Why does model often attend to salient words even though it's not required by the training loss? To understand this inductive bias we need to analyze the optimization trajectory🧐
Sharing our preprint "Approximating How Single Head Attention Learns" #NLProc
Sharing our preprint "Approximating How Single Head Attention Learns" #NLProc
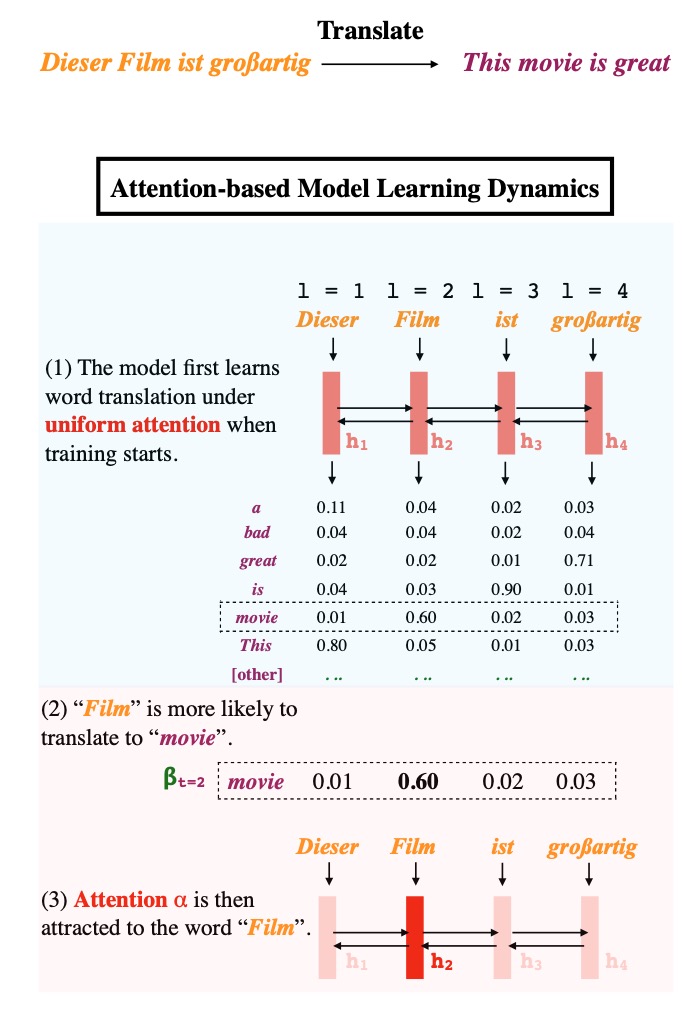
We approximate with 2 stages: early in training when attentions are uniform, the model learns to translate individual input word `i` to `o` if they co-occur frequently. Later, the model learns to attend to `i` while the correct output is o because it knows `i` translates to `o`.
All approximations are "wrong" (and apparently reviewers do not like our assumptions), but we are able to explain many existing empirical phenomena as well as predicting new ones: with our theory, we construct a distribution that is easy to express but hard to learn.
Takeaways: to understand many interesting properties of neural network, we not only need to understand the expressiveness of the models and the already trained models, we also need to understand the optimization trajectory!
Paper: arxiv.org/pdf/2103.07601… , joint work with @sea_snell , Dan Klein, and @JacobSteinhardt
REJECTED by EMNLP 2020, NAACL 2021, and #EMNLP2021 , but I love it more than most of my prior accepted works :) Time will tell its impact.
REJECTED by EMNLP 2020, NAACL 2021, and #EMNLP2021 , but I love it more than most of my prior accepted works :) Time will tell its impact.
Caveat: this theoretical framework only captures some (important) aspects of the system, and is far from a perfect approximation of what happened
• • •
Missing some Tweet in this thread? You can try to
force a refresh