🐸 ¿Cómo extraer contenido? 🐸
En el 🧵de hoy, te voy a dar todas las opciones que existen (y que conozco) para poder extraer contenido de una web.
Como SEO, parte de nuestra trabajo es extraer información de sitios (nuestros o ajenos).
En el 🧵de hoy, te voy a dar todas las opciones que existen (y que conozco) para poder extraer contenido de una web.
Como SEO, parte de nuestra trabajo es extraer información de sitios (nuestros o ajenos).
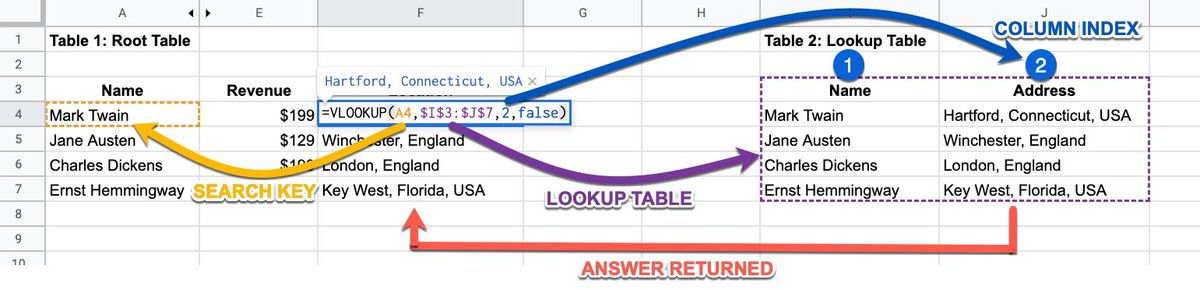
Si quieres obtener información de una página, lo más simple es que uses esta extensión: chrome.google.com/webstore/detai…
Te permite extraer elementos similares en muy poco tiempo.
Te permite extraer elementos similares en muy poco tiempo.

Si no dominas Xpath, te aconsejo echar un vistazo a:
* builtvisible.com/seo-guide-to-x…
* mjcachon.com/blog/expresion… de @mjcachon
* builtvisible.com/seo-guide-to-x…
* mjcachon.com/blog/expresion… de @mjcachon
Si necesitas extraer información de muchas páginas, existen varias opciones.
1. Screaming Frog
No hace falta que presente la 🐸. Cuenta con una funcionalidad de "Custom Extraction" que está muy documentada: screamingfrog.co.uk/web-scraping/
1. Screaming Frog
No hace falta que presente la 🐸. Cuenta con una funcionalidad de "Custom Extraction" que está muy documentada: screamingfrog.co.uk/web-scraping/

Ten en cuenta que puedes usarla para portales que usan un formulario de acceso / contraseña: screamingfrog.co.uk/crawling-passw…
Una funcionalidad no tan conocida pero que es muy útil.
Una funcionalidad no tan conocida pero que es muy útil.

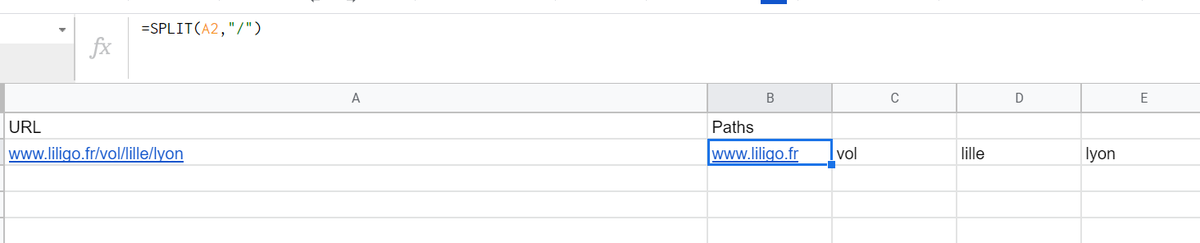
2. Google Sheets
Google cuenta con una funcionalidad para extraer información: IMPORTXML. Pero:
* funciona únicamente con Xpath
* falla bastante
* si tienes muchas URLs, mejor usar workspace.google.com/marketplace/ap…
Google cuenta con una funcionalidad para extraer información: IMPORTXML. Pero:
* funciona únicamente con Xpath
* falla bastante
* si tienes muchas URLs, mejor usar workspace.google.com/marketplace/ap…

También puedes crear tu propio código JS para crear nueva funcionalidades de extracción.
Algunos ejemplos: github.com/NachoSEO/SEO-f… que ha compartido @NachoMascort
Algunos ejemplos: github.com/NachoSEO/SEO-f… que ha compartido @NachoMascort
Deberías cubrir la mayoría de tus casos de uso con estas opciones. Sin embargo, hay situaciones más complejas.
Por ejemplo:
* Extraer datos de portales muy protegidos como Google o Amazon
* Extraer datos con lógicas complejas
Seguimos ⬇️⬇️
Por ejemplo:
* Extraer datos de portales muy protegidos como Google o Amazon
* Extraer datos con lógicas complejas
Seguimos ⬇️⬇️
1. Reducir la velocidad
Puedes reducir la velocidad de Screaming Frog por ejemplo.
Puedes extraer datos de Google siguiendo lo que explica @carlos_darko en carlosortega.page/como-detectar-….
Guay, pero cuando tienes 50.000 URLs, es un poco frustrante.
Puedes reducir la velocidad de Screaming Frog por ejemplo.
Puedes extraer datos de Google siguiendo lo que explica @carlos_darko en carlosortega.page/como-detectar-….
Guay, pero cuando tienes 50.000 URLs, es un poco frustrante.

2. Usar APIs
Servicios como scaleserp.com, scrapingbee.com o nodatanobusiness.com (mencionando los que conozco y he usado) os permiten extraer datos más rápido.
Usan proxies etc... para evitar el bloqueo. Además, ¡soportan el rendering JS!
Servicios como scaleserp.com, scrapingbee.com o nodatanobusiness.com (mencionando los que conozco y he usado) os permiten extraer datos más rápido.
Usan proxies etc... para evitar el bloqueo. Además, ¡soportan el rendering JS!
3. Usar Requests (Python)
Puedes también usar requests (docs.python-requests.org/en/master/) para extraer datos.
Gran ventaja: permite configurar las cabeceras HTTP, funcionalidad que puede ser indispensable para acceder a algunas secciones.
Existen equivalentes en otros lenguajes.
Puedes también usar requests (docs.python-requests.org/en/master/) para extraer datos.
Gran ventaja: permite configurar las cabeceras HTTP, funcionalidad que puede ser indispensable para acceder a algunas secciones.
Existen equivalentes en otros lenguajes.

Si lo usas y no sabes qué cabeceras usar:
* puedes usar copiar tus cabeceras en Chrome
* la siguiente configuración funciona casi siempre
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
* puedes usar copiar tus cabeceras en Chrome
* la siguiente configuración funciona casi siempre
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'

Como se integra en Python, permite agregar lógicas complejas de extracción también (condiciones).
Tengo un script hecho para extraer datos en pagesjaunes.fr (páginas amarillas francesas) que no podría hacerse en Screaming Frog.
Tengo un script hecho para extraer datos en pagesjaunes.fr (páginas amarillas francesas) que no podría hacerse en Screaming Frog.
4. Usar Selenium (Python)
Estoy ahora mismo usando Selenium (selenium-python.readthedocs.io) para un estudio que quiero hacer (
En pocas líneas, implemento una lógica imposible de montar de otra manera (porque Amazon, eBay protegen bastante sus datos).
Estoy ahora mismo usando Selenium (selenium-python.readthedocs.io) para un estudio que quiero hacer (
https://twitter.com/antoineripret/status/1389194273460002819).
En pocas líneas, implemento una lógica imposible de montar de otra manera (porque Amazon, eBay protegen bastante sus datos).

Extraer datos:
* es parte del trabajo
* te permite extraer más información de tu competencia
* te permite hasta montar negocios (sí sí, tengo uno en curso así)
* es parte del trabajo
* te permite extraer más información de tu competencia
* te permite hasta montar negocios (sí sí, tengo uno en curso así)
¿Hay programas / técnicas que usas bastante que no aparecen en este hilo? ¡Avísame!
Me encanta descubrir nuevos métodos para trabajar mejor 🤓
Me encanta descubrir nuevos métodos para trabajar mejor 🤓
• • •
Missing some Tweet in this thread? You can try to
force a refresh