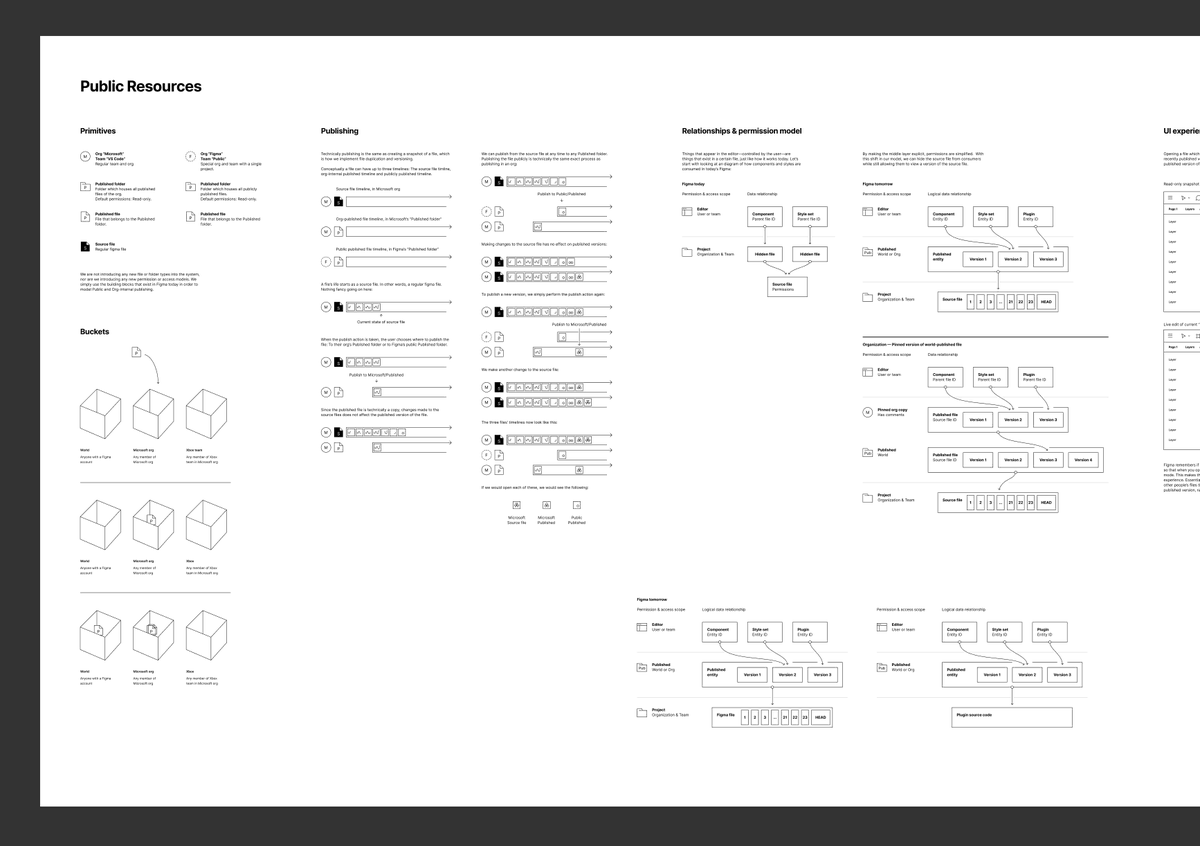
Concurrent programming can be hard. After days (over the course of weeks) I was today finally able to make a channel implementation pass my tests. Sometimes the smallest things takes the most time to get right.
Here's a short thread …
Here's a short thread …
The kind of "channel" I've implemented is a form of CSP (see swtch.com/~rsc/thread/) which is used to communicate between threads. It's similar to Go's chan but works with threads rather than a custom coroutine runtime.
(Image from github.com/arild/csp-pres…) 

There are just two operations: send and receive.
send() blocks until there's a thread calling recv()
recv() blocks until there's a thread calling send()
A channel may be buffered in which case send and recv may succeed immediately.
So what makes this so challenging?
send() blocks until there's a thread calling recv()
recv() blocks until there's a thread calling send()
A channel may be buffered in which case send and recv may succeed immediately.
So what makes this so challenging?
Time and causality; avoiding deadlocks and carefully handling CPU cache hierarchies, all while being efficient in time and space. For this to not be a confusing wild goose chase of trial and error, we need to have Mechanical Sympathy.
"Mechanical Sympathy" is a term coined by racing driver Jackie Stewart. Paraphrased and applied to computers: "You don’t have to be a hardware engineer to write good software, but you do have to have Mechanical Sympathy". What this means to me …
What this means to me is that having a sense of how the computer works helps tremendously in writing correct, efficient and elegant software, even if I don't fully understand all the details of the hardware.
One of the key aspects of modern software performance is managing memory. Modern CPUs have a hierarchy of data caches in addition to main working memory (RAM.) CPUs today can complete a staggering amount of computations through not just raw clock speed but …

… through a complex combination of clever "temporal" tricks, like intra-core pipeline parallelism and predicting what will be needed soon — the latter is key and involves the CPU and its cores moving instructions and data around in the various caches …
… (aka "line caches.") To write fast software you need to "trick" the CPU into invalidating as little data in its caches as possible. Each cache level is usually several orders of magnitude faster than the next. Don't be surprised by a 400x performance difference.
A second important fallout of this kind of hardware design is that changes to data done by one core may note be visible to another core at the same point in time. A simple example is a counter: Without some form of synchronization the value will become corrupt.

We'd expect the counter x in the image to be 2 after it has been incremented twice, but it's 1!
Shared memory is simply a hard problem to solve efficiently. What we need to do is to tell the CPU that "x may be modified by other cores" causing loads & stores to shared memory.
Shared memory is simply a hard problem to solve efficiently. What we need to do is to tell the CPU that "x may be modified by other cores" causing loads & stores to shared memory.
But that's really slow, as discussed earlier. So a better implementation of a multi-process counter is to give each core it's own counter and then occasionally as them to store their results to shared memory and ask one of them to sum up all counters.

This is better and will be faster than a naïve "locking"/"synchronized" counter (if we ignore the up-front costs of introducing multithreading in the first place.) But we might run into another problem here which affects performance and correctness in some cases: false sharing.
"False sharing" is seemingly weird term for what happens when multiple cores update memory that sits inside the same "cache line". Chances are your CPU's cache line size is 64 bytes and that it chunks up memory into cache lines by simply aligning addresses to 64.
(Image from software.intel.com/content/www/us…)

So for our parallel counter example we need to make sure that the memory of the core-specific counters x¹ and x² lie inside separate cache line boundaries. This is easy to do in C et al. If you look at MP-forward code like Intel TBB or LMAX Disruptor you'll see this a lot.

Okay that's going to make our silly parallel counter really efficient.
So what's up with this channel thing I've been struggling with?
Well, I wanted to make it very fast and avoid thread sync. TLDR: I reached a compromise.
How many implementation attempts did I make? Many:
So what's up with this channel thing I've been struggling with?
Well, I wanted to make it very fast and avoid thread sync. TLDR: I reached a compromise.
How many implementation attempts did I make? Many:

After researching and testing existing solutions, I tried to port a few of them. One neat one is Plan 9's libthread but that one, like the Go implementation, relies on a coroutine runtime but could be adopted to work with plain C11 threads.
I also tried porting a few other approaches like the (very java, very complex lol) LMAX Disruptor (which sadly requires call-site level changes so that went out the door) and Intel TBB's concurrent_queue which was an exercise in unwrapping 100 layers of complex C++ to …
… understand it. So that was fun. The TBB implementation was actually a pretty good fit, but I must have made some mistake as after 20 hours of debugging a correctness issue I have up. Also, the code was too complex (my C port was 1000 lines, C++ original is like 10x that.)
So I ended up with a really neat solution that is only about 350 lines of C, primarily based on the Go chan implementation cooked up together with some bits and pieces of ideas from other things I've written for other reasons (like a hybrid spinning-then-syscalling mutex.)
It passes a set of tests (which I ran a few thousand times over and over, over lunch, just to be sure ha ha... non-determinism, yay) The GIF in the head of this Twitter thread shows the tests. It's also fairly efficient:

(that benchmark is first an interleaving single-threaded program followed by a worst-case scenario starving, unbalanced multi-threaded program.)
There was a lot of this the past weeks. Deadlocks, "fun" memory crashes, etc.
I call it "fun with lldb" 😬 (It's basically "programming BDSM.")
I call it "fun with lldb" 😬 (It's basically "programming BDSM.")

For some deadlock bugs I had to devise a special logging mechanism since printf (anything dealing with FILE in libc) will implicitly sync threads (libc will lock a mutex on a FILE for each op) which would cause results to vary if I ran an experiment with instrumentation or not.
The debug logging basically works like the "parallel counter" example shown earlier but uses a write syscall to send its results to a central location. With that, I was able to order log messages by the CPU's view of time/causality and find two bugs. [img: timeline of 3 threads]

If you made it all the way here, congrats.
You get a cake.
{\___/}
( • - •)
/ >🍰
You get a cake.
{\___/}
( • - •)
/ >🍰
If you're curious and managed to find this hidden tweet, this is what the interface to the channel implementation looks like. It's very plain and simple (which is the way I like my codez.)

Note that there are "atomic" and "memory fence" CPU instructions that can be used to tell the CPU that "this memory here used for x is shared by many cores" which in turn makes the CPU flush caches when storing to them to maintain cache coherency (and that is slow.)
If you're curious to learn more about the impact of CPU cache hierarchies, check out this good recent article by @ForrestTheWoods: forrestthewoods.com/blog/memory-ba…
• • •
Missing some Tweet in this thread? You can try to
force a refresh