
Finished watching all the Nanite presentations and the RenderDoc analysis blog posts by people.
It's time to do a thread comparing Nanite to our (Ubisoft/RedLynx) 2015 GPU-driven rendering tech. The base pieces are the same, but Nanite adds some awesome new/old innovations.
It's time to do a thread comparing Nanite to our (Ubisoft/RedLynx) 2015 GPU-driven rendering tech. The base pieces are the same, but Nanite adds some awesome new/old innovations.
Our joint GPU-driven rendering SIGGRAPH presentation with the Assassin's Creed team.
advances.realtimerendering.com/s2015/aaltonen…
advances.realtimerendering.com/s2015/aaltonen…
Mesh Clustering: Meshes split to small clusters based on locality. Back then we used strip clustering, but switched to index buffer generation. Everybody nowadays uses index buffer generation (or mesh shaders). Our cluster size was 64, Nanite is using 128. 

We had GPU-driven LOD solution. Choose a set of clusters for each instance based on distance. Artists had to manually author LODs and the tech demanded very good LODs. Nanite is much better here. They have innovative per-cluster seamless LOD solution. And automatic LOD authoring.
This is our two-phase occlusion culling solution. Use previous frame data as a starting point for the first pass and then fill missing clusters in the second pass. RenderDoc captures show that Nanite is using the same algorithm. This is a good algorithm. MM Dreams also uses it.

As said by Brian Karis in the Nanite presentations, precise occlusion culling is crucial for high density kit bashed content. Perfect LOD + fine grained culling = fixed triangle raster cost. Our game had UGC focus (non-professional content), they want to make artists life easier.
This is a screenshot showing culling efficiency when rendering a scene in center of 250K object "asteroid field". As you can see, techniques like this are perfect for partial occlusion, such as object clouds and vegetation. The visibility gets cut once all pixels are filled.

Virtual shadow mapping is important for high density rendering. It provides close to 1:1 pixel:texel mapping for all areas in the scene, and rejects excess work that would not land on the visible pixels. 3.5x faster and much better quality.
VTSM makes Nanite's shadows look good!
VTSM makes Nanite's shadows look good!

We implemented a deferred texturing pipeline with UV buffer. Nanite chose the V-Buffer approach:
jcgt.org/published/0002…
Both techniques defer the material/texture pixel cost to make overdraw super efficient. The trade-offs are however different.
jcgt.org/published/0002…
Both techniques defer the material/texture pixel cost to make overdraw super efficient. The trade-offs are however different.
Both employ a single cheap geometry pass (no Z-prepass). The MSAA trick can be combined with either technique and is 100% lossless for V-Buffer. But Epic is writing small triangles with compute shader (software raster), and you can't write to MSAA target from a compute shader :(
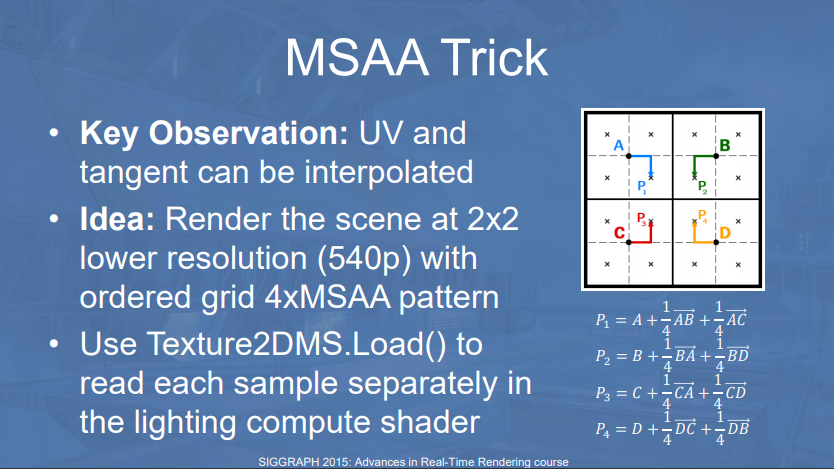
The MSAA trick is also quite hardware specific. On previous generation consoles you had to directly read the FMASK to decode it quickly. Modern AMD RDNA and Nvidia GPUs can directly load from MSAA buffer. Hardware compatibility makes it still iffy for a generic engine like UE5.

Both our tech and Nanite are leaning heavily on Virtual Texturing. With VT you have roughly 1:1 memory:pixel footprint for all your textures, independent on the scene complexity. This is super important for scenes like this, and makes artists life much easier.

We used deferred texturing UV-buffer with virtual texturing to implement single draw call rendering. Nanite is using V-Buffer and tiled material classification pass. Split/Second (Black Rock / Sumo Digital) pioneered this technique on Xbox 360. They were WAY ahead of their time.

Nanite is rendering a material id z-buffer and is employing hi Z and early Z to cull full screen material passes. They render a grid and NaN cull vertices based on the classification pass. This is similar to Split/Second. Xbox 360 XPS is replaced with compute shader of course :)
Intel's original V-buffer wasn't feasible as it didn't fit in 32 bits. Each instance had vastly different triangle count. When you combine clustering and early culling together, you get super tight numbering scheme. Nanite is using this kind of V-buffer.
forum.beyond3d.com/threads/modern…
forum.beyond3d.com/threads/modern…
The biggest achievement in Nanite is the way they combine all of this tech together. Great ideas collected in a single well optimized product. Their automatic cluster LOD is a massive improvement. Their software triangle raster beats hardware by 3x for small triangles.
My analysis of Nanite perceived "weaknesses":
https://twitter.com/SebAaltonen/status/1403043481254301708?s=20
Now let's analyze the weaknesses our our 2015 GPU-driven tech.
The biggest one by far was the LOD solution. We had GPU-driven LOD, but only at instance granularity and no artist support. Artists had to manually author all LODs by hand. We didn't even have offline tools for this.
The biggest one by far was the LOD solution. We had GPU-driven LOD, but only at instance granularity and no artist support. Artists had to manually author all LODs by hand. We didn't even have offline tools for this.
I remember our artists exporting a million rock instances cloud from Houdini and adding that on top of our terrain. It was a pain to get running well. They only had time to author 3 LODs for the rocks. That's nowhere near enough for results similar to Nanite.
Our LOD selection was from the object center point and our artists preferred very small hand authored objects. And they instanced a lot of them. There was no megascans, etc available back then. The problem with small instances is that you hit 1 cluster/object pretty soon.
There's no way to LOD below 1 cluster. You need to render all those 64 triangles (or 128 in Nanite) even if that object is just a couple of pixels in screen. This is less of a problem for Nanite as the demos are using larger megascan assets that cover more space.
Also our tech was running on AMD GCN2 based consoles, and GCN2 is notoriously bad for geometry processing (VS max occupancy = 2). Nanite is running on RDNA2 and they have a software rasterizer for small triangles. This is a massive advantage for 1 cluster "min LOD" instances.
Nanite has per-cluster LOD with lots of autogenerated LOD levels. They have more SW performant rasterizer for small triangles and better modern GPU. Additionally their content uses larger scanned meshes covering more space instead of massive amount of small instances.
Simple mesh instances don't really LOD well, not even with their advanced cluster LOD. So if your content is massively instanced soup of these, you will not get 1:1 triangle:pixel. SW raster helps here too of course. HW raster is VERY bad for subpixel triangles.
I am interesting in knowing what kind of improvements Brian was talking about when he said that they are planning to improve the performance in scenes with massive amount of instances. Are they just making fixed costs smaller or doing some sort of instance merging.
• • •
Missing some Tweet in this thread? You can try to
force a refresh




