
I tweet about data science.
Trying to make the road to machine learning mastery more navigable to others.

 Unfortunately, it's never that easy.
Unfortunately, it's never that easy.
 On the other hand, the cost function commonly contains valleys (flat segments) where gradient descent moves really slow.
On the other hand, the cost function commonly contains valleys (flat segments) where gradient descent moves really slow.
 The above code produces the following plot where there is a clear overlapping of the plotted points.
The above code produces the following plot where there is a clear overlapping of the plotted points.
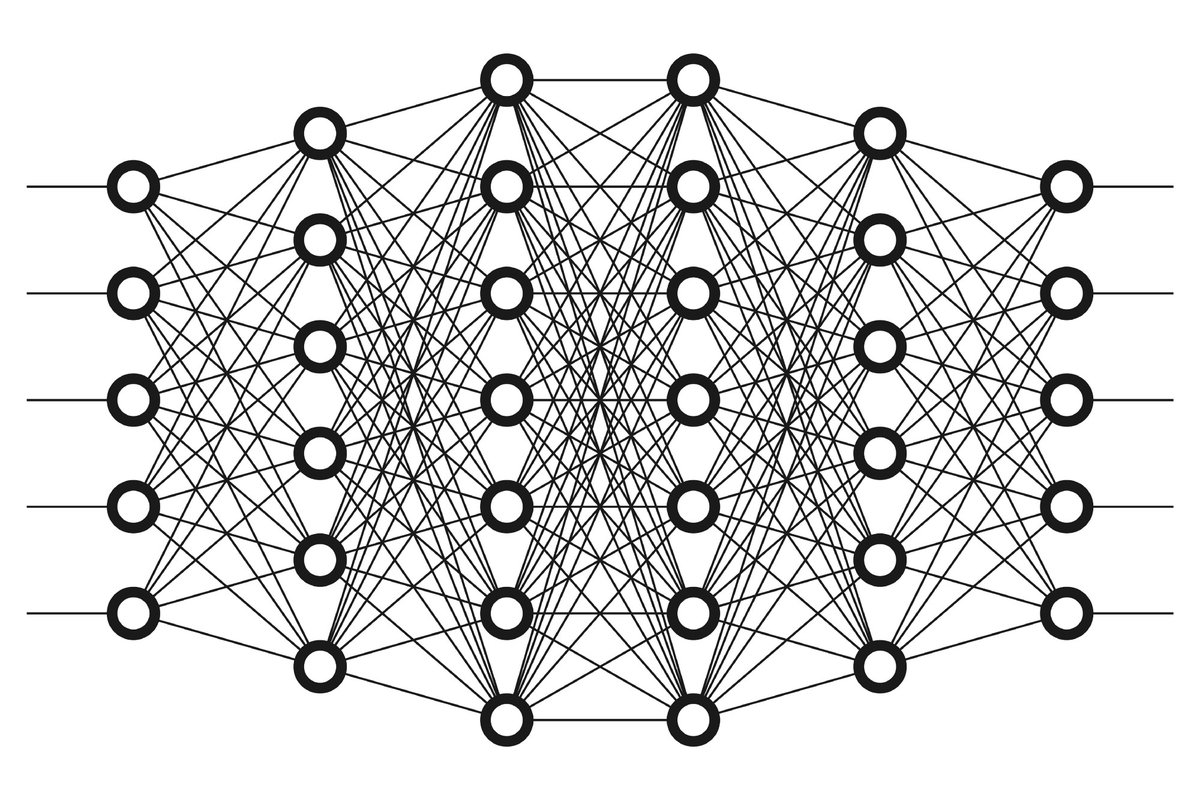 In a previous thread, we discussed the vanishing/exploding gradient problem in DNNs, and we mentioned that the two main reasons for this problem are:
In a previous thread, we discussed the vanishing/exploding gradient problem in DNNs, and we mentioned that the two main reasons for this problem are: Introduction
Introduction In a previous thread, we discussed that we should split our data into three parts:
In a previous thread, we discussed that we should split our data into three parts: 📜Introduction
📜Introduction 📜Introduction
📜Introduction ✍️Introduction
✍️Introduction


