✨Common Object Detector Architecture you should be familiar with:
📌 Common object detectors are divided into One-Stage Detectors (OSD), and Two-Stage Detectors (TSD)
📌 Both OSD and TSD can be either anchor-based (relying on anchor boxes) or anchor-free
📌 Common object detectors are divided into One-Stage Detectors (OSD), and Two-Stage Detectors (TSD)
📌 Both OSD and TSD can be either anchor-based (relying on anchor boxes) or anchor-free

📌 OSD use the whole feature maps to predict bounding boxes/labels: Dense Prediction
📌 TSD have an extra step hence two-stage: extracting proposals (regions of interest)
📌 Proposals are used to extract feature map regions to predict bounding boxes/labels: Sparse Prediction
📌 TSD have an extra step hence two-stage: extracting proposals (regions of interest)
📌 Proposals are used to extract feature map regions to predict bounding boxes/labels: Sparse Prediction
📌 TSD don't use the whole feature map for prediction
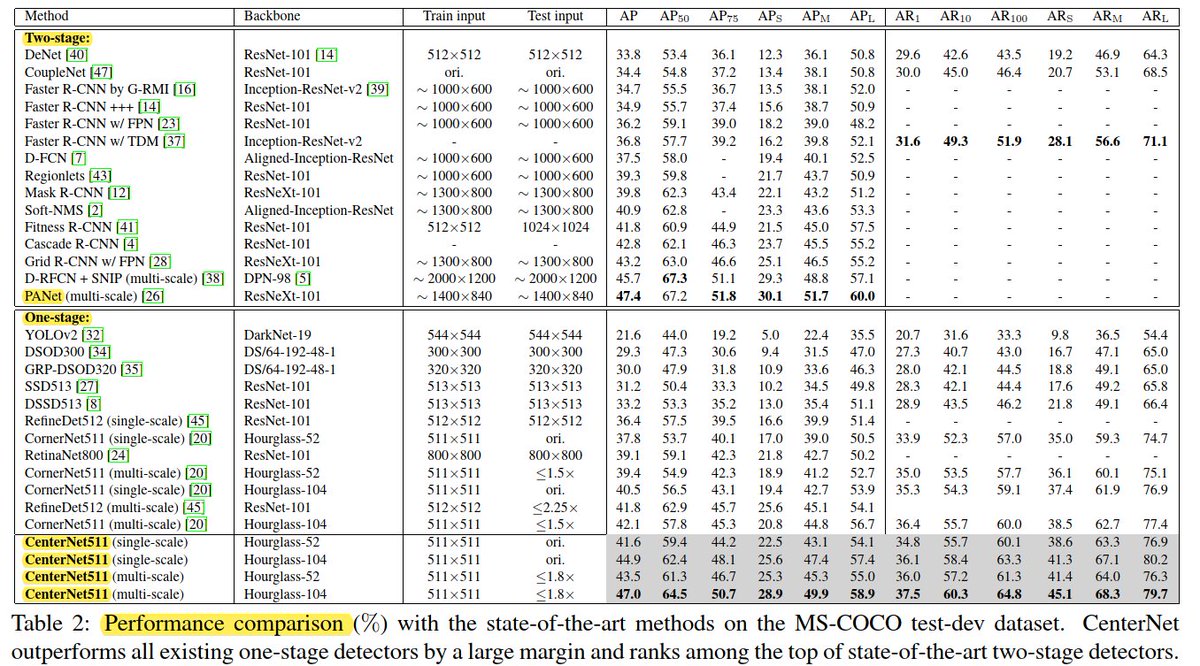
📌 TSD (e.g. Faster R-CNN) used to be more accurate than STD (e.g. SSD, YOLO, etc.)
📌 STD (e.g. EfficientDet, RetinaNet, VFNet, YOLOX, etc.) recently show better results than TSD
📌 STD are faster than TSD
📌 TSD (e.g. Faster R-CNN) used to be more accurate than STD (e.g. SSD, YOLO, etc.)
📌 STD (e.g. EfficientDet, RetinaNet, VFNet, YOLOX, etc.) recently show better results than TSD
📌 STD are faster than TSD
🔥IceVision supports most of the models shown in the figure.
Come and join our friendly/helpful community!
⌨IceVision: github.com/airctic/IceVis…
🍕Forum: discord.gg/JDBeZYK
Come and join our friendly/helpful community!
⌨IceVision: github.com/airctic/IceVis…
🍕Forum: discord.gg/JDBeZYK
Thanks for passing by!
🟧 Def Follow @ai_fast_track for more stuff on Object Detection
🟦 and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
🟧 Def Follow @ai_fast_track for more stuff on Object Detection
🟦 and if you could give the thread a quick retweet, it will help other people catch this content in their feed 🙏
https://twitter.com/ai_fast_track/status/1453368771285032971
• • •
Missing some Tweet in this thread? You can try to
force a refresh