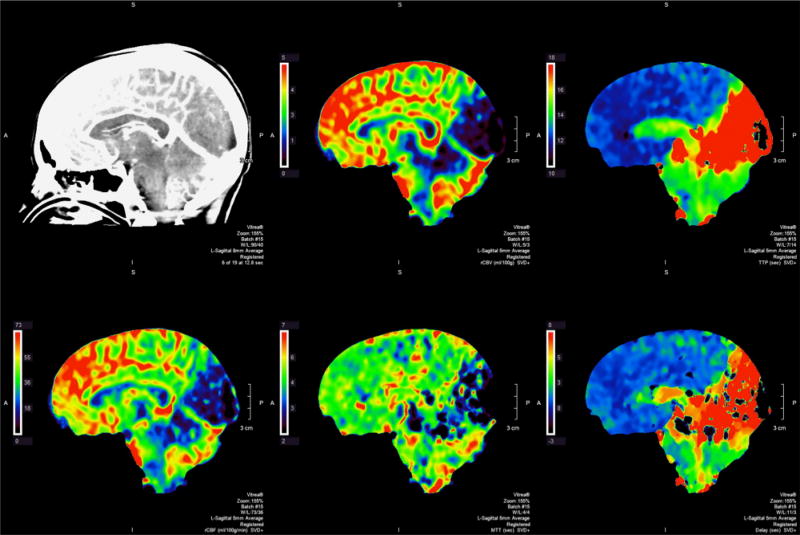
[THREAD] Bon alors c’est quoi cette histoire d’intelligence artificielle en médecine (et en radiologie) ?
Je vous l’avais promis pour le cap des 4000 followers (merci à tous de me faire cet honneur )!
Tenez, je vous offre un café ☕️ et maintenant vous pouvez dérouler ⬇️⬇️
Je vous l’avais promis pour le cap des 4000 followers (merci à tous de me faire cet honneur )!
Tenez, je vous offre un café ☕️ et maintenant vous pouvez dérouler ⬇️⬇️
Bon on va commencer par les disclaimers pour éviter des tacles appuyés prévisibles :
Je ne suis rémunéré par aucune société d’intelligence artificielle. Je travaille avec certaines d’entre elles dans le cadre de projets de recherche académiques. (2/32)
Je ne suis rémunéré par aucune société d’intelligence artificielle. Je travaille avec certaines d’entre elles dans le cadre de projets de recherche académiques. (2/32)
Je développe des algos dans le cadre de projets de recherche avec l’aide de data scientists. Il n’est pas nécessaire de savoir coder pour avoir une opinion éclairée sur le sujet (sinon on devrait interdire à tous les data scientists de travailler sur des projets médicaux) (3/32)
Je ne parlerai pas ici des autres aspects de mon métier (notamment la radiologie interventionnelle ++ qui soigne les gens, les principes de l’interprétation qui n’est pas juste de regarder des images, etc…). J’avais déjà fait un petit thread pour celles et ceux que ça intéresse!
On met les pieds dans le plat directement : d’où ça vient tout ce tintouin ? Et bien de Geoffrey Hinton qui annonçait en 2016 d’un élan prophétique : « dans 5 ans les radiologues seront dépassés, il faut arrêter d’en former dès aujourd’hui ». (5/32) 

Ce qui n'a bien entendu pas du tout fait le buzz car, on le sait, la presse n’est absolument pas friande de ce type de provocation et ne les prend jamais pour des vérités absolues (c’est faux).
Heureusement qu'il n'y a pas déjà une pénurie! (c'est faux 2)
rcr.ac.uk/posts/new-rcr-…
Heureusement qu'il n'y a pas déjà une pénurie! (c'est faux 2)
rcr.ac.uk/posts/new-rcr-…
Nous voilà 5 ans plus tard, « l’heure du bilan » comme on dit. Pas de nouvelles de Hinton (qui s’en prend aux chirurgiens now) par contre un autre monsieur, Andrew Ng - avec des propos proches, dit maintenant: «oui bon bah en fait ça marche pas si bien dans la vraie vie !» (7/32)

Comment ça se fait ? Qu’est-ce que ça veut dire ?
Le seul avantage à ce que la radiologie ait été ciblée depuis 5 ans, c’est qu’on commence maintenant à avoir un peu de recul sur les différents problèmes et à mieux les comprendre.
Beaucoup résident dans deux choses: (8/32)
Le seul avantage à ce que la radiologie ait été ciblée depuis 5 ans, c’est qu’on commence maintenant à avoir un peu de recul sur les différents problèmes et à mieux les comprendre.
Beaucoup résident dans deux choses: (8/32)
1) L'approche "always more" du big data et les gros sous qui vont avec, pouvant être déconnectés de la réalité clinique. L'idée qu'avec toujours plus de données, toujours plus d'argent investi, on fera forcément un meilleur algo. Mais est-ce pertinent pour le patient ? (9/32)
2) La différence d'approche méthodologique, avec d’un côté le versant « tech » qui a pour objectif de prouver une faisabilité technique avec des courbes de labo toujours meilleures. Publications faciles ++ De l’autre côté le médical qui demande des preuves sur le terrain. (10/32)
Et là ça coince. Après des centaines de publication « in silico », les gens ont commencé à se rendre compte que le deep learning a une grosse tendance à « overfit », c’est-à-dire à sur-performer sur des données en labo, mais à se dégrader dès qu’on l’applique ailleurs. (11/32)
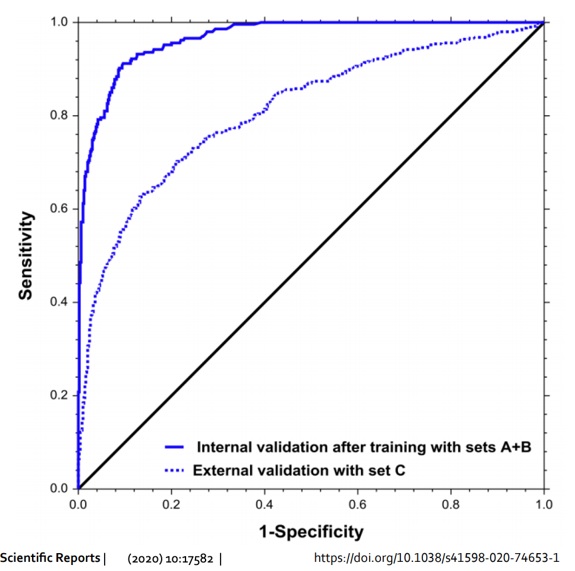
Alors que votre médecin préféré, même s’il traverse la rue pour aller dans l’hôpital d’en face, avec du matériel plus vieux et une population différente, a priori ses performances changent peu. C’est cool un humain sur cet aspect-là : on généralise facilement. (12/32)
Bon donc ça veut dire déjà que toutes les études qui n’ont pas testé leur modèle sur un jeu de données extérieures, sont très certainement en train de sur-évaluer leur modèle. Une étude a estimé que ça représente plus de 95-97% des publications Et quasiment 0 prospective (13/32)
En parallèle, les humains sont souvent représentés en « humain moyen » par rapport à une courbe ROC. Mais une démonstration graphique suffit pour montrer que l’humain « moyen » se situe visuellement toujours en dessous de la courbe des humains qu’il est censé représenter. (14/32)
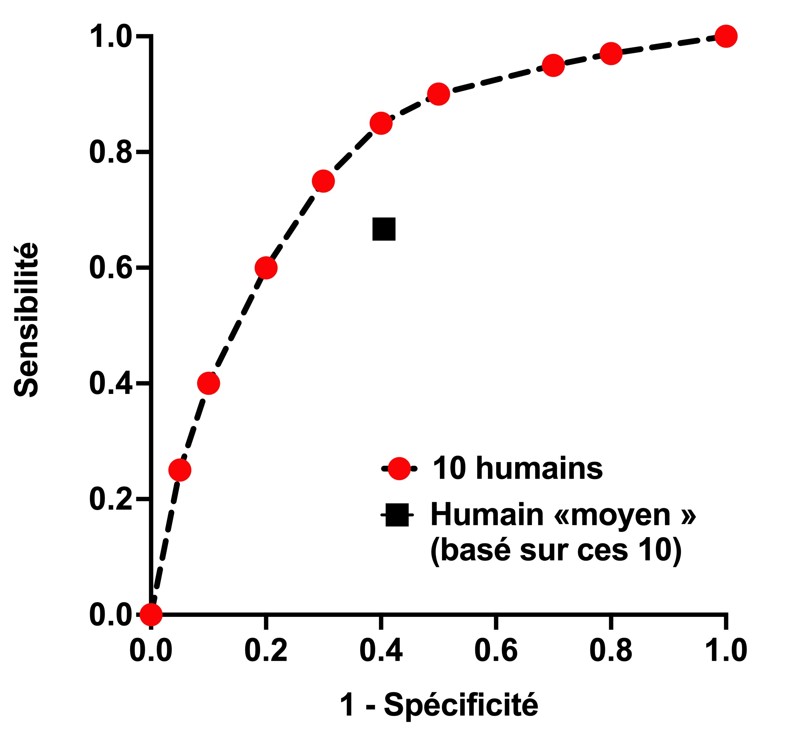
Vous comprendrez donc que la tendance de 99% des études est la suivante : sur-vendre son modèle (overfit, rétrospectif, généralement sans validation externe) et représenter graphiquement des « médecins moyens » (radio, dermato, ophtalmo…) sous la courbe. Bof bof ! (15/32)
Pour essayer d’améliorer le niveau des publications, des groupes de travail (CONSORT-AI et SPIRIT-AI) ont émis des recommandations, avec notamment un superbe travail de fond de @DrXiaoLiu qui s’investit particulièrement dans ce domaine. Bravo !(16/32)
nature.com/articles/s4159…
nature.com/articles/s4159…
Ca veut pas dire que l’idée est naze ni que le modèle est nul, mais ça veut juste dire que la conclusion ne PEUT PAS méthodologiquement être « le modèle est meilleur que l'humain dans le soin du patient ». Exemple typique dans cet article de Google sur le cancer du sein. (17/32)
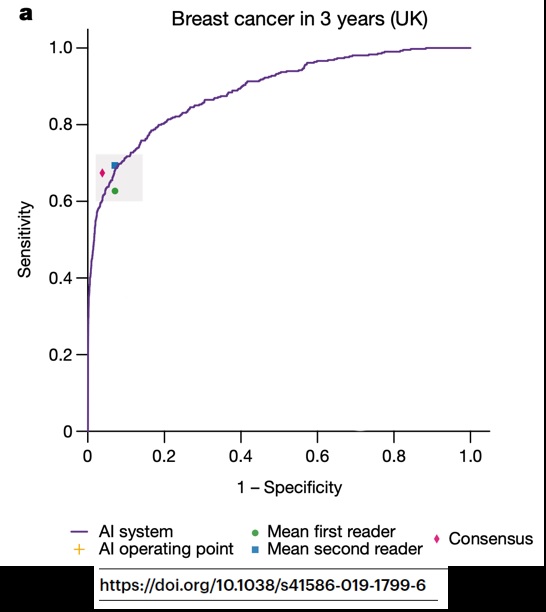
« Humain moyen », lecteurs ayant du relire des centaines d’examen rétrospectivement (= pas du tout les conditions cliniques), modèle représenté sur son set de validation interne (sa meilleure performance), etc… Bref.
Ce qui est également intéressant dans ces articles, (18/32)
Ce qui est également intéressant dans ces articles, (18/32)
c’est que la « taille de l’effet » n’est pas prise en compte dans les résultats. Par exemple, on considère de façon équivalente ce gros cancer (à gauche), vu par 6/6 radiologues mais pas par le modèle (!), et cette toute petite lésion vue par 0/6 radiologues. (19/32)
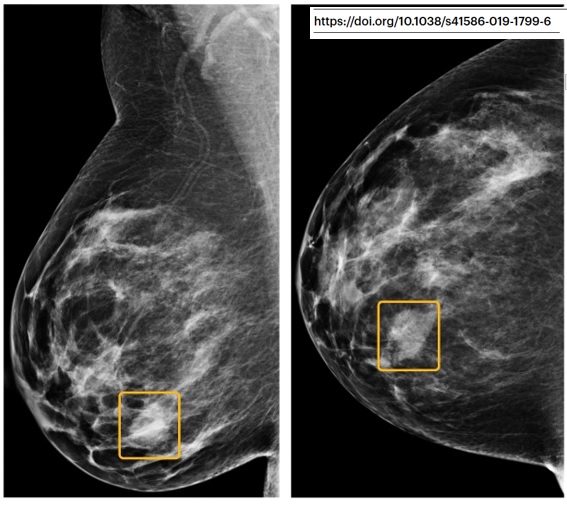
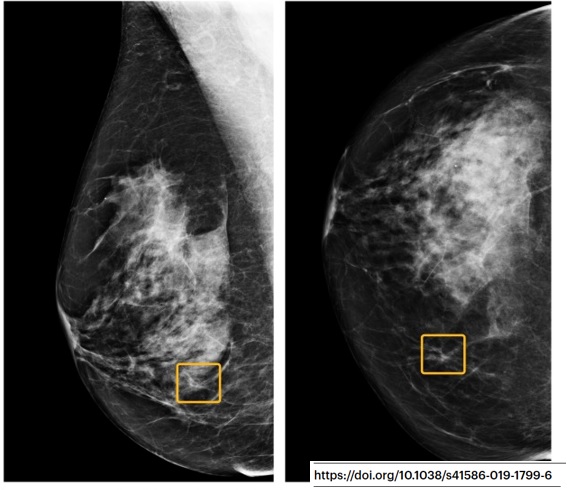
Mais dans la vraie vie ? Est-ce que la première aurait été plus agressive ? Est-ce que la deuxième aurait dû être traitée ou pas ? Ca grossit sur la mammo suivante ? Quel âge ? Quel sous-type histologique ? Bref, les patientes disparaissent au profit des images isolées. (20/32)
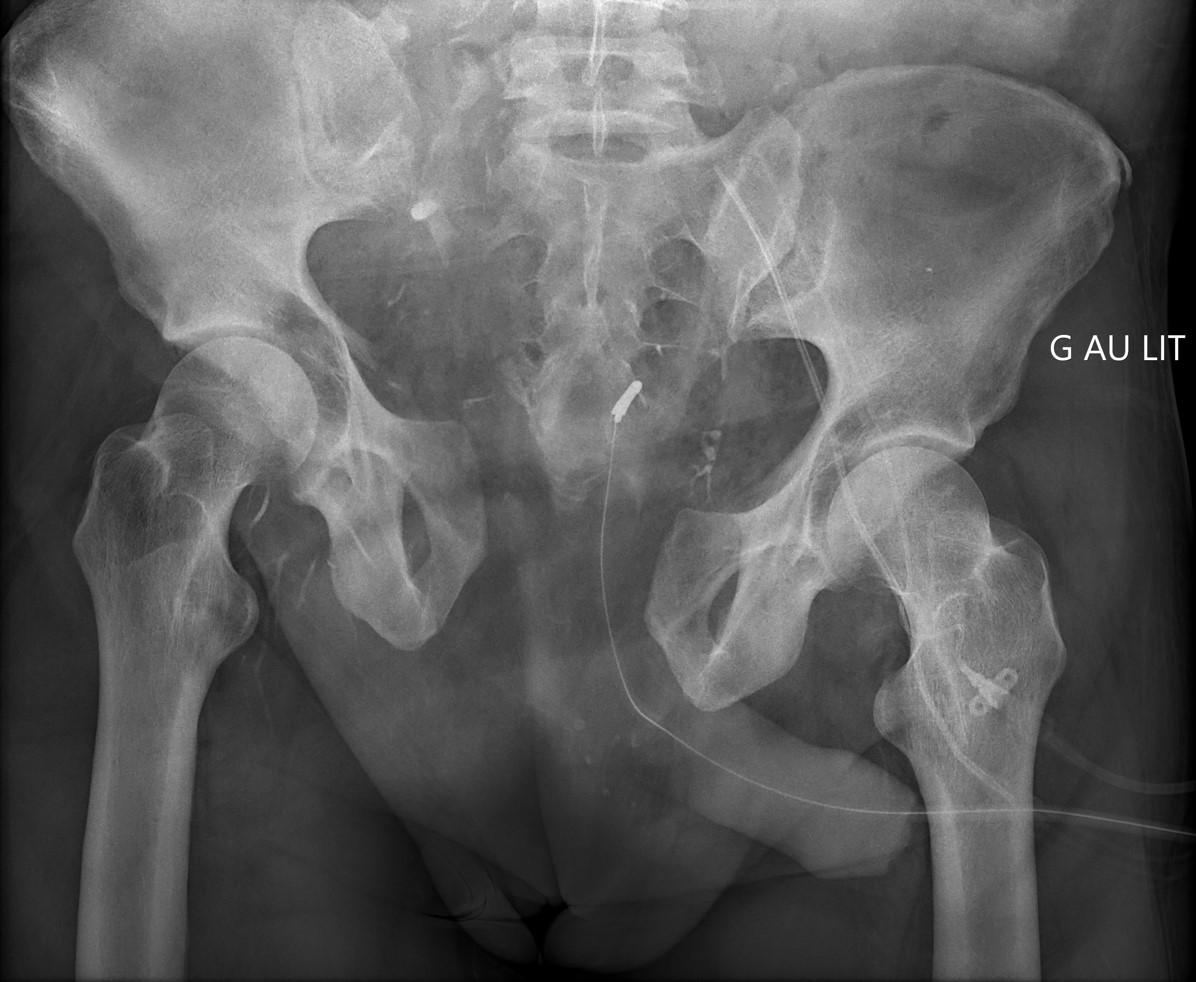
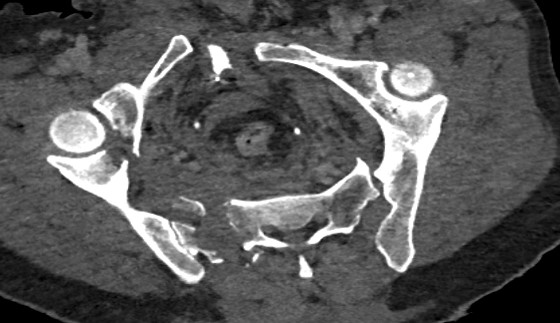
Et, paradoxalement, l'IA peut tout à fait spotter des petites anomalies mais rater des choses ENORMES au calme. Exemple ici avec un énorme fracas du bassin où l’algorithme répondait qu’il n’y avait pas de fracture. Bref: les humains et l’IA ne font pas les mêmes erreurs. (21/32)
Ce qui renforce l’idée d’une complémentarité plutôt que d’une substitution de tâche. Mais une publication récente commence à toucher du doigt que même les experts, devant une mauvaise prédiction, tendent à dégrader leurs performances ce qui est inquiétant: nature.com/articles/s4174…
En termes de business on est sur des millions d’euros investis dans chaque algorithme commercial. Vous pouvez trouver la liste des algos marqués CE par ici: grand-challenge.org/aiforradiology/. 1 algo = 1 question! Attention ce marquage ne présage pas de l’efficacité clinique réelle! (23/32)
D’ailleurs un article récent montrait que sur 100 algorithmes marqués CE, 64% n’ont aucune étude peer-reviewed, et seulement 18% pourraient avoir un potentiel impact clinique mais sur des données issues d'études rétrospectives donc peu robustes (24/32)
ncbi.nlm.nih.gov/pmc/articles/P…
ncbi.nlm.nih.gov/pmc/articles/P…
Des articles « vie réelle » commencent même à sortir, dont certains soulignent les performances significativement inférieures des algorithmes une fois déployés sur le terrain et sans pouvoir expliquer pourquoi. C’est fâcheux. (25/32) sciencedirect.com/science/articl…
Bref, au final j’en pense quoi de tout ça ? Que c’est une technologie fascinante, et qu’on n’en est encore qu’au début. Que tous ces biais initiaux vont progressivement s’améliorer (sauf peut-être dans les premiers articles de toutes les autres spés… SIGAPS tout ça...) (26/32)
Qu’il est impératif que la sphère de la data science prenne à bras le corps la question « clinique » réelle : études prospectives, évaluation des conséquences cliniques sur le terrain : à quoi bon payer des millions d’euros si au final rien ne change pour le patient ? (27/32)
Pour le domaine de la radiologie : applications techniques intéressantes dans le débruitage, l’accélération des séquences, la qualité image, le recalage. En diagnostic, peut-être pour les examens très standardisés avec peu de variabilité technique (radio standard, mammo) (28/32)
Que les investisseurs arrêtent de financer du vent : j’ai eu des discussions avec des industriels où il m’a été dit : tant qu’on montre des performances même rétrospectives et biaisées, les €€ pleuvent... Sinon on pourrait aussi former nos médecins avec cet argent non ? (29/32)
Arrêter de toujours croire que « plus c’est forcément mieux » : la solution ne réside pas toujours dans « il faut plus de données » mais dans une « meilleure question clinique ». Idem, dépister une pathologie n’est pas toujours utile cliniquement, et peut être délétère (30/32)
Enfin, qu’on se penche réellement sur les conséquences éthiques et sociétales : on sait que l’IA accroit les biais humains et peut être raciste, sexiste… discriminante aussi dans le diagnostic. Evidemment, ne pas reléguer au rang de technophobes ceux qui ont ce discours. (31/32)
Voilà c’est la fin du thread, je pourrais en parler pendant des heures car c’est fascinant et j’espère que vous avez appris des trucs 🙂🙂 [32/32 FIN]
• • •
Missing some Tweet in this thread? You can try to
force a refresh