
Thrilled to share new work on AI for education: can we give detailed, high-quality feedback to students?
Post: ai.stanford.edu/blog/prototran…
NYT Coverage: nytimes.com/2021/07/20/tec…
A collab w. the amazing @mike_h_wu @chrispiech & co 🧵
Post: ai.stanford.edu/blog/prototran…
NYT Coverage: nytimes.com/2021/07/20/tec…
A collab w. the amazing @mike_h_wu @chrispiech & co 🧵

2/ Student feedback is a fundamental problem in scaling education.
Providing good feedback is hard: existing approaches provide canned responses, cryptic error messages, or simply provide the answer.
Providing good feedback is hard: existing approaches provide canned responses, cryptic error messages, or simply provide the answer.



3/ Providing feedback is also hard for ML: not a ton of data, teachers frequently change their assignments, and student solutions are open-ended and long-tailed.
Supervised learning doesn’t work. We weren’t sure if this problem can even be solved using ML.
Supervised learning doesn’t work. We weren’t sure if this problem can even be solved using ML.

4/ But, we can frame it as a few-shot learning problem! Using data from past HWs and exams of Stanford’s intro CS course, we train a model to give feedback for a new problem with only ~20 examples.
Humans are critical to this process: instructors define a rubric & feedback text.
Humans are critical to this process: instructors define a rubric & feedback text.
5/ Because this is open-ended Python code, our base architecture is transformers + prototypical networks.
But, there are many important details for this to *actually* work: task augmentation, question & rubric text as side info, preprocessing, and code pre-training.
But, there are many important details for this to *actually* work: task augmentation, question & rubric text as side info, preprocessing, and code pre-training.

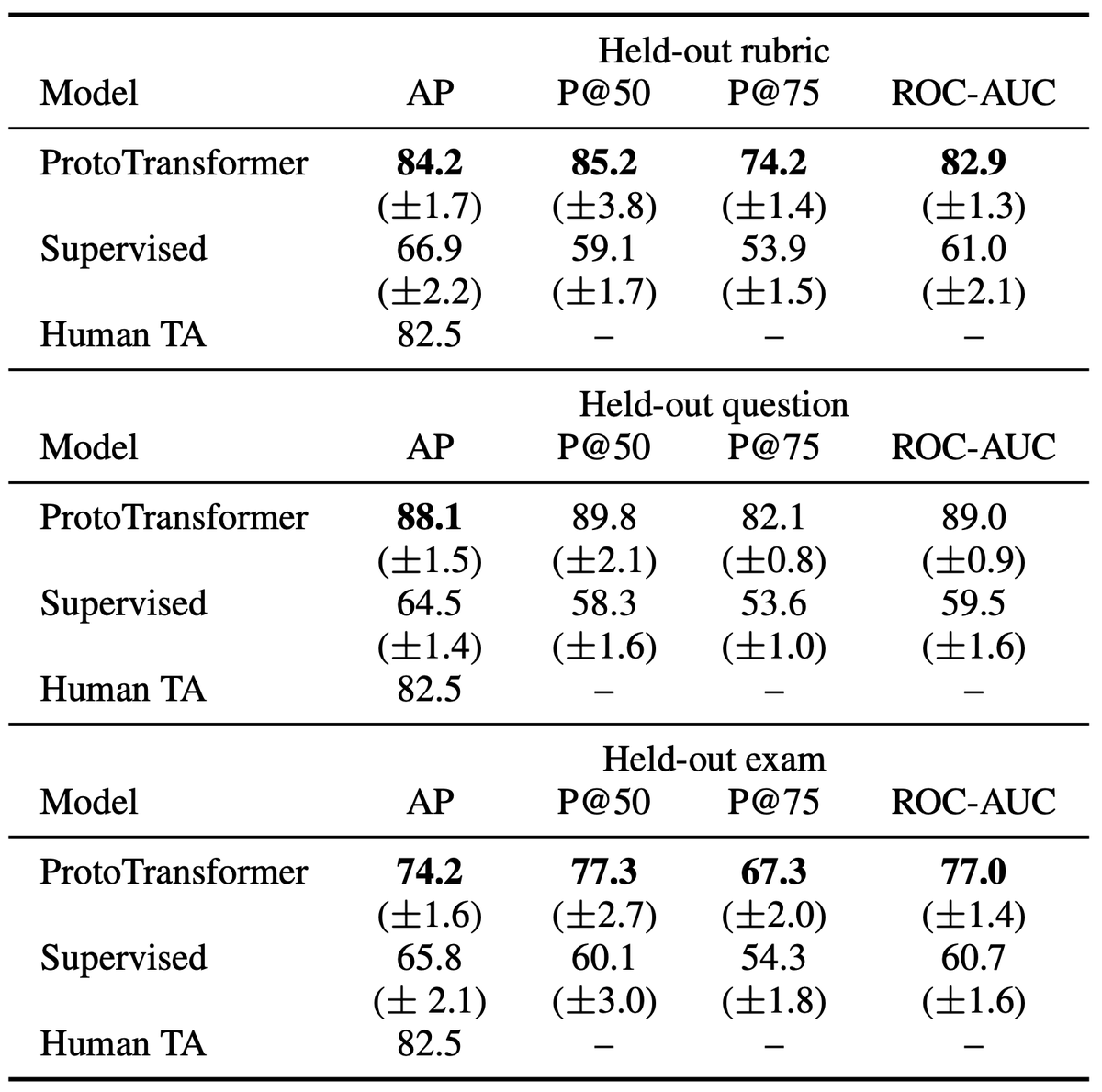
6/ How well does this work?
In offline expts, meta-learning:
* achieves 8%-21% greater accuracy than supervised learning
* comes within 8% of a human TA on held-out exams.
Ablations show a >10% difference in accuracy with different design choices.
In offline expts, meta-learning:
* achieves 8%-21% greater accuracy than supervised learning
* comes within 8% of a human TA on held-out exams.
Ablations show a >10% difference in accuracy with different design choices.
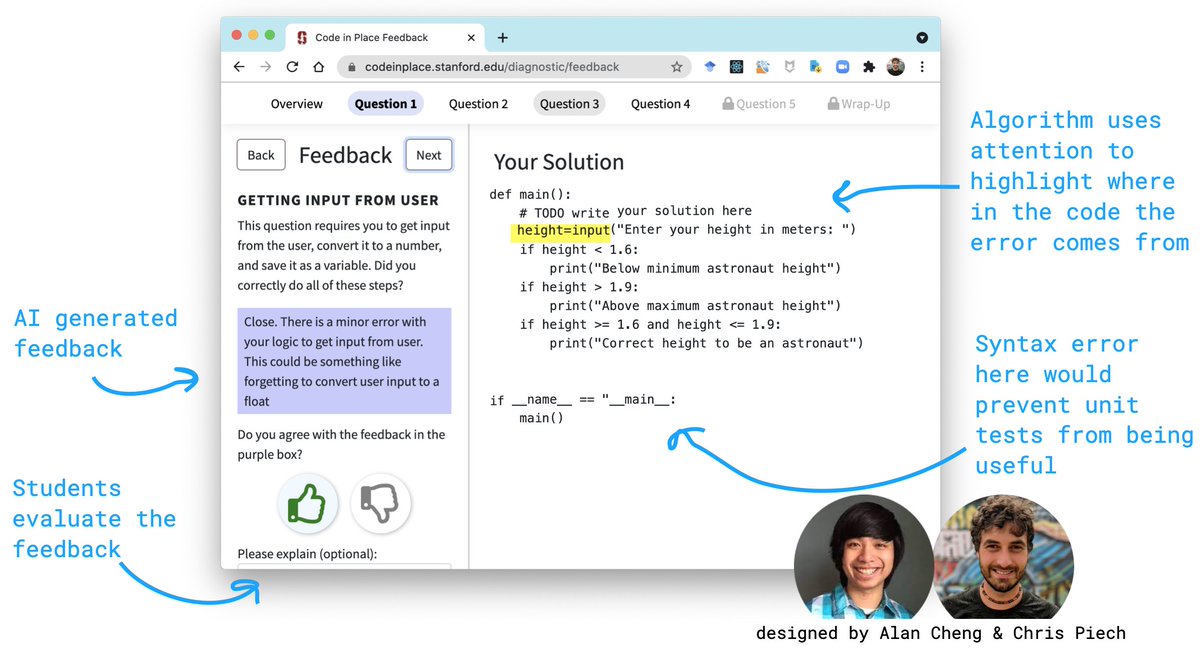
7/ Most importantly, this model was deployed to 16,000 student solutions in Code-in-Place, where it was previously not possible to give feedback.
In a randomized blind A/B test, students preferred model feedback slightly *more* than human feedback AND rated usefulness as 4.6/5.
In a randomized blind A/B test, students preferred model feedback slightly *more* than human feedback AND rated usefulness as 4.6/5.

8/ We also did several checks for bias. Among the countries & gender identities with the most representation (i.e. largest statistical power), we see no signs of bias.
Not too surprising given the model only sees typed python code w/o comments, but super important to check.
Not too surprising given the model only sees typed python code w/o comments, but super important to check.

9/ At the beginning of this project, we had no idea that the goal would be possible, let alone deployable.
I still remember very naively approaching @chrispiech about using meta-learning for education after watching a talk he gave >1.5 years ago. :)
I still remember very naively approaching @chrispiech about using meta-learning for education after watching a talk he gave >1.5 years ago. :)
10/ It’s super exciting to see both real-world impact of meta-learning algorithms + substantive progress on AI for education
Post: ai.stanford.edu/blog/prototran…
Paper: tinyurl.com/meta-edu-paper
Coverage: nytimes.com/2021/07/20/tec…
Post: ai.stanford.edu/blog/prototran…
Paper: tinyurl.com/meta-edu-paper
Coverage: nytimes.com/2021/07/20/tec…
11/ Finally, an important perspective that’s also in @CadeMetz's NYT article:
These systems can't and shouldn't replace instructors.
Their promise instead lies in helping instructors reach more students, especially those who don't have access to high-quality education.
These systems can't and shouldn't replace instructors.
Their promise instead lies in helping instructors reach more students, especially those who don't have access to high-quality education.
12/12
Thank you to the Code-in-Place team for allowing us to try out this experiment in their awesome course: codeinplace.stanford.edu
A truly collaborative effort with @mike_h_wu, @alan7cheng, @chrispiech, @stanfordcocolab
Thank you to the Code-in-Place team for allowing us to try out this experiment in their awesome course: codeinplace.stanford.edu
A truly collaborative effort with @mike_h_wu, @alan7cheng, @chrispiech, @stanfordcocolab
• • •
Missing some Tweet in this thread? You can try to
force a refresh






