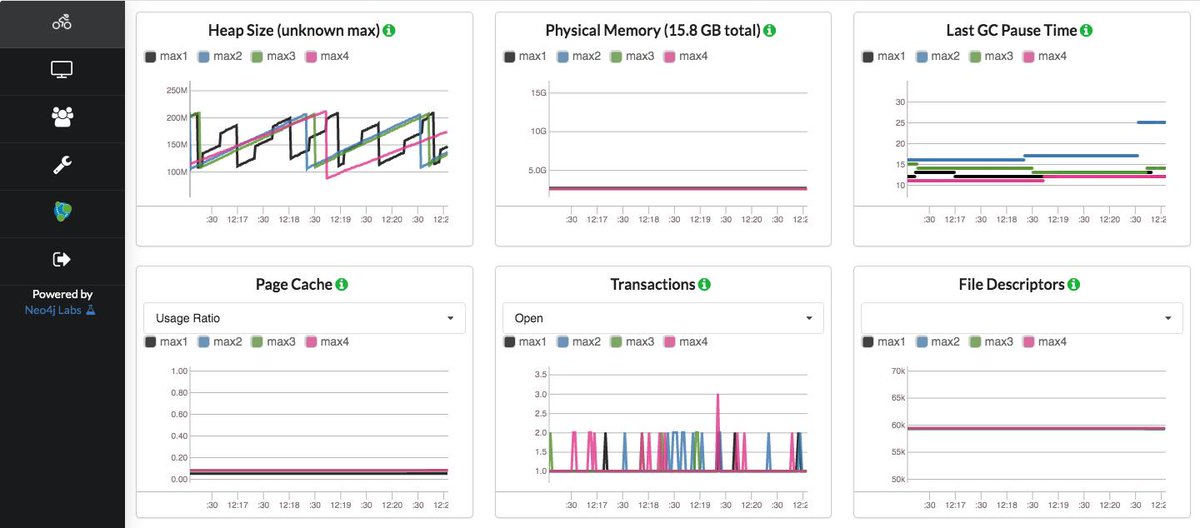
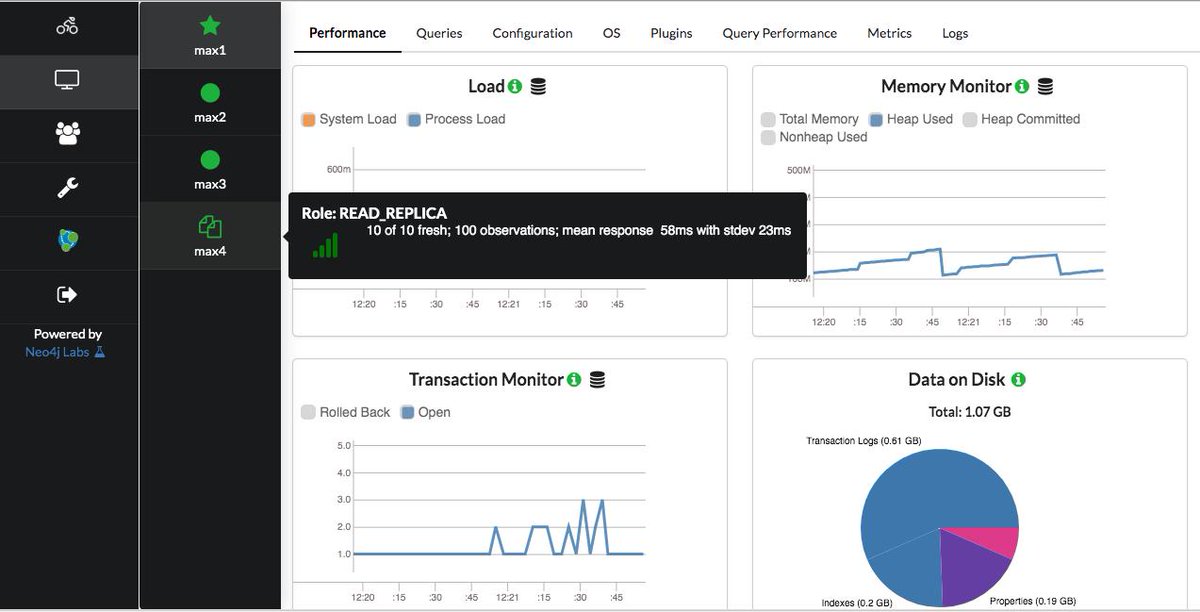
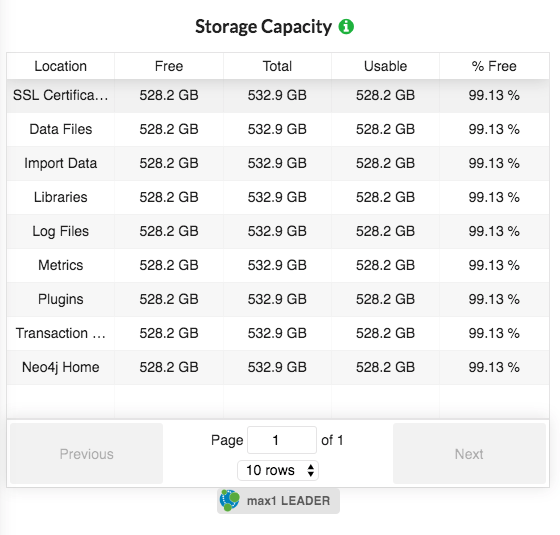
So the main typical tradeoff is latency. Batch when you need fresh data in larger volumes, say once per hour/day/week/month
Stream when time value of data is high/immediate and you can't afford to be more than minutes behind
Stream when time value of data is high/immediate and you can't afford to be more than minutes behind
The overall event queue (so to speak) that's being ingested has a total velocity. Let's say it's
- 1M events/day
- ~42k events/hour
- ~694 events/min
- ~69 events/sec
Let's say 2kb per event, or roughly 2gb/day, 138kb/sec.
- 1M events/day
- ~42k events/hour
- ~694 events/min
- ~69 events/sec
Let's say 2kb per event, or roughly 2gb/day, 138kb/sec.
Dirty secret is that "streaming" is usually just "micro-batching". At its most granular, each event is getting written to a database as it happens.
(Yawn) this is just batch load, where batchsize=1.
(Yawn) this is just batch load, where batchsize=1.
The point here is that your time requirements (data has to be < 1 min old) act to *constrain your maximum batch size*. In our fake math example, 1 minute means batches can't be bigger than 694 events (on average).
If you had larger batch sizes, you'd probably be violating timeliness. You look too batchy and not streamy enough.
Other hand: batchsize=1 is very streamy, not very batchy. But it also probably wastes resources (excess transactional overhead) without extra "time value"
Other hand: batchsize=1 is very streamy, not very batchy. But it also probably wastes resources (excess transactional overhead) without extra "time value"
the trick in this process is to pick a batch size that is always slow enough to maximize time value, while being large enough to minimize relative contribution of transactional overhead and get good performance.
example: if you take 10 million records and insert them 1 record 1 transaction into most databases, you will go very slow. You'd be better off with 10 million records in 1 tx, if you had the resources to do it.
So I derive this rule: the more real-time the data stream needs to be, the less *total throughput* you can achieve.
The more batchy non-real time you can be, the more you can pull the stops out, come up with various optimizations, and maximize total volume throughput/time
The more batchy non-real time you can be, the more you can pull the stops out, come up with various optimizations, and maximize total volume throughput/time
In batch world, we use "Tables for Labels" to decompose a big dataset into many tables, loading them individually.
https://twitter.com/mdavidallen/status/1318616863610425344?s=20
This is a great way to get good overall throughput on large volumes, but it's in sparky world, where we're very batchy, meaning "Tables for Labels" is a pretty poor fit for real-time streaming (imho)
flip side: writing a complex cypher pattern that takes a complex record and de-composes it / writes it into a multi-hop graph pattern -- this is very good for real time stuff, but sacrifices total throughput, because it creates locks all over the graph & operates on minibatches
It's just yet another case of TANSTAAFL (there ain't no such thing as a free lunch).
Lower latency
Higher throughput
Simpler
Pick 2
Lower latency
Higher throughput
Simpler
Pick 2
Now let's bear in mind this point, it's all just A -> B
https://twitter.com/mdavidallen/status/1392546161421164547
So "Batch vs. Streaming Data Ingest" to a database is the front-end data movement problem with an exactly corresponding "back-end data movement problem" of batch or streaming data egress from the database to some other downstream component of the architecture 

There, all the same issues repeat themselves. The "events" are transactions committing to the database. You literally can't publish *every record that changes* you can publish *every TX that commits* which is composed of many records that changed
in bigger data pipelines, what you see is it's all a bunch of bits moving in and out of pipes & storage sinks (databases), which is expressable as a set of couplings between producers & consumers, or different teams.
At each stage, data ought to get enriched or some value added
At each stage, data ought to get enriched or some value added
this is in contrast to the "code first" view of architectures, which tends to de-emphasize movement of bits, in favor of emphasizing the nature of the value add at each step. "Fancy algo analysis done here", or "Summary reporting done there"
at some point in the future maybe we do a crazier thread about how data & code are really two sides of the same coin (in a sense) -- and also about techniques we can use to transmogrify one into the other en.wikipedia.org/wiki/Homoiconi…
• • •
Missing some Tweet in this thread? You can try to
force a refresh