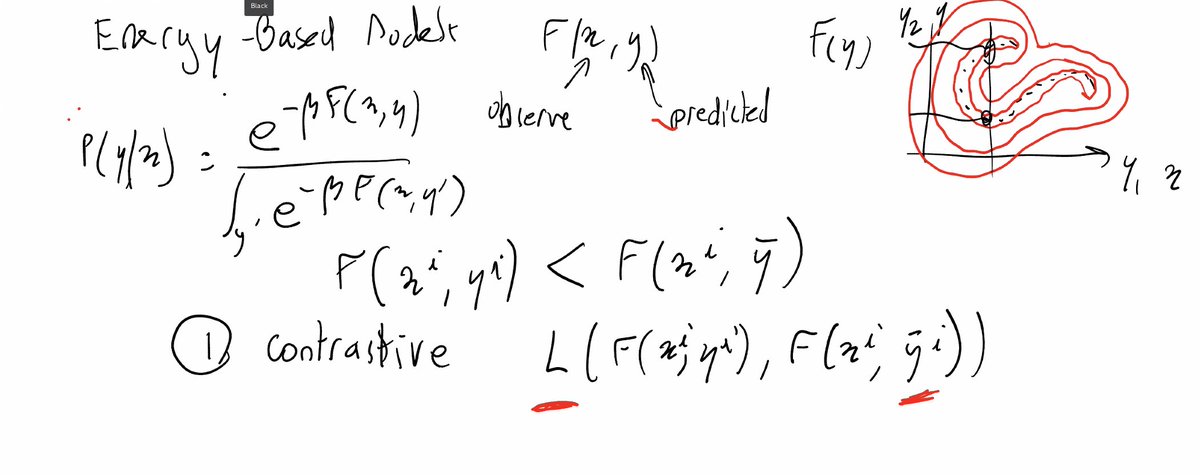
1. "A 3D Generative Model for Structure-Based Drug Design" is one of the multiple papers at NeurIPS about drug discovery using neural networks.
This model generates molecules that bind to a specific protein binding site.
By Shitong Luo et al.
papers.nips.cc/paper/2021/has…
This model generates molecules that bind to a specific protein binding site.
By Shitong Luo et al.
papers.nips.cc/paper/2021/has…

2. "The Emergence of Objectness: Learning Zero-shot Segmentation from Videos" by Runtao Liu et al.
Leveraging clever self supervision with videos to segment objects without labels.
papers.nips.cc/paper/2021/has…
Leveraging clever self supervision with videos to segment objects without labels.
papers.nips.cc/paper/2021/has…

3. "Multimodal Few-Shot Learning with Frozen Language Models" by @jacobmenick @serkancabi @arkitus @OriolVinyalsML @FelixHill84 .
Freeze a pre-trained LM and train a vision encoder for prompting the LM to perform vision/language tasks.
papers.nips.cc/paper/2021/has…
Freeze a pre-trained LM and train a vision encoder for prompting the LM to perform vision/language tasks.
papers.nips.cc/paper/2021/has…

4. "Efficient Training of Retrieval Models using Negative Cache" by Erik Lindgren et al.
A proposal to train dense retrieval without needing huge batches and a lot of memory.
papers.nips.cc/paper/2021/has…
A proposal to train dense retrieval without needing huge batches and a lot of memory.
papers.nips.cc/paper/2021/has…

5. "VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text" by @AkbariH70 Liangzhe Yuan @RuiQian3 Wei-Hong Chuang, Shih-Fu Chang, @YinCui1 @BoqingGo.
The promised multimodal future is here!
papers.nips.cc/paper/2021/has…
The promised multimodal future is here!
papers.nips.cc/paper/2021/has…

6. "Robust Predictable Control" by @ben_eysenbach, @rsalakhu and @svlevine.
Seing RL through the lens of compression. How do agents behave when they favor policies that are compressible (i.e. easy to predict)?
papers.nips.cc/paper/2021/has…
Seing RL through the lens of compression. How do agents behave when they favor policies that are compressible (i.e. easy to predict)?
papers.nips.cc/paper/2021/has…

7. "FLEX: Unifying Evaluation for Few-Shot NLP" by Jonathan Bragg et al.
Now we can apples-to-apples comparisons of few-shot performance!
papers.nips.cc/paper/2021/has…
Now we can apples-to-apples comparisons of few-shot performance!
papers.nips.cc/paper/2021/has…

8. "Partition and Code: learning how to compress graphs" by @gbouritsas @loukasa_tweet @AspectStalence @mmbronstein
How would you build a native compression algorithm for graphs? -> partition and code
papers.nips.cc/paper/2021/has…
How would you build a native compression algorithm for graphs? -> partition and code
papers.nips.cc/paper/2021/has…

9. "Learning to Draw: Emergent Communication through Sketching" by @DanielaMihai13 and @jon_hare
How two models pretty much learn to play Pictionary.
papers.nips.cc/paper/2021/has…
How two models pretty much learn to play Pictionary.
papers.nips.cc/paper/2021/has…

10. "Fixes That Fail: Self-Defeating Improvements in Machine-Learning Systems" by Ruihan Wu et al.
Watch out! Improving parts of an ML model might lead to worse overall performance...😔
papers.nips.cc/paper/2021/has…
Watch out! Improving parts of an ML model might lead to worse overall performance...😔
papers.nips.cc/paper/2021/has…

Read our comments on this selection and more interesting papers on our blog zeta-alpha.com/post/neurips-2…
• • •
Missing some Tweet in this thread? You can try to
force a refresh