⚡️ Expresiones regulares (REGEX) ⚡️
En el🧵de hoy, te voy a enseñar algunas expresiones regulares simples para que puedas empezar a usarlas ya. Ahorrán mucho tiempo, y dominar algunas te ayudará.
No para posicionar, pero para trabajar de manera más eficiente.
En el🧵de hoy, te voy a enseñar algunas expresiones regulares simples para que puedas empezar a usarlas ya. Ahorrán mucho tiempo, y dominar algunas te ayudará.
No para posicionar, pero para trabajar de manera más eficiente.
🤷♂️¿Que son las expresiones regulares (REGEX)? 🤷♂️
Sirven para describir cadenas de texto, números y caracteres especiales con el fin de buscarlas o manipularlas.
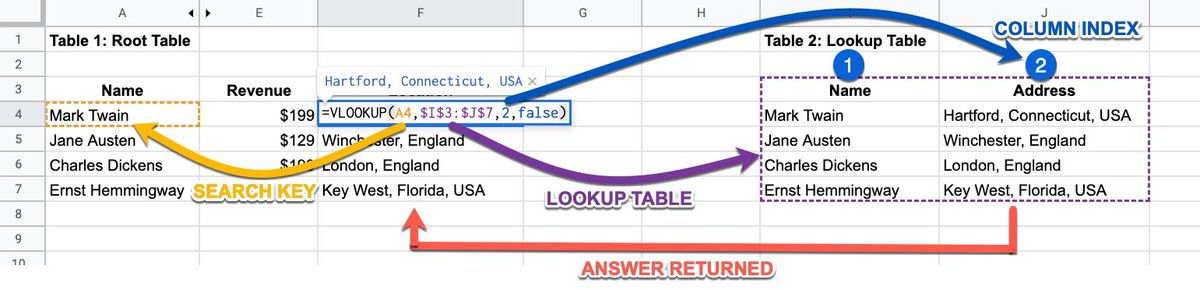
Se pueden usar en la gran mayoría de las herramientas, como por ejemplo Sheets:
Sirven para describir cadenas de texto, números y caracteres especiales con el fin de buscarlas o manipularlas.
Se pueden usar en la gran mayoría de las herramientas, como por ejemplo Sheets:
https://twitter.com/antoineripret/status/1373961375714844675
Las REGEX pueden asustar, pero te voy a detallar cuáles son las más comunes y qué hacen.
Usaré regex101.com en mi pantallazos, que te permite validar tus REGEX de manera sencilla.
Usaré regex101.com en mi pantallazos, que te permite validar tus REGEX de manera sencilla.
1. Punto (.)
Representa cualquier carácter.
Representa cualquier carácter.

2. Estrella (*)
Indica que el elemento al que sigue se puede repetir 0 o más veces. Si lo combinamos con el punto, significa "cualquier cadena".
Similar: el más (+) que indica 1 o más veces.
Indica que el elemento al que sigue se puede repetir 0 o más veces. Si lo combinamos con el punto, significa "cualquier cadena".
Similar: el más (+) que indica 1 o más veces.
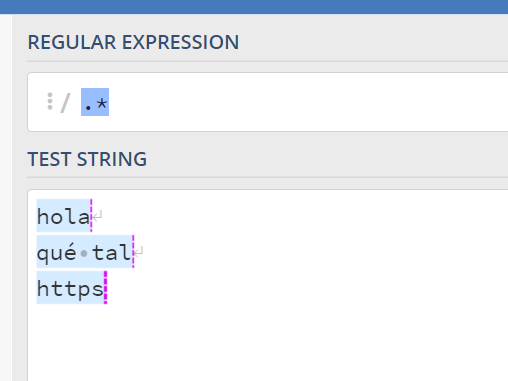
3. Barra vertical (|)
Significa OR. Permite indicar varios valores que puedes estar buscando.
En mis ejemplo, ves que la segunda opción no coincide con mi REGEX porque la extensión (co.uk) no está dentro de mis opciones.
Significa OR. Permite indicar varios valores que puedes estar buscando.
En mis ejemplo, ves que la segunda opción no coincide con mi REGEX porque la extensión (co.uk) no está dentro de mis opciones.

4. Barra invetida (\)
Permite "escapar" un carácter para que se interprete literalmente (no con su significado REGEX).
En mi ejemplo, escapo el punto: quiero un punto sí o sí.
Permite "escapar" un carácter para que se interprete literalmente (no con su significado REGEX).
En mi ejemplo, escapo el punto: quiero un punto sí o sí.

5. Signo de interrogación (?)
Indica que el elemento al que sigue es opcional.
En mi ejemplo, la barra final es opcional, por lo tanto mi REGEX coincide tanto con el primer texto como el tercero.
Indica que el elemento al que sigue es opcional.
En mi ejemplo, la barra final es opcional, por lo tanto mi REGEX coincide tanto con el primer texto como el tercero.

6. Barra invertida + d (\d)
Indica un carácter númerico.
Si lo combiamos con +, indicamos que queremos una cadena de 1 o varios dígitos.
Indica un carácter númerico.
Si lo combiamos con +, indicamos que queremos una cadena de 1 o varios dígitos.

7. [a-z]
Indica una letra (minúscula).
* si quieremos una letra mayúscula, tenemos que usar [A-Z]
* si queremos una letra mayúscula o minúscula, tenemos que usar [a-zA-Z]
Indica una letra (minúscula).
* si quieremos una letra mayúscula, tenemos que usar [A-Z]
* si queremos una letra mayúscula o minúscula, tenemos que usar [a-zA-Z]

8. {número}
Indica que el elemento al que sigue se repite X veces.
Por ejemplo, si buscamos una URL con 3 números:
Indica que el elemento al que sigue se repite X veces.
Por ejemplo, si buscamos una URL con 3 números:
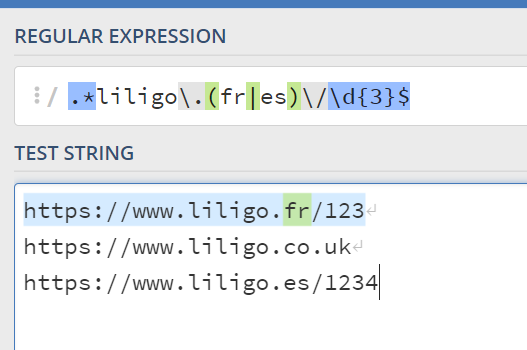
** Caso práctico **
Aplicamos todo lo que acabamos de aprender. Tengo tres URLs y quiero capturar los dígitos situado al final de las URLs, si se trata del blog.
No puedo usar \d+ porque capturaría también el número si el contenido no pertenece al blog 🤔
Aplicamos todo lo que acabamos de aprender. Tengo tres URLs y quiero capturar los dígitos situado al final de las URLs, si se trata del blog.
No puedo usar \d+ porque capturaría también el número si el contenido no pertenece al blog 🤔

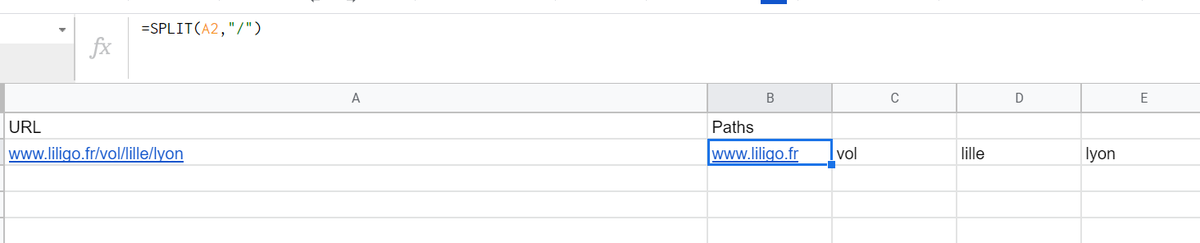
Si modificamos un poco nuestra REGEX, podemos capturar lo que nos interesa.
.* : lo que sea
liligo\.(fr|es): liligo.fr o liligo.es
\/blog\/: carpeta blog
[a-z-]+: palabras separadas por un -
(\d+)\: lo que queremos (por eso usamos paréntesis)
.* : lo que sea
liligo\.(fr|es): liligo.fr o liligo.es
\/blog\/: carpeta blog
[a-z-]+: palabras separadas por un -
(\d+)\: lo que queremos (por eso usamos paréntesis)

¿Te parece complicado?
Es normal, al inicio aprender las REGEX cuesta . Usa regex101.com para practicar y irás mejorando poco a poco.
Y podrás trabajar de manera más eficiente ⚡️
Es normal, al inicio aprender las REGEX cuesta . Usa regex101.com para practicar y irás mejorando poco a poco.
Y podrás trabajar de manera más eficiente ⚡️
• • •
Missing some Tweet in this thread? You can try to
force a refresh