinan vaksin tersebut sukses berdasarkan apa yang kita tahu (masih kita tebak, nih).

Untuk fungsi likelihood, sederhananya itu kita bakal memodelkan gimana data real (X) bakal terlihat kalau kejadian yang terjadi adalah vaksin berhasil.

Kebalikan dari prior, posterior model itu distribusi kemungkinan dari suatu kejadian setelah kita melihat data realnya.
Di kasus ini berarti kemungkinan vaksin berhasil setelah kita melihat data vaksinasi. Nanti kemungkinan vaksin berhasil yang kita pilih itu adalah yang punya posterior terbesar.

Nah, biar hidup jadi mudah, kita bakal pake distribusi dari prior probability yang bisa menghasilkan posterior dist berupa conjugate prior.
Waduh, apaan lagi tuh conjugate prior? Si conjugate prior ini tuh posterior yang punya distribusi sama kayak priornya. Kenapa tuh harus begitu?
Sederhananya, kita tuh bakal nyari posterior buat setiap kemungkinan vaksin bakal berhasil, terus liat posterior yang paling maksimum. Buat nyari maksimum posterior, kita harus normalize semua likelihood dan prior distributionnya. Intinya: pusing, euy!
Jadinya, supaya kita ga perlu normal-normalin, kita bakal pake teori yang udah ada bahwa distribusi beta itu merupakan conjugate prior dan Bernoulli likelihood. Jadi, Bayesian inference kita bakal berbentuk begini:

Udah cukup pusing? Kalo udah berarti tandanya kita harus langsung aja ke praktek nih, hehe. Kita bakal gunain data dari blog.fellstat.com.


Terus, kita bakal jelasin model dari prior (dist beta) sama likelihood (dist Bernoulli) dari setiap jenis vaksin, kurang lebih begini:
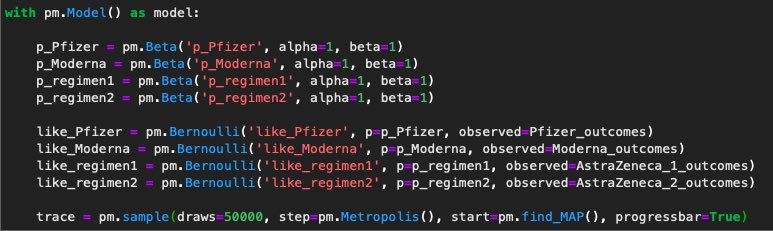
Nah, setelah itu kita bisa liat plot gabungan dari vaccine efficacy untuk tiap jenis vaksin.

Kalau kita lihat, posterior distribution yang ada di gambar ini itu adalah maksimum posterior distribution (berdistribusi beta). Akhirnya, kita jadi bisa liat vaksin efficacy dari setiap jenis vaksin, deh!

Buat pengingat lagi, data yang kita pake itu masih belum komplit, jadi kesimpulan yang diambil dari posterior distribution yang kita buat ini masih belum bisa merepresentasikan kebenaran dari vaccine efficacy, ya!
Yang penting, sekarang kita udah tau gimana cara ngemodelin Bayesian inference, kan? 😁
Pengen lanjut belajar, tapi bingung dan penasaran apa kegunaan Bayesian di machine learning? Yuk belajar bareng mimin di non degree program Data Scientistnya Pacmann.AI. 😎
Pendaftaran batch 3 udah dibuka loh, langsung aja daftarin diri kalian di bit.ly/PendaftaranNon… 🤩🤩🤩
Oh ya, lagi ada promo potongan 💸 Early Bird 💸 juga loh buat kalian yang daftar sekarang juga hingga Jumat, 2 April 2021! Kalau mau tahu info lebih lanjut tentang Program Non-Degree nya, bisa langsung klik bit.ly/BrosurSingkatP… atau hubungi kami di bit.ly/WASalesPacmann ya😊

Sumber:
arxiv.org/pdf/2103.05499…
towardsdatascience.com/a-bayesian-mod…
towardsdatascience.com/conjugate-prio…
arxiv.org/pdf/2103.05499…
towardsdatascience.com/a-bayesian-mod…
towardsdatascience.com/conjugate-prio…
• • •
Missing some Tweet in this thread? You can try to
force a refresh




