
I will be live tweeting @Tesla AI Day Here. Personally looking at the data flow, latency, low power and performance of #Dojo and how it compares to @Google #TPU version 4 and other HPC systems and how it directly relate to #AutonomousVehicles #FSDBeta
Well as usual, Tesla is fashionably late and we are almost 18 mins past the start time. And the beat goes on...
#AIDay starts with a demo of FSD with the driver griping the steering wheel with his left hand in what looks to be the streets of California. #DojovsTPU #Dojo @Tesla 

.
@elonmusk says @Tesla "is the leader in real world AI" due to FSD Beta. Although there are other systems like
@Mobileye Supervision and Huawei Autopilot that also does L2 anywhere in the country.
@elonmusk says @Tesla "is the leader in real world AI" due to FSD Beta. Although there are other systems like
@Mobileye Supervision and Huawei Autopilot that also does L2 anywhere in the country.
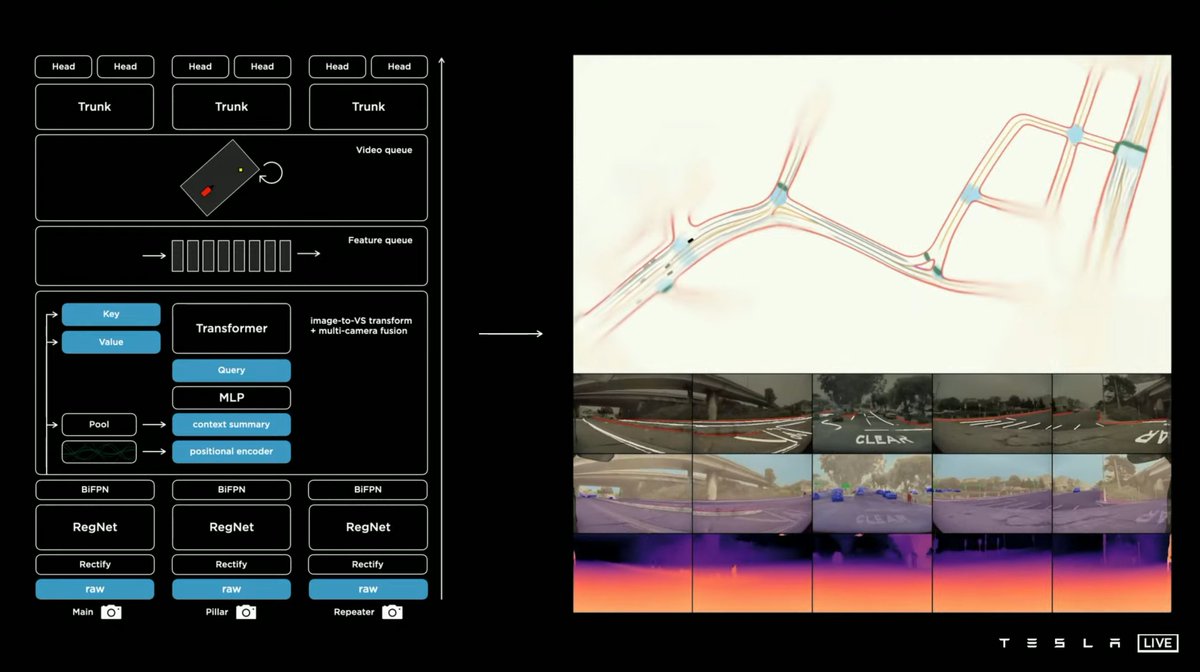
.@karpathy is now presenting the case for @Tesla camera only system and comparing it to the human eye. The obvious problem is that the cameras Tesla uses are very low resolution (1.2 MB) compared to the Human eye and have disparity in dynamic range. #AIDay #TeslaVision #Dojo

Here is a comparison to the industry standard 8mb type of camera used by most AV systems versus the type of camera that @Tesla uses
.@karpathy Is now detailing the difficulty in 2D detection from each individual vs 3D detection from Multi-Cam. This is a known problem with Camera based systems in converting 2D detection into 3D world view.

.@karpathy Showcases a variety of prediction networks which are all industry standard. For example Pseudo Lidar (Vidar) and Bird's Eye View network. Its good that @Tesla is finally making progress with this but they are simply following the direction of the industry at large.
For example here is @Mobileye and @Waymo Vidar (Pseudo Lidar) NN system.
https://twitter.com/Christiano92/status/1385383504066789376
What's missing in this #AIDAy is prediction. @elonmusk recently detailed how they just began working on their prediction network. @Tesla still relies on conventional control algorithm. Think of algorithms like R*, you could do Convex Optimization.

So from my understanding they run the FSD Planner on other cars. So its not actually predicting what a typical car would do in a situation but what the FSD Planner would do. Thats...what..
Other AV companies run complex multi-modal prediction networks that accurately the future behavior of moving agents in any given situation. @Waymo recently published a paper on Target-driveN Trajectory Prediction
.@karpathy Touches on 4D labeling through time. @kvogt talked about it in his presentation at 16mins. This is also industry standard.
Now onto Auto labeling. which is off-board labeling because you have the future frames, allowing you to estimate accurate bounding boxes and tracking. This is also industry standard. Here is Drago at @Waymo giving a SOTA presentation on it.

Difference between @Tesla simulation and @Waymo is that Tesla is based on video game engine which suffer from Domain Gap & looks like Tesla knows that and are trying to work on sensor simulation which Waymo has already developed called Simulation City.
blog.waymo.com/2021/06/Simula…
blog.waymo.com/2021/06/Simula…
Here is @Waymo Simulation City. Realistic NN generated 3D Surfel Map not made by video game engine (UE), which they can relight with 24 hour realistic TOD, weather, seasons, various sensor simulation NNs, and smart Imitation and RL learned agents that Drago have talked about.


In comparison a single @Google TPU v4 pod (4k chips) delivers 1.1 Eflop and has the best performance in MLperf benchmarks, which is something you don't see mentioned. What matters is the actual benchmark performance and we see nothing provided by @Tesla cloud.google.com/blog/products/…
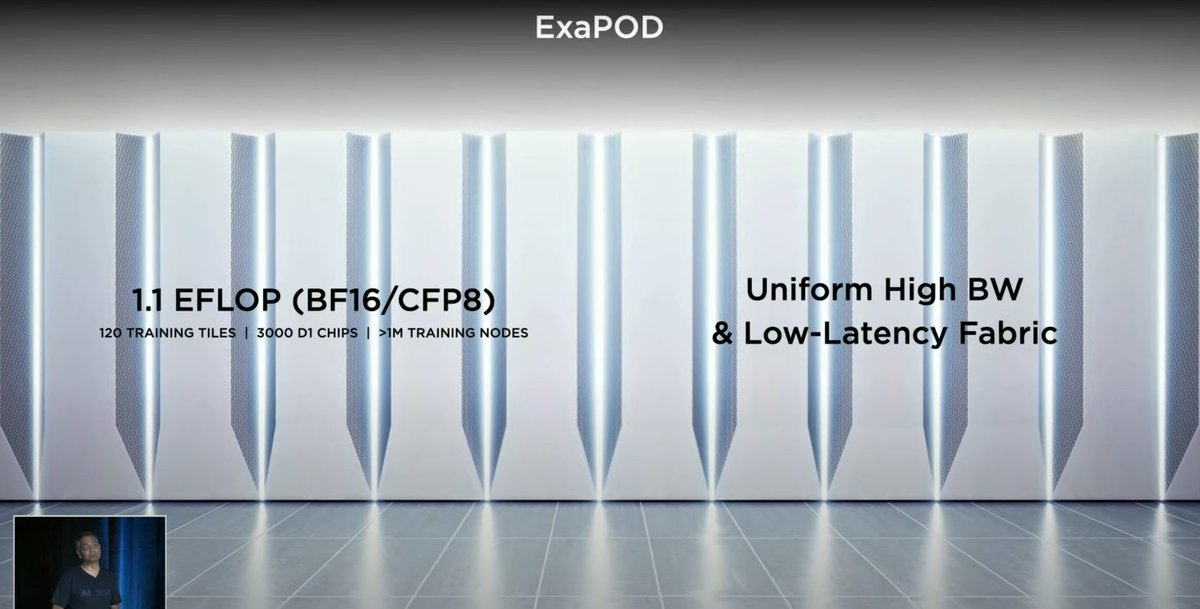
Its worth noting that AI Accelerators like the TPU (ASIC) are just Matrix multiply accumulators (MACs).
Which is all the calculation a neural network needs to do. Matrix Multiplication and Addition.
Which is all the calculation a neural network needs to do. Matrix Multiplication and Addition.

CPU are bad at this because of the memory bottle due to the fact they have to access the register/memory after each calculation. GPU's have 100's processing units and are good for brute force parallelizable calculations. But they still run into the memory bottleneck problem.
In contrast the TPU uses high speed interconnect & the hardware does sync in an instant. First TPU loads the data into the MAX accumulators & as each multiplication is executed, the result is passed to the next multiplier while also summing & nothing is saved in memory/registry.
• • •
Missing some Tweet in this thread? You can try to
force a refresh





