🧐7 things you should know about the Focal Loss:
📌 It was introduced in the RetinaNet paper to address the foreground-background class imbalance encountered during training of dense detectors (one-stage detectors)
...
📌 It was introduced in the RetinaNet paper to address the foreground-background class imbalance encountered during training of dense detectors (one-stage detectors)
...

📌 It’s derived from the cross-entropy loss such that it down-weights the loss assigned to well-classified examples. It's used in the classification head.
📌 It’s used in many one-stage object detection models: EfficientDet, FCOS, VFNet, and many other models
📌 It’s used in many one-stage object detection models: EfficientDet, FCOS, VFNet, and many other models
📌 It can also be used in two-stage object detection models: e.g. Sparse R-CNN
📌 It crashes losses associated to easy examples: for a confidence score of 0.9, the focal loss is 100 times smaller than the cross-entropy loss (see figure here above)
📌 It crashes losses associated to easy examples: for a confidence score of 0.9, the focal loss is 100 times smaller than the cross-entropy loss (see figure here above)
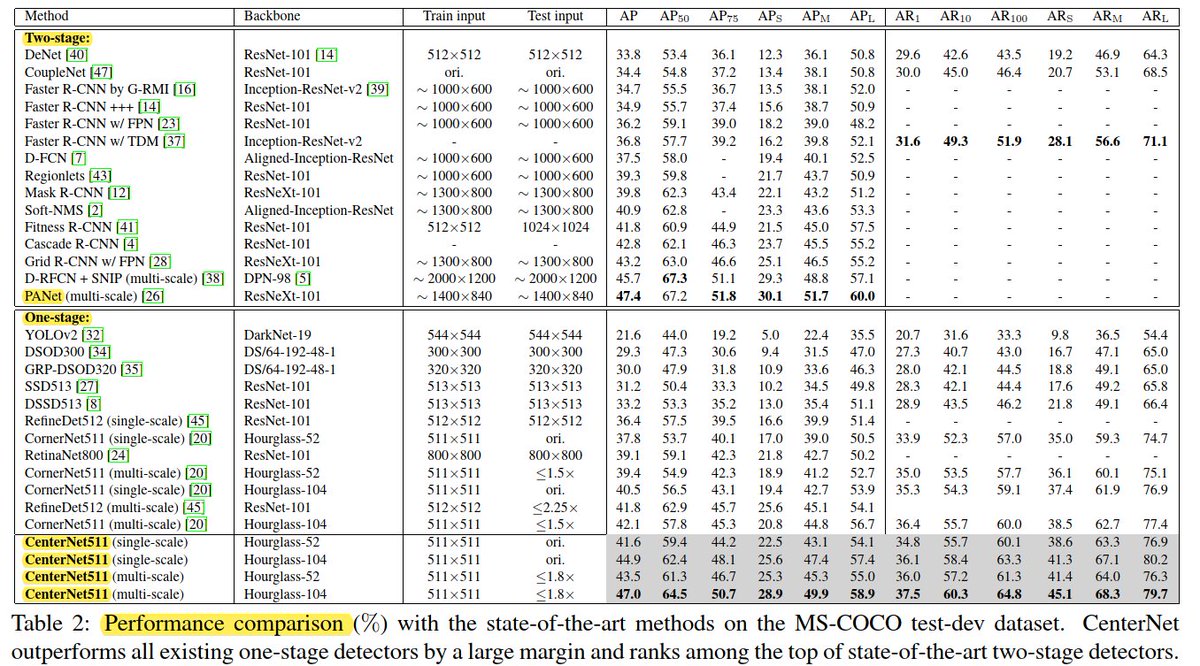
📌 Thanks to the focal loss, RetinaNet was the first one-stage detector model to beat two-stage detector models
📌 Focal loss can also be used in classification centered tasks (not only in object detection tasks)
🤔 Are there other things you would add to this list?
📌 Focal loss can also be used in classification centered tasks (not only in object detection tasks)
🤔 Are there other things you would add to this list?
Thanks for passing by!
🟧Def Follow @ai_fast_track for more stuff on Object Detection
🟦and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
🟧Def Follow @ai_fast_track for more stuff on Object Detection
🟦and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
https://twitter.com/ai_fast_track/status/1452672706986582016
• • •
Missing some Tweet in this thread? You can try to
force a refresh