GPT-3 Embeddings by @OpenAI was announced this week.
📈 I was excited and tested them on 20 datasets
😢 Sadly they are worse than open models that are 1000 x smaller
💰 Running @OpenAI models can be a 1 million times more expensive
tinyurl.com/gpt3-emb
📈 I was excited and tested them on 20 datasets
😢 Sadly they are worse than open models that are 1000 x smaller
💰 Running @OpenAI models can be a 1 million times more expensive
tinyurl.com/gpt3-emb
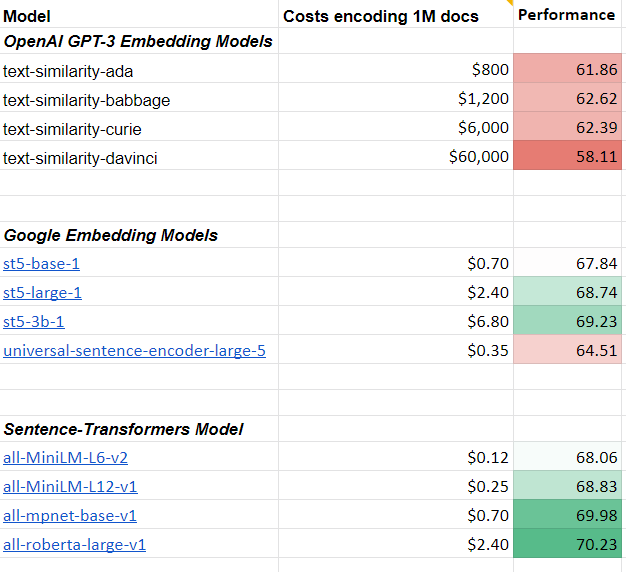
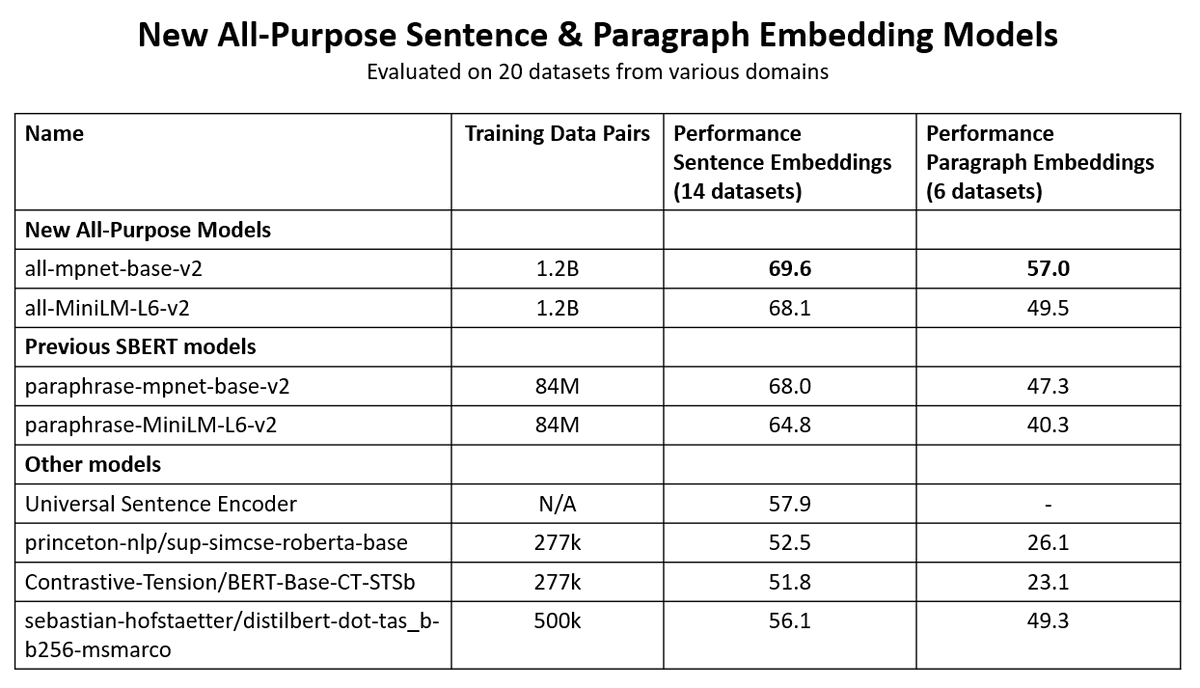
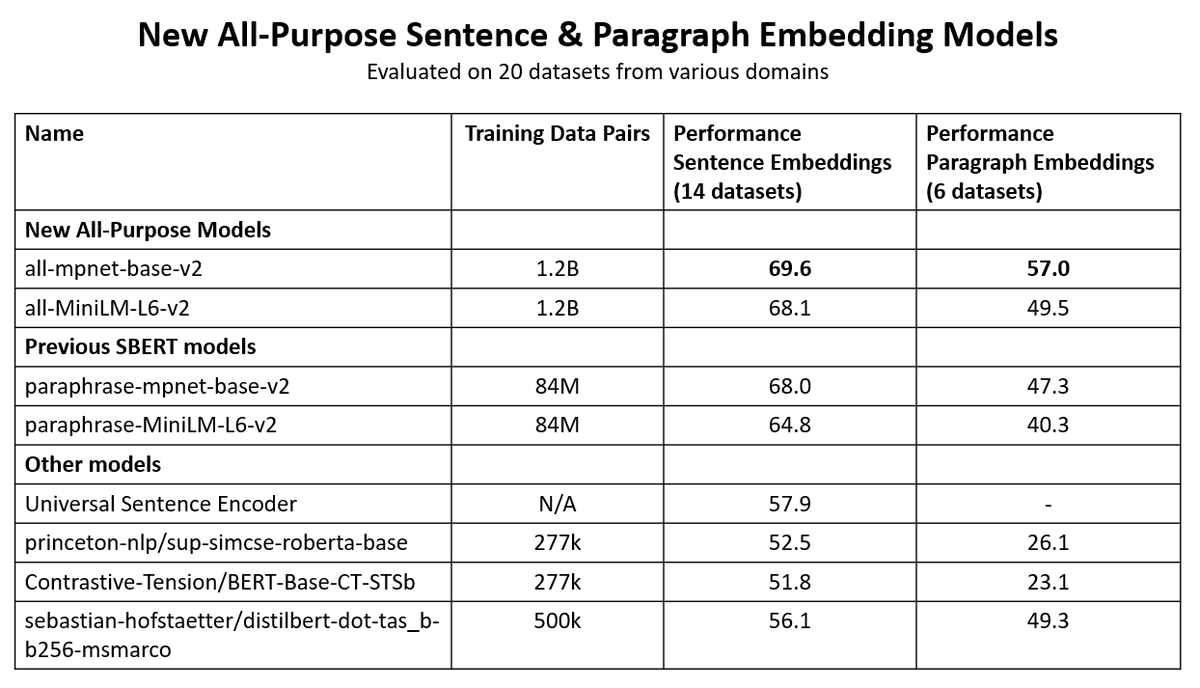
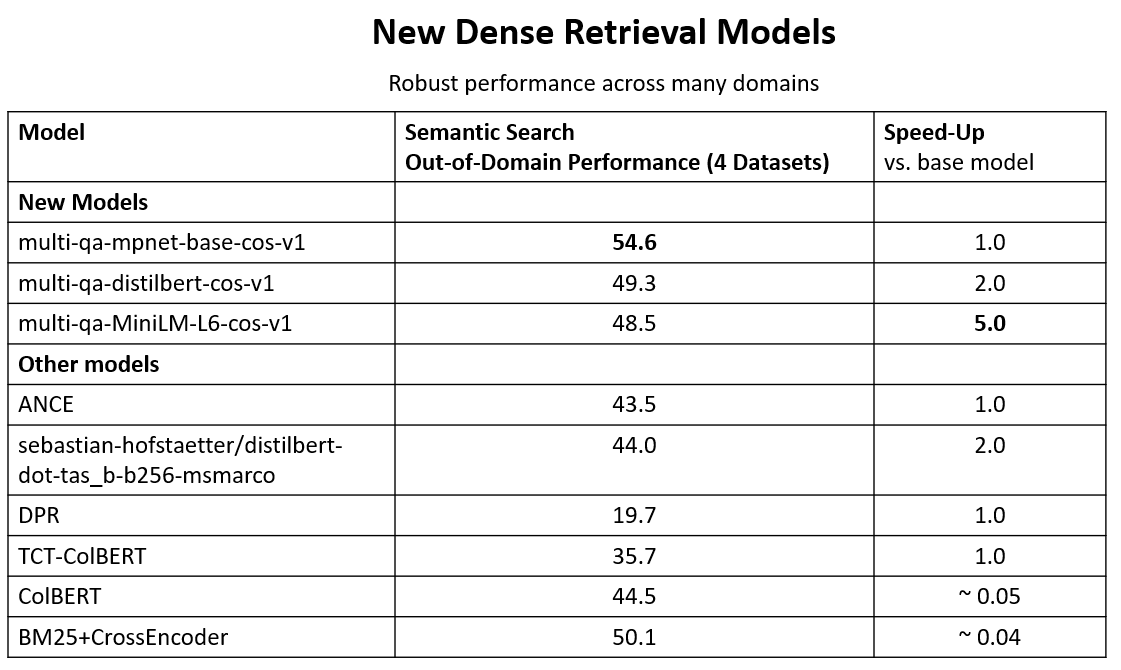
I tested the text similarity models on 14 datasets from different domains (emails, papers, online communities) on various tasks (clustering, retrieval, paraphrase mining).
The 175B model is actually worse than a tiny MiniLM 22M parameter model that can run in your browser.
The 175B model is actually worse than a tiny MiniLM 22M parameter model that can run in your browser.
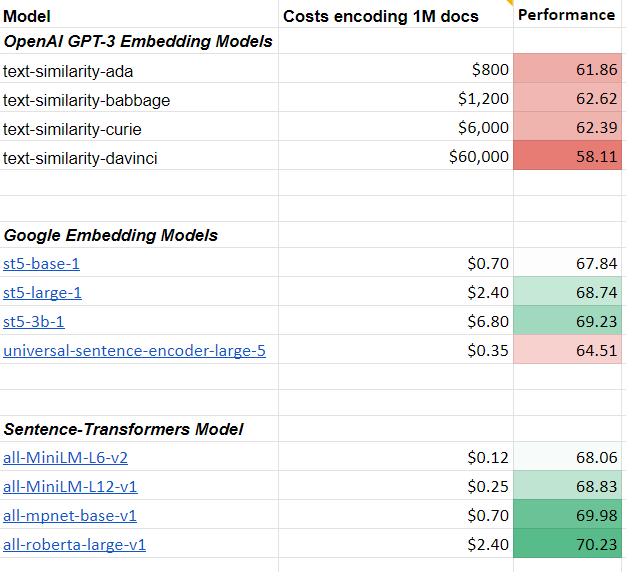
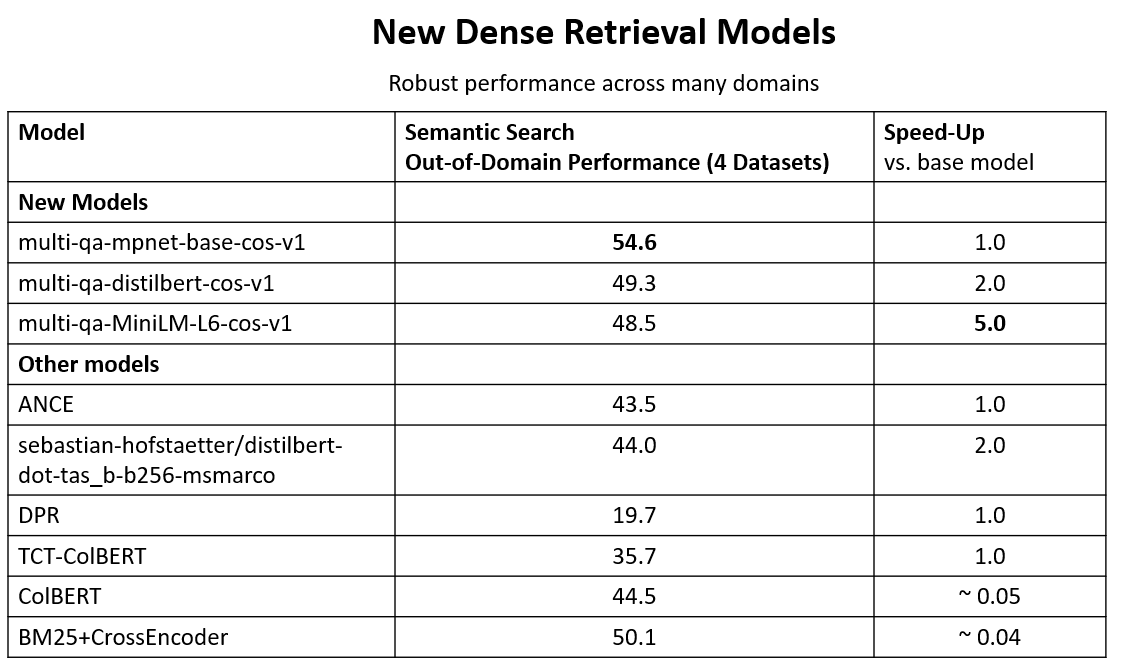
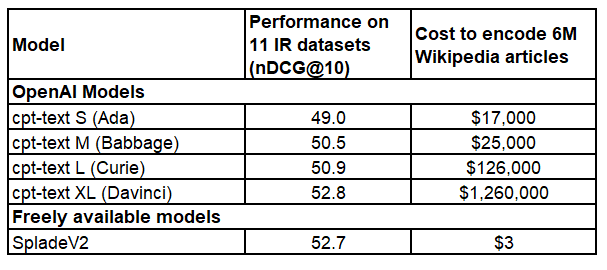
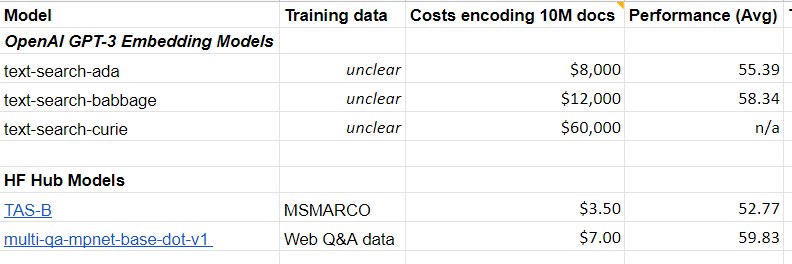
Next, I tested the text-search models. Here the results look well for a dense model.
However, when compared to the state-of-the-art sparse model of SpladeV2, which is 2600x smaller, you just get an 0.1 improvement.
💰 Encoding costs? $1,000,000 for GPT-3 vs. $3 for SpladeV2
However, when compared to the state-of-the-art sparse model of SpladeV2, which is 2600x smaller, you just get an 0.1 improvement.
💰 Encoding costs? $1,000,000 for GPT-3 vs. $3 for SpladeV2
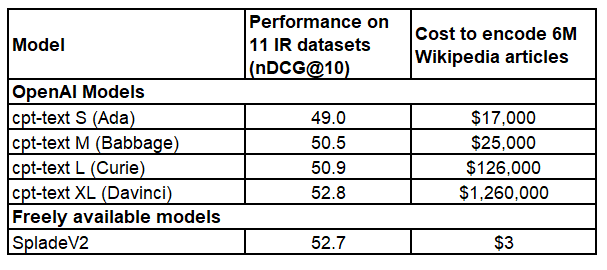
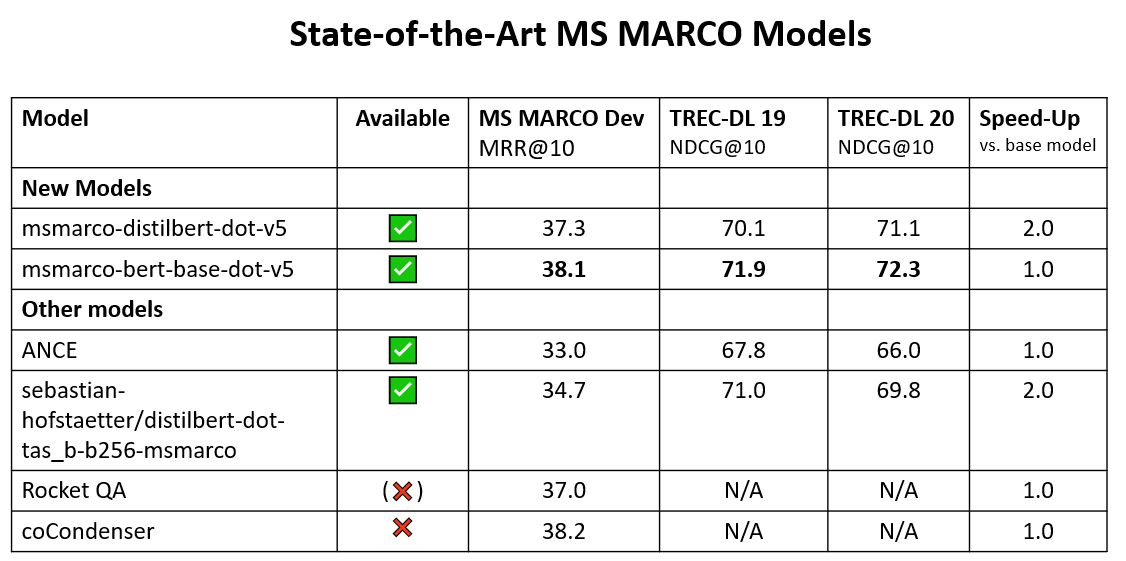
When evaluated on 6 (query/questions, paragraph)-tasks, the OpenAI 2.7B & 6.7B parameter models perform on par with an open 110M parameter model (MPNet). Again, encoding costs are about 1000 higher.
The @OpenAI embedding models produce extremely high dimensional vector spaces of up to 12288 dimensions.
The issue: With more dimensions, your machine requires a lot more memory ($$$) to host such a vector space and operations like search is a lot slower.
The issue: With more dimensions, your machine requires a lot more memory ($$$) to host such a vector space and operations like search is a lot slower.

My advice:
💰 Safe the $1,000,000 you would need to spend to encode your corpus with GPT-3
📄 Spent $1000 and annotate task specific data
🆓Fine-tune an open model
🎉 Use the $999,000 saving to treat your team
💰 Safe the $1,000,000 you would need to spend to encode your corpus with GPT-3
📄 Spent $1000 and annotate task specific data
🆓Fine-tune an open model
🎉 Use the $999,000 saving to treat your team
You can find the full analysis, further details, more results & explanations, and links to the alternative open models in the blog post:
tinyurl.com/gpt3-emb
tinyurl.com/gpt3-emb
• • •
Missing some Tweet in this thread? You can try to
force a refresh