
Memory Efficient Coding in #PyTorch ⚡
20 tricks to optimize your PyTorch code
Let's break some of the bad habits while writing PyTorch code 👇
A thread 🧵
20 tricks to optimize your PyTorch code
Let's break some of the bad habits while writing PyTorch code 👇
A thread 🧵
1. PyTorch dataloader supports asynchronous data loading in a separate worker subprocess. Set pin_memory=True to instruct the DataLoader to use pinned memory which enables faster and asynchronous memory copy from host to GPU 

2. Disable gradient calculation for validation or inference. Gradients aren't needed for inference or validation, so perform them within torch.no_grad() context manager.

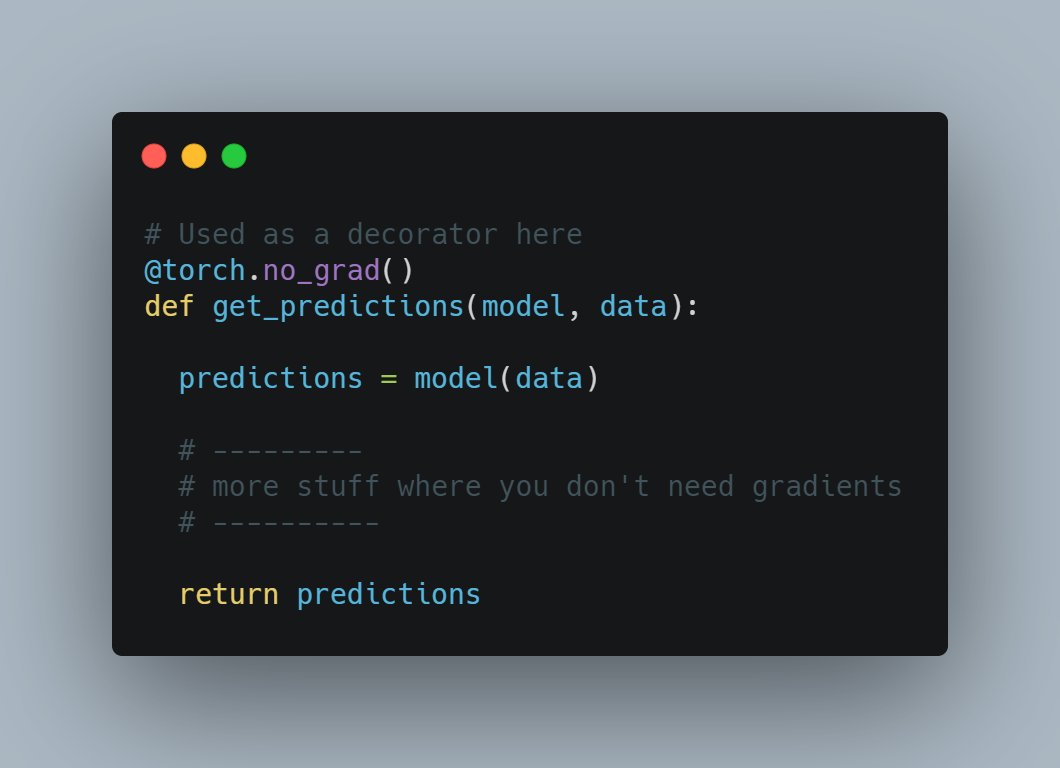
3. You can even use torch.no_grad() as a function decorator if you are doing forward pass in a function multiple times
4. Instead of zeroing out the gradients, set it to None 👇

5. Disable bias for convolutions directly followed by batch norm
nn.Conv2d() has bias default to True, but if any of the conv layers is followed by a BatchNorm layer, then bias is not needed as batchnorm effectively cancels out the effect of bias.
nn.Conv2d() has bias default to True, but if any of the conv layers is followed by a BatchNorm layer, then bias is not needed as batchnorm effectively cancels out the effect of bias.
6. Fuse pointwise operations
Pointwise operations (elementwise addition, multiplication, math functions) can be fused into a single kernel to reduce memory access and kernel launch time
Pointwise operations (elementwise addition, multiplication, math functions) can be fused into a single kernel to reduce memory access and kernel launch time

7. Avoid frequent CPU to GPU transfers

8. Use .detach() to clear up attached computational graph
9. Construct tensors directly on the device (GPU)
In the first case, a tensor is created on the CPU first and then it is transferred to GPU, which is slow. Directly construct tensors on GPU.
In the first case, a tensor is created on the CPU first and then it is transferred to GPU, which is slow. Directly construct tensors on GPU.

10. Use DistributedDataParaller instead of DataParallel while training on multiple GPUs. In DataParallel (DP), the model is copied to each GPU, whereas in DDP a siloed copy of the model is created on each GPU (in its own process).
11. Use Automatic Mixed Precision. AMP is natively available in PyTorch since the 1.6 release. It speeds up training (3x faster) on certain GPUs (V100, 2080Ti), those having volta and ampere architecture. Also, it can reduce memory usage and you can use a larger batch size.
12. Delete unnecessary variables, objects, classes, lists, dictionaries using python keyword del

13. Use gc.collect() to free up your RAMs memory when you are done running the training/inference script. Note, using gc.collect() in between the program can delete important variables and can corrupt your data or crash your program. Use it cautiously
14. Use torch.cuda.empty_cache() to clear up GPU memory at the end of training or inference routine
14. Use larger batch sizes as much as you can fit in your memory, your GPU utilization should be 100% most of the time, to reduce bottlenecks. However, a much larger batch size could hurt the performance of your model (in terms of metrics), so see what works best for you
15. Optimize the loading and preprocessing of data as much as possible, your GPU should be kept working at all times, it shouldn't be idle waiting for data
16. Use OpenCV to read images, it is faster than PyTorch's default PIL backend
17. Turn on cudNN benchmarking, this helps if your models are making heavy use of convolutional layers

18. Profile your code using PyTorch profiler which tells you where most of the time is spent in your code, then you can optimize the code accordingly
19. If you are processing huge CSV files, pandas is slow as it runs on CPU. Use @RAPIDSai (cuDF) instead to preprocess data on GPU, which is a lot faster.
20. If you want all of the above-mentioned optimizations without having any overhead, use @PyTorchLightnin, they do it all for you :)
Hope this thread helped you and now you can reduce training time and avoid bottlenecks, by using the above-mentioned optimizations which in turn increases the rate of experimentations. Happy PyTorching !!!!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


