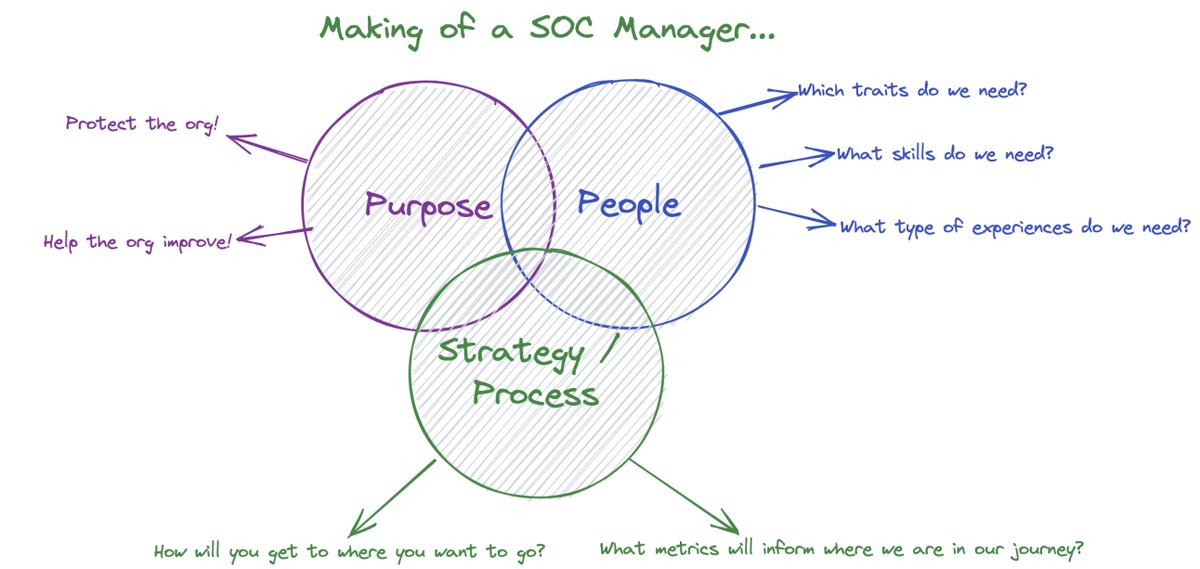
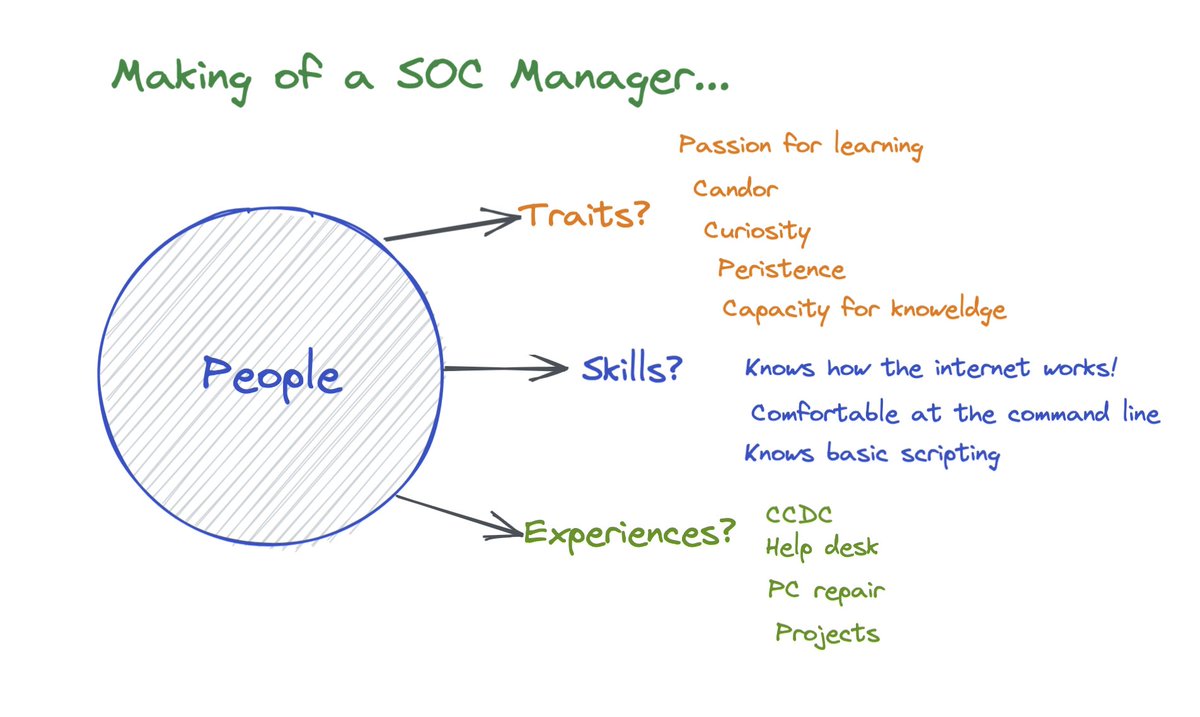
Once a month we get in front of our exec/senior leadership team and talk about #SOC performance relative to our business goals (grow ARR, retain customers, improve gross margin).
A 🧵on how we translate business objectives to SOC metrics.
A 🧵on how we translate business objectives to SOC metrics.

As a business we want to grow Annual Recurring Revenue (ARR), retain and grow our customers (Net Revenue Retention - NRR) and improve gross margin (net sales minus the cost of services sold). There are others but for this thread we'll focus on ARR, NRR, and gross margin.
/1
/1
I think about growing ARR as the ability to process more work. It's more inputs. Do we have #SOC capacity available backed by the right combo of tech/people/process to service more work?
Things that feed more work: new customers, cross selling, new product launches.
/2
Things that feed more work: new customers, cross selling, new product launches.
/2

Since +ARR is about the ability to handle more work, we use time series decomp to split alerts we triage into 3 pieces: trend, seasonality and residuals. We analyze the trend, the general directional movement, and understand what's happening and how much capacity available.
/3
/3

When we increase work (grow ARR) the amount of noise in our alert mgmt process increases. Think of noise as a runaway alert from a bad sig (it happens) or a bad vendor rule push. We use a control chart based to understand if our alert mgmt process is under control. /4

As the amount of noise increases in our alert mgmt process we counter it. Things like, "auto create an investigation and setup rules to add these alerts" when we experience a runaway alert. Runaway alerts impact wait times more than a gradual increase in arrival rate. /5
Let's talk alert wait times. How long do alerts wait before 1st action? There's a ton of latency sensitivity in SecOps. We measure how long (in mins) it takes before we start working an alert. We measure using the 95th%. E.g., "95% of the time a HIGH sev alert waits 7 min".
/6
/6
As we increase ARR (add inputs) we can predict/simulate at what point we'll start to miss alert wait time SLOs. We counter that using tech/automation. But alert wait times are a leading indicator for a key NRR measure, alert-to-fix times.
/7
/7

In simple terms, to grow ARR we need to be able to process more work. We analyze the alert trend, volatility in our alert mgmt process and alert wait times to understand what's happened in the past to predict performance in the future. All to answer, "can we handle more work?"
/8
/8
Also, metrics in the ARR category (alert wait times) are a leading indicator for a key NRR metric, alert-to-fix times. If your alert wait times are getting longer, your alert-to-fix times will [eventually] start to degrade. More on that in a minute.
/9
/9
Before we talk about NRR let's talk gross margin. If alert vol and wait times are up, you might say, "just add more SOC analysts!". This action dilutes margin. Will we add people? Yes, of course. But we scale our business with tech/automation - intentional w/ people spend.
/10
/10
I think about NRR as "are we protecting our customers"? if we protect them, we will earn trust/maintain business. To protect them, alert-to-fix times <= 30 min and our work is of high quality. Alert-to-fix times are lagging indicators but your alert wait times are leading.
/11
/11
What I mean: if alerts are waiting longer it will eventually impact your alert-to-fix times. A Monte Carlo simulation will tell us when. Example, in Jan our alert-to-fix times for critical incidents was 19 min but medium alert wait times were +37% compared to a year ago
/12
/12

Putting it together, most recent exec update: increase of alerts in Jan - expected as we've onboarded more customers over the period. We've landed an alert similarity initiative and working w/ UX to improve scale/quality of alert triage.
/13
/13

We're seeing more noise (volatility) in our process - expected as we've onboarded more devices. To counter, we're going to explore auto create of investigations and setup rules to automatically move alerts from triage view to keep process stable. Alert wait times up.
/14
/14

Despite increase in wait times of lower sev alerts (leading indicator), no impact to alert-to-fix times (lagging indicator). Our tech/UX initiatives to handle alert vol are what protect/enable fast alert-to-fix times.
/15
/15

Bottom line: we're running at initiatives to improve scale/quality of triage, have capacity available, we're not at the point where we need to pull forward a hire (dilute margin). Can handle more inputs. Alert-to-fix times tell us we're protecting our customers.
/16
/16
Hopefully that was the least bit helpful for folks wondering how we think about mapping our business goals to initiatives and levers we have in our SOC that enable us to get there.
/17
/17
• • •
Missing some Tweet in this thread? You can try to
force a refresh