
🥁 New @streamlit app! 🎈
WTFaq leverages the power of @huggingface Transformers & @Google T5 to generate quality question & answer pairs from URLs!
Select your best Q&As on the fly & export them to CSV!
🎲App bit.ly/3zzS4us
📬Post bit.ly/3kUz59O
#SEO
↓🧵
WTFaq leverages the power of @huggingface Transformers & @Google T5 to generate quality question & answer pairs from URLs!
Select your best Q&As on the fly & export them to CSV!
🎲App bit.ly/3zzS4us
📬Post bit.ly/3kUz59O
#SEO
↓🧵

First things first, pick a URL!
The app will crawl the URL's content & retrieve it back in the app.
Server side only for now. I'm planning to add the ability to crawl client-side rendered URLs soon, stay tuned! 🤗
2/10
The app will crawl the URL's content & retrieve it back in the app.
Server side only for now. I'm planning to add the ability to crawl client-side rendered URLs soon, stay tuned! 🤗
2/10

Once a URL is crawled, you can check its scraped content in the toggleable section (see below👇)
As we're still in beta and want to monitor memory spikes closely, built Q&A pairs are based on the first thousand scraped characters only.
We will increase that limit soon!😉
3/10
As we're still in beta and want to monitor memory spikes closely, built Q&A pairs are based on the first thousand scraped characters only.
We will increase that limit soon!😉
3/10

Wait a few seconds for the results to be populated.
Results will be displayed in a matrix of 5 to 20 question & answers pairs.
You can select your favourite Q&A pairs on the fly simply by ticking them, as shown on the video below 👇
4/10
Results will be displayed in a matrix of 5 to 20 question & answers pairs.
You can select your favourite Q&A pairs on the fly simply by ticking them, as shown on the video below 👇
4/10
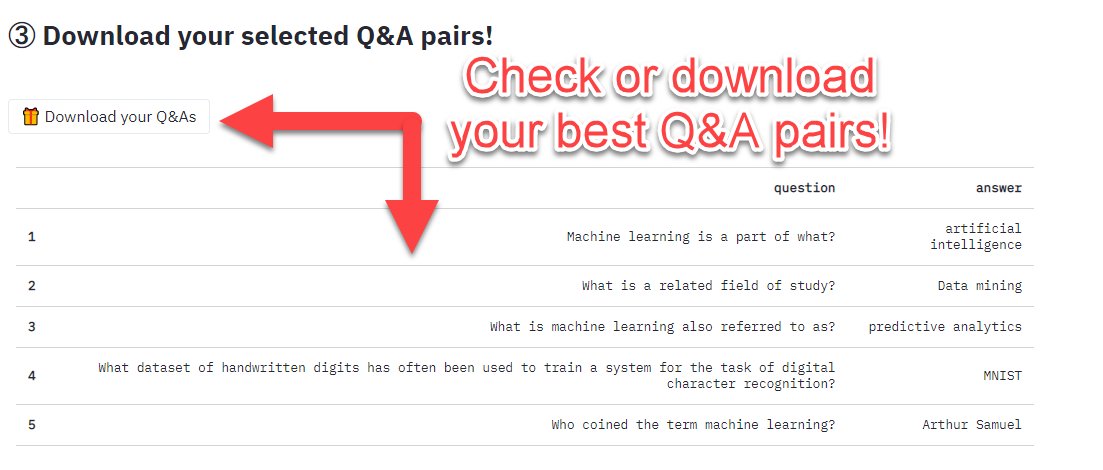
Final step!
Your selected Q&A pairs will be displayed in the bottom table.
If you wish to download them, click that download button - Voilà!
5/10
Your selected Q&A pairs will be displayed in the bottom table.
If you wish to download them, click that download button - Voilà!
5/10
Many cool content & #SEO use cases! 🔥
✓ Use it for content generation purposes
✓ Map-out Q&A pairs with your product, service or brand
✓ Research any topic and get Q&A pairs from that seed topic
✓ Differentiate your pages!
6/10
✓ Use it for content generation purposes
✓ Map-out Q&A pairs with your product, service or brand
✓ Research any topic and get Q&A pairs from that seed topic
✓ Differentiate your pages!
6/10
🧰 The stack is 100% #Python! 🐍🔥
✓ Web framework: @streamlit! 🎈
✓ Scraping tasks: Requests
✓ @Google T5 via @huggingface Pipelines - huggingface.co/transformers/m…
✓ Not to forget @thiago's mighty Component for coloured labels! github.com/tvst/st-annota… 🙌
7/10
✓ Web framework: @streamlit! 🎈
✓ Scraping tasks: Requests
✓ @Google T5 via @huggingface Pipelines - huggingface.co/transformers/m…
✓ Not to forget @thiago's mighty Component for coloured labels! github.com/tvst/st-annota… 🙌
7/10

🛠️ Still To-Do’s:
✓ Optimise code to increase speed ⚡
✓ Increase RAM capacity to mitigate bumps and allow for more content to be analysed
✓ Provide additional Q&A algorithms
Kudos to @huggingFaces and @Streamit DevOps for their support so far! 🙌
8/10
✓ Optimise code to increase speed ⚡
✓ Increase RAM capacity to mitigate bumps and allow for more content to be analysed
✓ Provide additional Q&A algorithms
Kudos to @huggingFaces and @Streamit DevOps for their support so far! 🙌
8/10
📂 About open-sourcing the code:
That code currently lies in a private repo. I should be able to make it public soon for you to re-use it in your own apps and creations!
Keep your eyes peeled! 🙌
9/10
That code currently lies in a private repo. I should be able to make it public soon for you to re-use it in your own apps and creations!
Keep your eyes peeled! 🙌
9/10
WTFaq is still in beta, head-off to my Gitter page for bug reports, Qs or suggestions:
▶️ gitter.im/DataChaz/what-…
This app is free! You can buy me a ☕ to support my work if it's useful to you!
▶️ buymeacoffee.com/cwar05
🎲 Check my other apps! charlywargnier.com/my-public-web-…
10/10
▶️ gitter.im/DataChaz/what-…
This app is free! You can buy me a ☕ to support my work if it's useful to you!
▶️ buymeacoffee.com/cwar05
🎲 Check my other apps! charlywargnier.com/my-public-web-…
10/10

• • •
Missing some Tweet in this thread? You can try to
force a refresh


