
Feature Scaling is one of the most important transformations you need to apply to your data before feeding it to your machine learning model.
🧵thread 👇
🧵thread 👇
- Feature scaling refers to the concept of normalizing the range of input features so that they have similar scales.
- Most machine learning algorithms do not work well when the input numerical attributes have very different scales.
- Most machine learning algorithms do not work well when the input numerical attributes have very different scales.

1⃣Min-Max Scaling (Normalization)
- In this method, values are rescaled so they end up ranging between 0 and 1 (the range can be changed in some cases).
- Normalization is very sensitive to the existence of outliers.
- In this method, values are rescaled so they end up ranging between 0 and 1 (the range can be changed in some cases).
- Normalization is very sensitive to the existence of outliers.

2⃣Standardization (Z-Score Normalization)
- Centers the data by making the values in each feature have a mean of zero and a variance of one.
- Standardization is much less affected by outliers but it does not reduce its impact on the model.
- Centers the data by making the values in each feature have a mean of zero and a variance of one.
- Standardization is much less affected by outliers but it does not reduce its impact on the model.

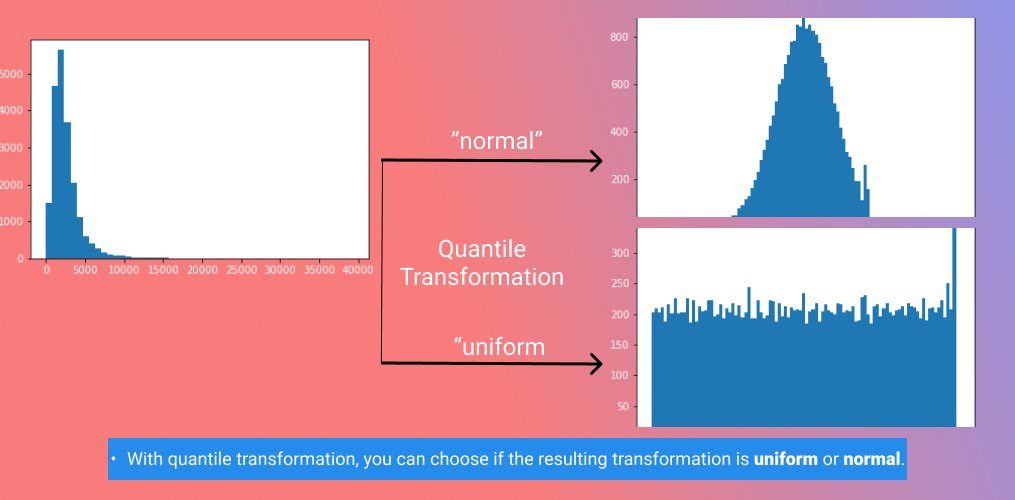
3⃣Quantile Transformation
- Transform features using quantile information so that they follow a normal distribution.
- It uses non-linear transformations to spread out the most frequent values and reduce the impact of outliers.
- Transform features using quantile information so that they follow a normal distribution.
- It uses non-linear transformations to spread out the most frequent values and reduce the impact of outliers.
For more content about machine learning and computer science, please follow me @ammar_yasser92.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


