
🚨Model Alert🚨
🏋️♂️ State-of-the-art sentence & paragraph embedding models
🍻State-of-the-art semantic search models
🔢State-of-the-art on MS MARCO for dense retrieval
📂1.2B training pairs corpus
👩🎓215M Q&A-training pairs
🌐Everything Available: SBERT.net
🧵
🏋️♂️ State-of-the-art sentence & paragraph embedding models
🍻State-of-the-art semantic search models
🔢State-of-the-art on MS MARCO for dense retrieval
📂1.2B training pairs corpus
👩🎓215M Q&A-training pairs
🌐Everything Available: SBERT.net
🧵
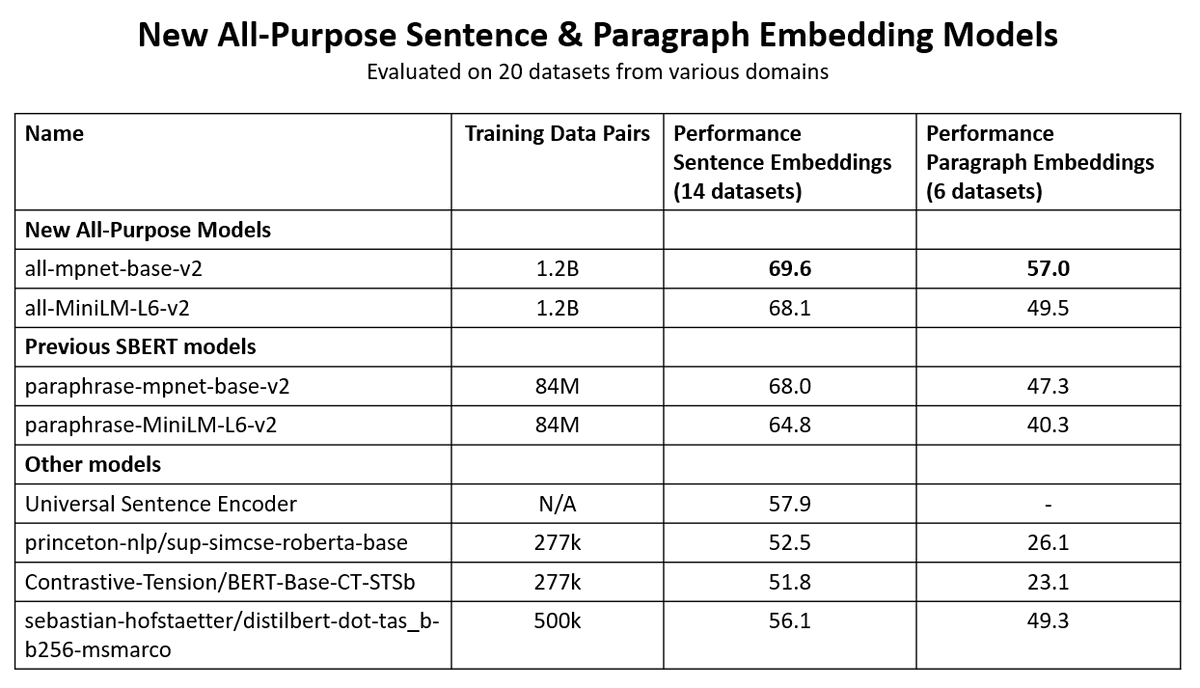
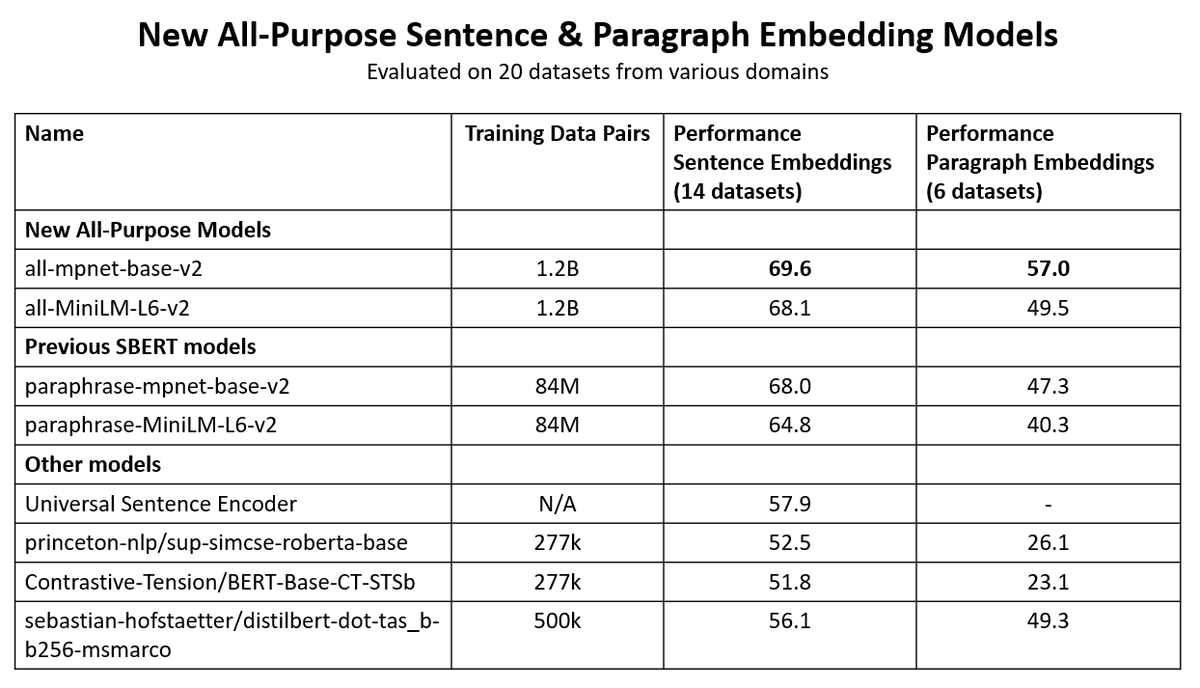
🚨 All-Purpose Sentence & Paragraph Embeddings Models
As part of the JAX community week from @huggingface we collected a corpus of 1.2 billion training pairs => Great embeddings for sentences & paragraphs
Models: sbert.net/docs/pretraine…
Training Data: huggingface.co/datasets/sente…
As part of the JAX community week from @huggingface we collected a corpus of 1.2 billion training pairs => Great embeddings for sentences & paragraphs
Models: sbert.net/docs/pretraine…
Training Data: huggingface.co/datasets/sente…
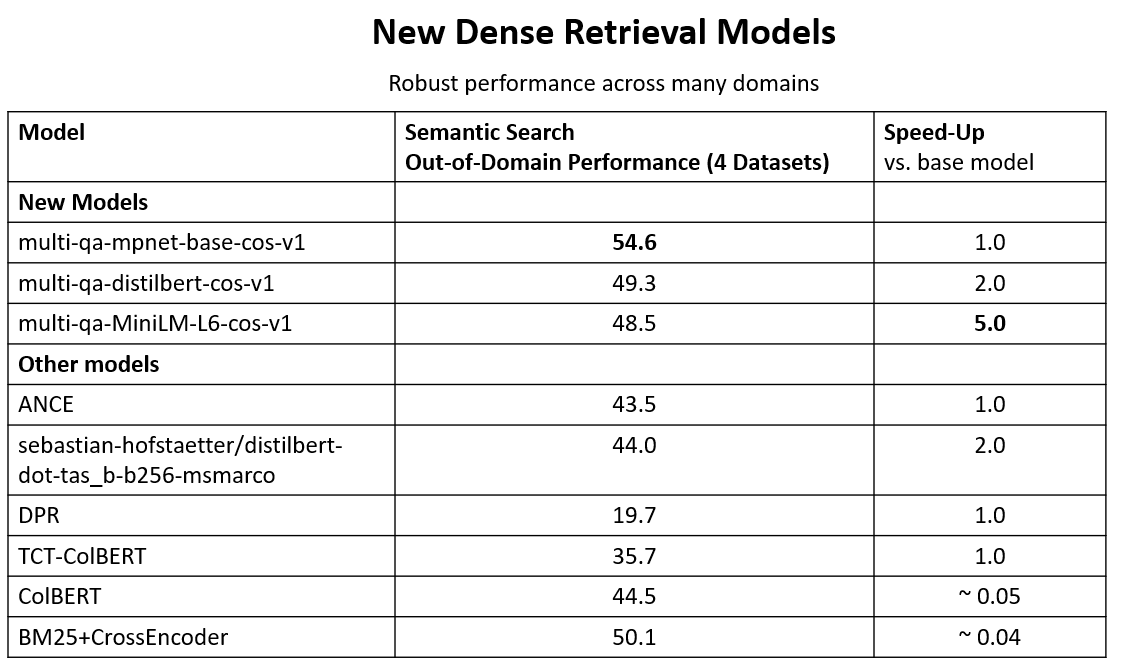
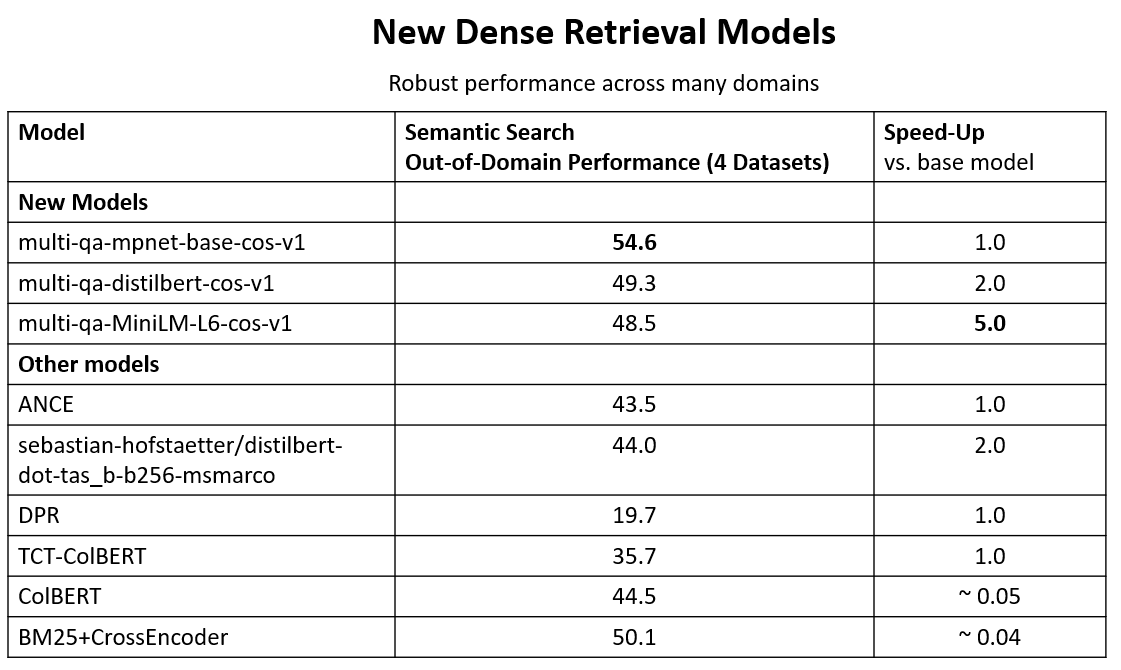
🚨Semantic Search Models
Performing well on out-of-domain data is challenging for neural retrieval models. By training on 215 million (question, answer)-pairs, we get models that generalize well across domains.
Models: sbert.net/docs/pretraine…
Data: huggingface.co/sentence-trans…
Performing well on out-of-domain data is challenging for neural retrieval models. By training on 215 million (question, answer)-pairs, we get models that generalize well across domains.
Models: sbert.net/docs/pretraine…
Data: huggingface.co/sentence-trans…
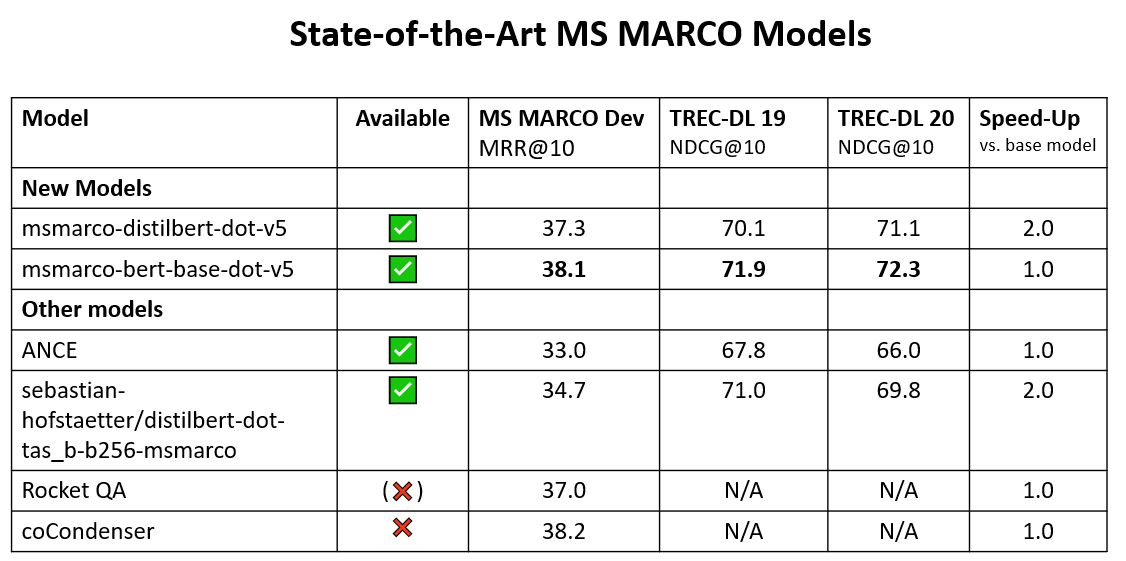
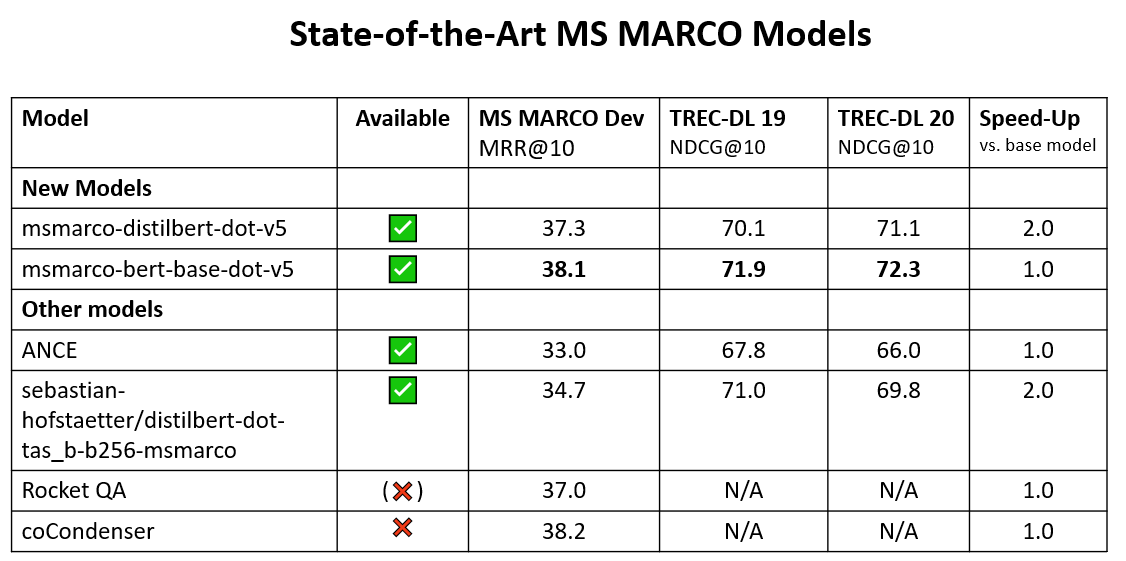
🚨State-of-the-art MS MARCO Models
We mined 160 million hard negatives for the MS MARCO dataset and scored them with a CrossEncoder.
We then trained Bi-Encoders on these using MarginMSE Loss (arxiv.org/abs/2010.02666)
Code: sbert.net/examples/train…
Data: huggingface.co/datasets/sente…
We mined 160 million hard negatives for the MS MARCO dataset and scored them with a CrossEncoder.
We then trained Bi-Encoders on these using MarginMSE Loss (arxiv.org/abs/2010.02666)
Code: sbert.net/examples/train…
Data: huggingface.co/datasets/sente…
📂1.2 Billion Training Pairs
Training on large datasets is essential to generalize well across domains and tasks.
Previous models were trained on rather small datasets of a few 100k train pairs and had issues on specialized topics.
We collected 1.2B training pairs from ...
Training on large datasets is essential to generalize well across domains and tasks.
Previous models were trained on rather small datasets of a few 100k train pairs and had issues on specialized topics.
We collected 1.2B training pairs from ...
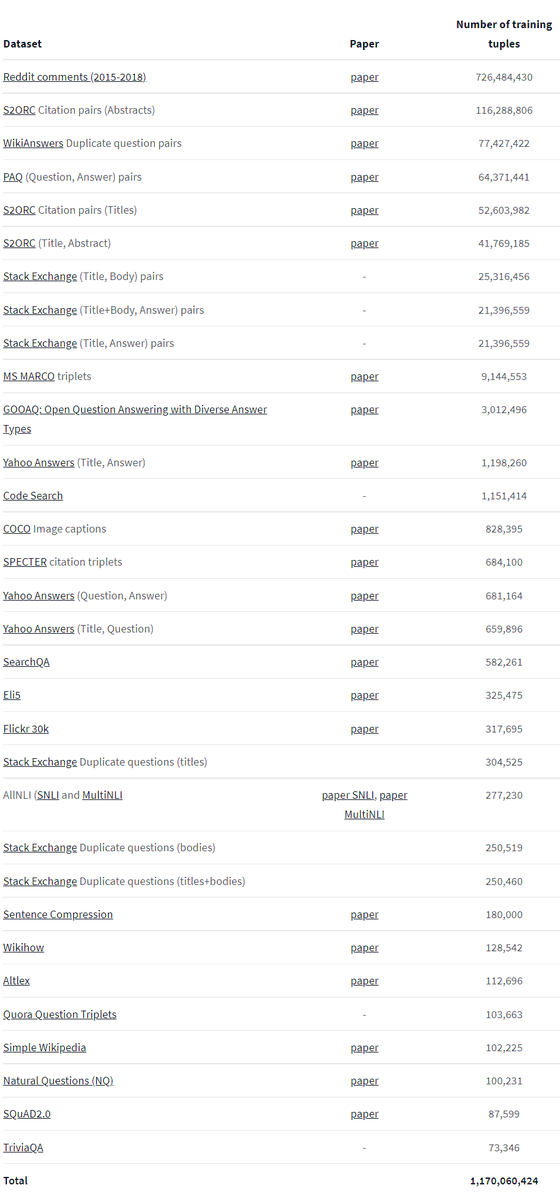
... different sources: Reddit, Scientific Publications, WikiAnswers, StackExchange, Yahoo Answers, Quora, CodeSearch...
They are shared in a unified format here: huggingface.co/datasets/sente…
They are shared in a unified format here: huggingface.co/datasets/sente…
👫In July, @PatrickPlaten & @psuraj28 organized the JAX community event.
A large group of people joined to train the best embedding models in existence:
discuss.huggingface.co/t/train-the-be…
We collected 1.2B training pairs and trained the models for about a week on a TPU-v3-8
A large group of people joined to train the best embedding models in existence:
discuss.huggingface.co/t/train-the-be…
We collected 1.2B training pairs and trained the models for about a week on a TPU-v3-8
📺How did we train these models?
As part of the event I gave two talks how to train these models:
Code: github.com/nreimers/se-py…
Video: Detailed explanation about the training code
Video: Theory on training embedding models:
As part of the event I gave two talks how to train these models:
Code: github.com/nreimers/se-py…
Video: Detailed explanation about the training code
Video: Theory on training embedding models:
🇺🇳 What about multilingual models?
Improved multilingual models are in progress.
Multilingual Knowledge Distillation (arxiv.org/abs/2004.09813) requires good parallel data.
- Parallel data for sentences: huggingface.co/datasets/sente…
- Parallel data for paragraphs: 🚧 In progress
Improved multilingual models are in progress.
Multilingual Knowledge Distillation (arxiv.org/abs/2004.09813) requires good parallel data.
- Parallel data for sentences: huggingface.co/datasets/sente…
- Parallel data for paragraphs: 🚧 In progress
• • •
Missing some Tweet in this thread? You can try to
force a refresh



