Excited to announce our #EMNLP2021 paper that shows how to turn a pre-trained language model or even a randomly initialized model into a strong few-shot learner.
Paper: arxiv.org/abs/2109.06270
w/ amazing collaborators: @lmthang, @quocleix, @GradySimon, @MohitIyyer
1/9👇
Paper: arxiv.org/abs/2109.06270
w/ amazing collaborators: @lmthang, @quocleix, @GradySimon, @MohitIyyer
1/9👇

Despite their strong performance on many tasks, large-scale pre-trained language models do not perform as well when limited labeled data is available (e.g., on small datasets or in few-shot settings). Collecting more labeled data can help but can also be prohibitively expensive.
We propose STraTA, which stands for Self-Training with Task Augmentation, an approach that combines two complementary methods, task augmentation and self-training, to effectively leverage task-specific unlabeled data, which is comparatively cheaper to obtain.
STraTA starts with task augmentation that uses unlabeled texts from the target domain to synthesize a large amount of in-domain training data for an auxiliary task (i.e., natural language inference), which is then used for intermediate fine-tuning (see the figure below).

We show that task augmentation alone can significantly improve downstream performance across different tasks, generally outperforming other competing fine-tuning approaches in both high- and low-data regimes.
STraTA further uses the auxiliary-task model created by task augmentation as a base model for self-training, where it is fine-tuned on the available labeled data for the target task and is then used to infer predictions (pseudo labels) on unlabeled data for subsequent training.
Our experiments reveal that using a strong base model and training on a broad distribution of pseudo-labeled data are key factors for successful self-training, which we hope will enable the wider adoption of self-training in NLP.
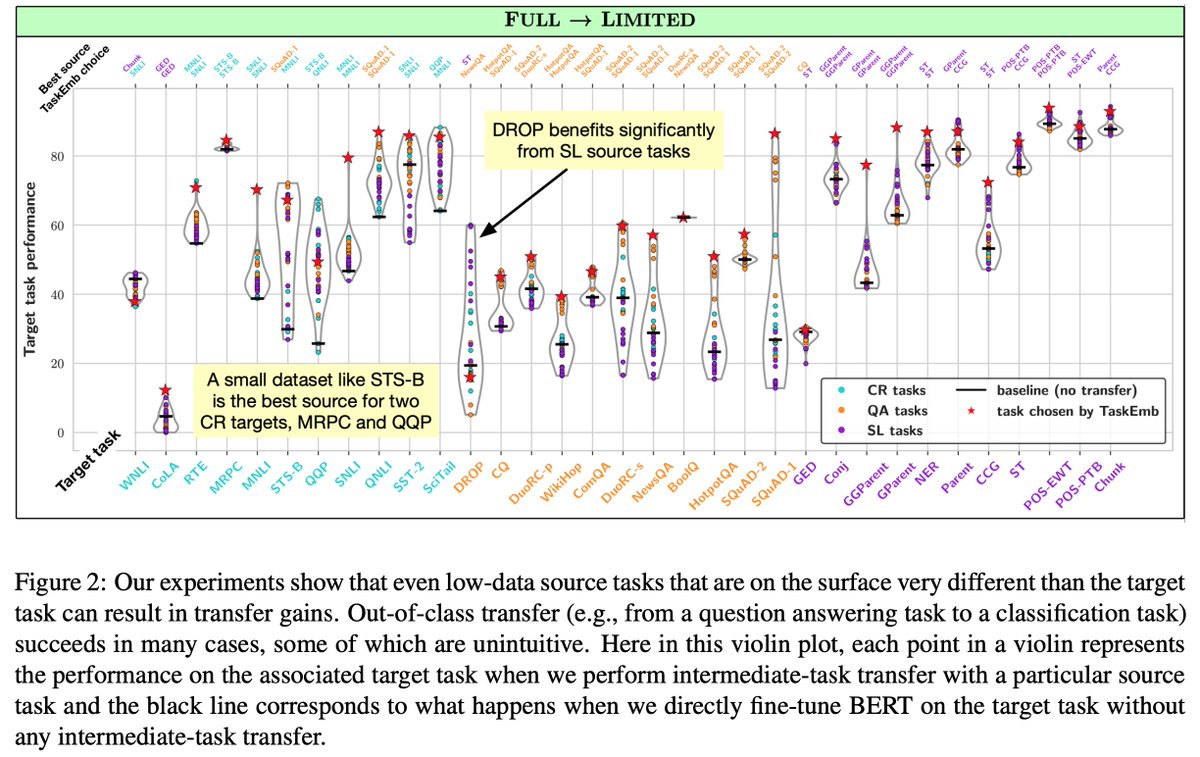
With STraTA, we are able to substantially improve sample efficiency across 12 NLP benchmark datasets. Remarkably, when given only 8 labeled examples per class from the SST-2 sentiment dataset, our approach is competitive with standard fine-tuning on all 67K labeled examples.
Other interesting results:
1) randomly initialized model + STraTA outperforms BERT_BASE by a large margin on SST-2 while being competitive on SciTail.
2) BERT_BASE + STraTA substantially outperforms BERT_LARGE on both SST-2 and SciTail.
1) randomly initialized model + STraTA outperforms BERT_BASE by a large margin on SST-2 while being competitive on SciTail.
2) BERT_BASE + STraTA substantially outperforms BERT_LARGE on both SST-2 and SciTail.
• • •
Missing some Tweet in this thread? You can try to
force a refresh