VICReg: Variance-Invariance-Covariance Regularization for Self-Supervised Learning.
By Adrien Bardes, Jean Ponce, and yours truly.
arxiv.org/abs/2105.04906
Insanely simple and effective method for self-supervised training of joint-embedding architectures (e.g. Siamese nets).
1/N
By Adrien Bardes, Jean Ponce, and yours truly.
arxiv.org/abs/2105.04906
Insanely simple and effective method for self-supervised training of joint-embedding architectures (e.g. Siamese nets).
1/N
TL;DR: Joint-embedding archis (JEA) are composed of 2 trainable models Gx(x) and Gy(y), trained with pairs of "compatible" inputs (x,y).
For ex: x and y are distorted versions of the same image, successive sequences of video frames.
The main difficulty is to prevent collapse
2/N
For ex: x and y are distorted versions of the same image, successive sequences of video frames.
The main difficulty is to prevent collapse
2/N
VICReg is a loss for JAE with 3 terms:
1. Variance: Hinge loss to maintain the std-dev of each component of Gx(x) & Gy(y) above a margin
2. Invariance: ||Gx(x)-Gy(y)||^2
3. Covariance: sum of the squares of the off-diag terms of the covariance matrices of Gx(x) and Gy(y).
3/N
1. Variance: Hinge loss to maintain the std-dev of each component of Gx(x) & Gy(y) above a margin
2. Invariance: ||Gx(x)-Gy(y)||^2
3. Covariance: sum of the squares of the off-diag terms of the covariance matrices of Gx(x) and Gy(y).
3/N
#1 is the innovation in VICReg.
#2 is classical.
#3 is inspired by Barlow Twins: It pulls up the information content of the embedding vectors by decorrelating their components.
4/N
#2 is classical.
#3 is inspired by Barlow Twins: It pulls up the information content of the embedding vectors by decorrelating their components.
4/N

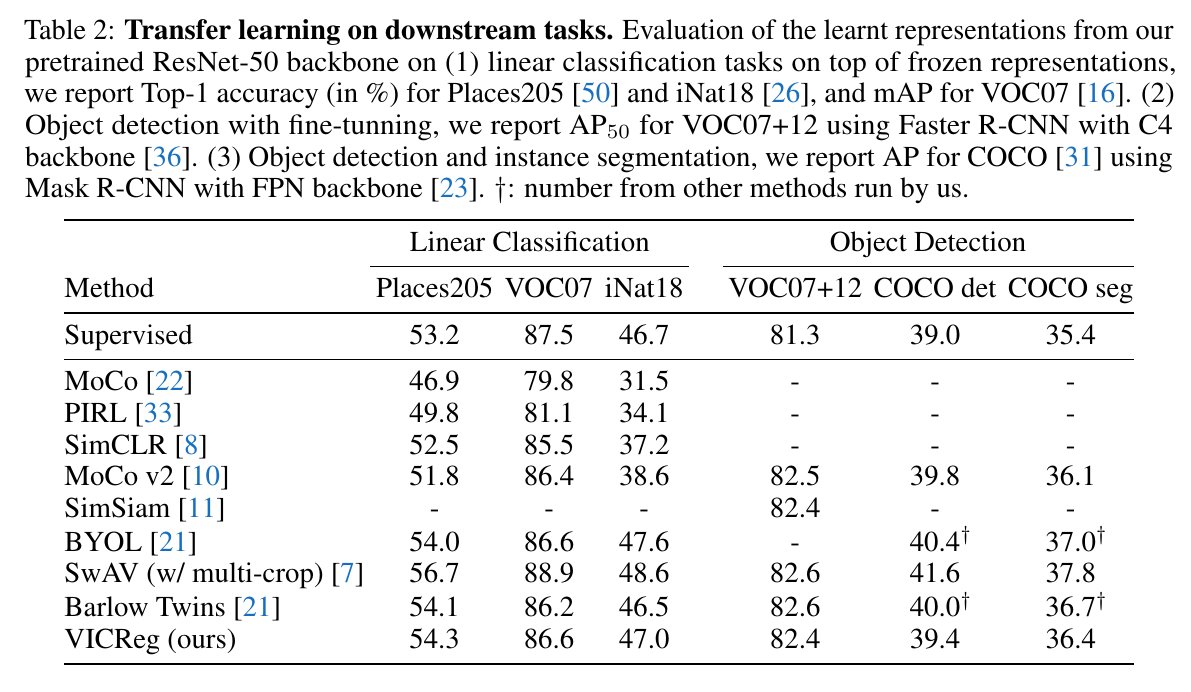
Competitive results on ImageNet with linear classifier head, on transfer tasks, and on semi-supervised ImageNet in the low-data regime. Essentially on par with BYOL, Barlow Twins. slightly above SwAV without multicrop, and slightly below SwAV with multicrop.
6/N
6/N

Results on transfer tasks.
7/N
7/N
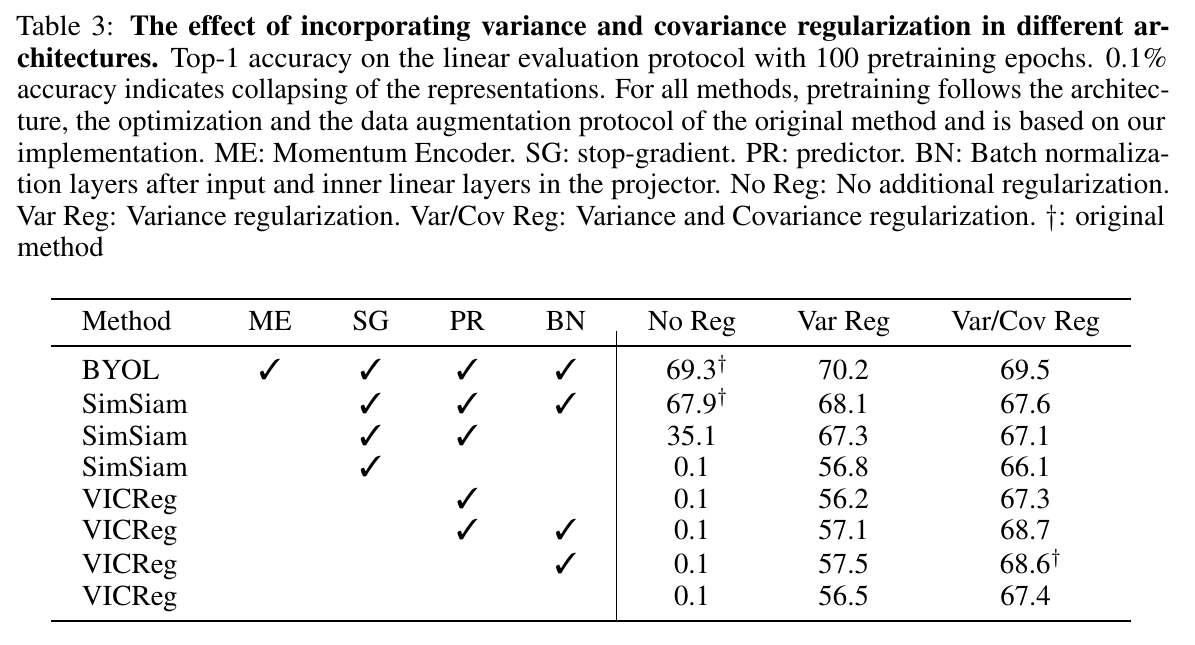
The hinge-on-variance term prevents collapse and alleviates the need for batch-norm or a predictor when added to methods such as SimSiam.
8/N
8/N
Pytorch pseudocode:
9/N
9/N

Main features:
- Super-simple method with well-controlled collapse prevention (see PyTorch pseudo-code) through the hinge loss.
- No need for batch-wise or channel-wise normalization (though it helps a bit).
10/N
- Super-simple method with well-controlled collapse prevention (see PyTorch pseudo-code) through the hinge loss.
- No need for batch-wise or channel-wise normalization (though it helps a bit).
10/N
- No need for shared weights between the 2 branches, although in our experiments, the weights are shared.
- No need for moving-averaged weights, stop-gradient, predictor, negative mining (it's non contrastive!), memory banks, nearest neighbor, nor quantization/distillation.
11/N
- No need for moving-averaged weights, stop-gradient, predictor, negative mining (it's non contrastive!), memory banks, nearest neighbor, nor quantization/distillation.
11/N
Adrien Bardes is a resident PhD student at FAIR-Paris & Inria/ENS, co-advised by Jean Ponce (Inria/ENS) and myself (FAIR/NYU).
12/N
N=12.
12/N
N=12.
• • •
Missing some Tweet in this thread? You can try to
force a refresh