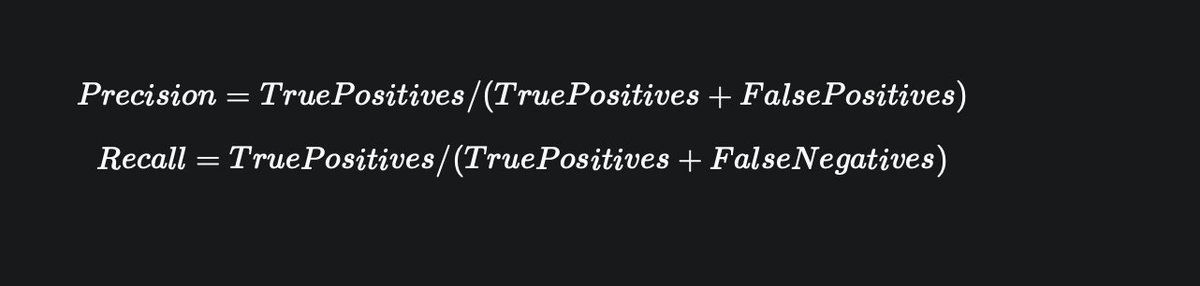One of the things that makes training neural networks hard is the number of choices that we have to make before & during training.
Here is a training guideline covering:
◆Architectural choice
◆Activations
◆Losses
◆Optimizers
◆Batch size
◆Training & debugging recipes
🧵🧵
Here is a training guideline covering:
◆Architectural choice
◆Activations
◆Losses
◆Optimizers
◆Batch size
◆Training & debugging recipes
🧵🧵
1. ARCHITECTURAL CHOICE
The choice of neural network architecture is primarily guided by data and the problem at hand.
The choice of neural network architecture is primarily guided by data and the problem at hand.
Unless you are researching a new architecture, here are the popular conventions:
◆Tabular data: Feedforward networks (or Multi-layer perceptrons)
◆Images: 2D Convolutional neural networks (Convnets), Vision-transformers(ongoing research)
◆Tabular data: Feedforward networks (or Multi-layer perceptrons)
◆Images: 2D Convolutional neural networks (Convnets), Vision-transformers(ongoing research)
◆Texts: Recurrent Neural Networks(RNNs), transformers, or 1D Convnets.
◆Time-series: RNNs or 1D Convnets
◆Videos & volumetric images: 3D Convnets, or 2D Convnets (with video divided into frames)
◆Sound: 1D Convnets or RNN
◆Time-series: RNNs or 1D Convnets
◆Videos & volumetric images: 3D Convnets, or 2D Convnets (with video divided into frames)
◆Sound: 1D Convnets or RNN
2. ACTIVATION FUNCTIONS
Activations are non-linear mathematical functions that are used to introduce non-linearities in the network.
Why do we need non-linearities? Well, the real-world datasets are rarely linear. In order to model them, we got to use non-linear activations.
Activations are non-linear mathematical functions that are used to introduce non-linearities in the network.
Why do we need non-linearities? Well, the real-world datasets are rarely linear. In order to model them, we got to use non-linear activations.
There are many activation functions such as Sigmoid, Tanh, ReLU, Leaky ReLU, GeLU, SeLU, etc...
Here are important notes about choosing activation function:
◆Avoid using sigmoid or tanh as they can kill or cause gradients to vanish. That can slow the learning.
Here are important notes about choosing activation function:
◆Avoid using sigmoid or tanh as they can kill or cause gradients to vanish. That can slow the learning.
◆Always try ReLU at first. It works well most of the time. If you feel you need a boost in the accuracy, try Leaky ReLU, SELU, ELU. These are special versions of ReLU and can turn out to work well too or even better, but there is no guarantee.
◆The difference that the choice of activation function makes in the results is very small. Don't stress over which one is the best!
◆While choosing activations functions for the last output layer,
...Sigmoid: Binary classification, multi-label classification
...Softmax: Multiclass classification
...Sigmoid: Binary classification, multi-label classification
...Softmax: Multiclass classification
3. LOSSES
Loss functions are used to measure the distance between the predictions and actual output during training.
The commonly used loss function in classification problems is cross-entropy.
Loss functions are used to measure the distance between the predictions and actual output during training.
The commonly used loss function in classification problems is cross-entropy.
3 types of cross-entropy:
◆Binary cross-entropy: For binary classification, and when the activation of the last layer is sigmoid.
◆Categorical cross-entropy: Mostly for multi-class classification problems and used when labels are given in one hot format(0's and 1's).
◆Binary cross-entropy: For binary classification, and when the activation of the last layer is sigmoid.
◆Categorical cross-entropy: Mostly for multi-class classification problems and used when labels are given in one hot format(0's and 1's).
◆Sparse categorical cross-entropy: Mostly for multi-class classification problems and used when labels are given in integer format.
4. OPTIMIZERS
Optimization functions are used to minimize the loss during the training.
The most popular optimizers are Stochastic Gradient Descent(SGD), AdaGrad, RMSprop, Adam, Nadam, and AdaMax.
Optimization functions are used to minimize the loss during the training.
The most popular optimizers are Stochastic Gradient Descent(SGD), AdaGrad, RMSprop, Adam, Nadam, and AdaMax.
Unlike SGD, all other mentioned optimizers are adaptive to learning rates which means they can converge faster.
Try Adam first. If it doesn't converge faster, try Nadam or AdaMax, or RMSprop. They can also work well too.
Try Adam first. If it doesn't converge faster, try Nadam or AdaMax, or RMSprop. They can also work well too.
There is no right or wrong optimizer. Try many of them (starting from Adam) and then others...
5. BATCH SIZE
Surprisingly, the batch size is a critical thing in neural network training. It can speed up or slow the training or influence the performance of the network.
Surprisingly, the batch size is a critical thing in neural network training. It can speed up or slow the training or influence the performance of the network.
The large batch size can speed up training because you are feeding many samples to the model at once, but there is also a risk of running into instabilities.
The small batch size can slow the training, but it can result in a better generalization.
What can we conclude about the batch size?
◆Use a small batch size. The network can generalize better and the training is stable as well. Try something like 32 or below.
Find more about the benefit of small batch size in this paper
arxiv.org/abs/1804.07612
◆Use a small batch size. The network can generalize better and the training is stable as well. Try something like 32 or below.
Find more about the benefit of small batch size in this paper
arxiv.org/abs/1804.07612
◆Try a large batch size if you have a very big dataset like imagenet :) and you want to train in 1 hour or less.
But it's computationally expensive. This paper trained Imagenet using a large batch size of 8192 in 1 hour but it took 256 GPUs.
arxiv.org/abs/1706.02677
arxiv.org/abs/1706.02677
Looking at the above paper and others that tried to compete with it, batch size, GPU, and training time are pretty relational.
You too can also train Imagenet in 15 minutes if you multiply the batch size of 8192 by 4 and 256 GPUs by 4. I personally can't afford that!
You too can also train Imagenet in 15 minutes if you multiply the batch size of 8192 by 4 and 256 GPUs by 4. I personally can't afford that!
6. SOME TRAINING AND DEBUGGING IDEAS
It's super hard to train neural networks. There is no clear framework for almost every choice you are supposed to make.
Randomly feeding images to ConvNets does not produce magical results.
It's super hard to train neural networks. There is no clear framework for almost every choice you are supposed to make.
Randomly feeding images to ConvNets does not produce magical results.
Here are some training recipes and debugging ideas:
◆Become one with data
◆Overfit a tiny dataset
◆Visualize the model(TensorBoard is pretty good at this)
◆Visualize the samples that the model got wrong. Find why the model failed them. Fix their labels if that's the cause.
◆Become one with data
◆Overfit a tiny dataset
◆Visualize the model(TensorBoard is pretty good at this)
◆Visualize the samples that the model got wrong. Find why the model failed them. Fix their labels if that's the cause.
◆If the training error is low, and the validation error is high, the model is overfitting.
Regularize the model with techniques like dropout, early-stopping, or adding more data. Or augment training data.
Regularize the model with techniques like dropout, early-stopping, or adding more data. Or augment training data.
◆If the training error is high and the validation error is also high, train longer, increase the model size or try a large model.
For more about recipes and ideas for training neural networks, I highly recommend you read this blog by @karpathy.
A Recipe for Training Neural Networks:
karpathy.github.io/2019/04/25/rec…
A Recipe for Training Neural Networks:
karpathy.github.io/2019/04/25/rec…
Thanks for reading.
If you found the thread helpful, retweet and share it with your friends. That's certainly the best way to support me.
Follow @Jeande_d for more machine learning ideas!
If you found the thread helpful, retweet and share it with your friends. That's certainly the best way to support me.
Follow @Jeande_d for more machine learning ideas!
• • •
Missing some Tweet in this thread? You can try to
force a refresh