
If you're like me, you've written a lot of PyTorch code without ever being entirely sure what's _really_ happening under the hood.
Over the last few weeks, I've been dissecting some training runs using @PyTorch's trace viewer in @weights_biases.
Read on to learn what I learned!
Over the last few weeks, I've been dissecting some training runs using @PyTorch's trace viewer in @weights_biases.
Read on to learn what I learned!
I really like the "dissection" metaphor
a trace viewer is like a microscope, but for looking at executed code instead of living cells
its powerful lens allows you to see the intricate details of what elsewise appears a formless unity
kinda like this, but with GPU kernels:
a trace viewer is like a microscope, but for looking at executed code instead of living cells
its powerful lens allows you to see the intricate details of what elsewise appears a formless unity
kinda like this, but with GPU kernels:
number one take-away: at a high level, there's two executions of the graph happening.
one, with virtual tensors, happens on the CPU.
it keeps track of metadata like shapes so that it can "drive" the second one, with the real tensor data, that happens on the GPU.
one, with virtual tensors, happens on the CPU.
it keeps track of metadata like shapes so that it can "drive" the second one, with the real tensor data, that happens on the GPU.
in Good PyTorch Code™️, these two processes, connected by red lines in the screencap above, operate in parallel, with neither waiting on the other
does that sound right, @PyTorchPractice?
does that sound right, @PyTorchPractice?
I cut my teeth on TensorFlow 1, where graphs were compiled ahead of time, and did a lot of my grad school work in classic CPU-only autograd, because I needed forward-mode differentiation for fast Hessians (don't ask), so this was not at all obvious to me!
This is also why it's so 🔑 that you use num_workers>0 in your DataLoader.
Otherwise, the CPU forward pass won't start until the batch has been loaded, and then the next batch won't start loading until the optimizer step is done.
That's a lot of (expensive!) idle GPU time😬
Otherwise, the CPU forward pass won't start until the batch has been loaded, and then the next batch won't start loading until the optimizer step is done.
That's a lot of (expensive!) idle GPU time😬
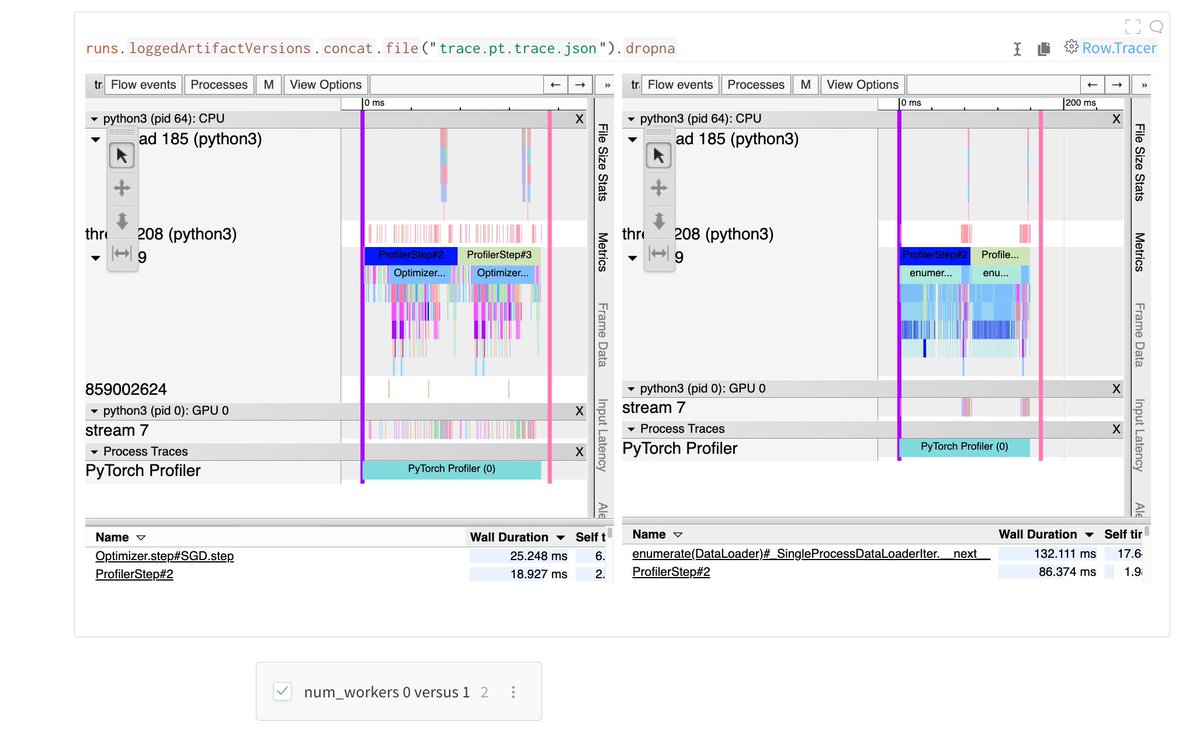
I learned a whole lot more using the trace viewer, including the reasoning behind most of @karpathy's hitherto mysterious tips on optimizing @PyTorch.
read more and learn how to use it yourself here:
wandb.me/trace-report
read more and learn how to use it yourself here:
wandb.me/trace-report
or just get your hands dirty with the Colab!
there's lots more to look into: fused ops, fused optimizers, the impact of benchmarking to pick kernels, ... you name it.
let me know if you find anything interesting!
wandb.me/trace-colab
there's lots more to look into: fused ops, fused optimizers, the impact of benchmarking to pick kernels, ... you name it.
let me know if you find anything interesting!
wandb.me/trace-colab
PS: this hot'n'fresh @weights_biases feature is courtesy of @vanpelt, who incorporated PyTorch's excellent trace viewer into our Artifacts system so that they can more easily be tracked, shared, and integrated into dashboards and reports
• • •
Missing some Tweet in this thread? You can try to
force a refresh



