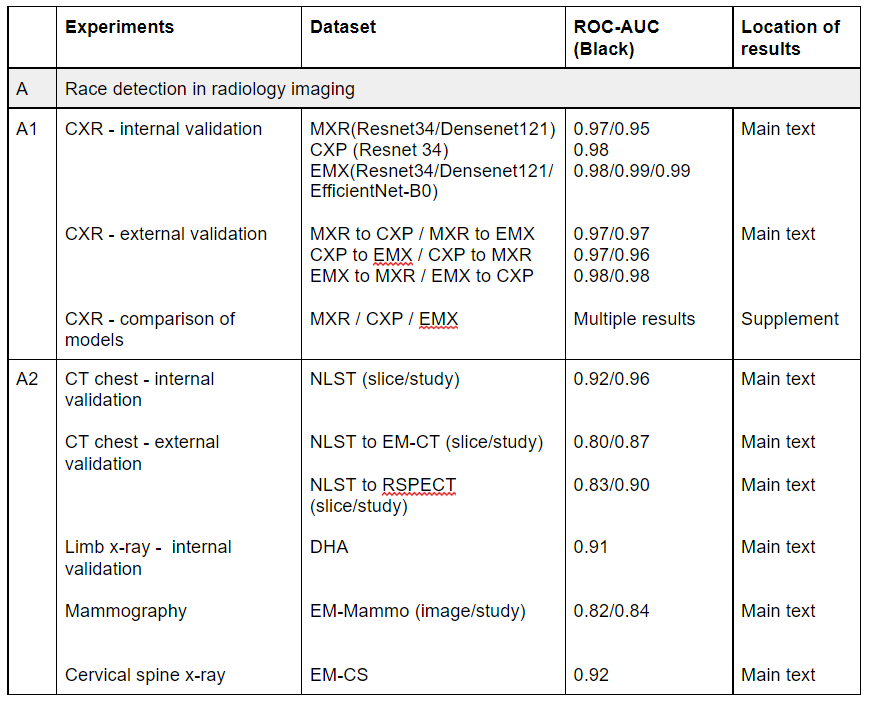
Very excited to have 2 new papers in press today in Lancet Digital Health, alongside an editorial from the journal highlighting our work.
I am immensely proud of the work we have done here and honestly think this is the most important work I have been involved in to date 🥳
1/7
I am immensely proud of the work we have done here and honestly think this is the most important work I have been involved in to date 🥳
1/7



#Medical #AI has a problem. Preclinical testing, including regulatory testing, does not accurately predict the risks that AI models pose once they are deployed in clinics.
I've written about this before in my blog, for example in:
google.com/amp/s/laurenoa…
2/7
I've written about this before in my blog, for example in:
google.com/amp/s/laurenoa…
2/7
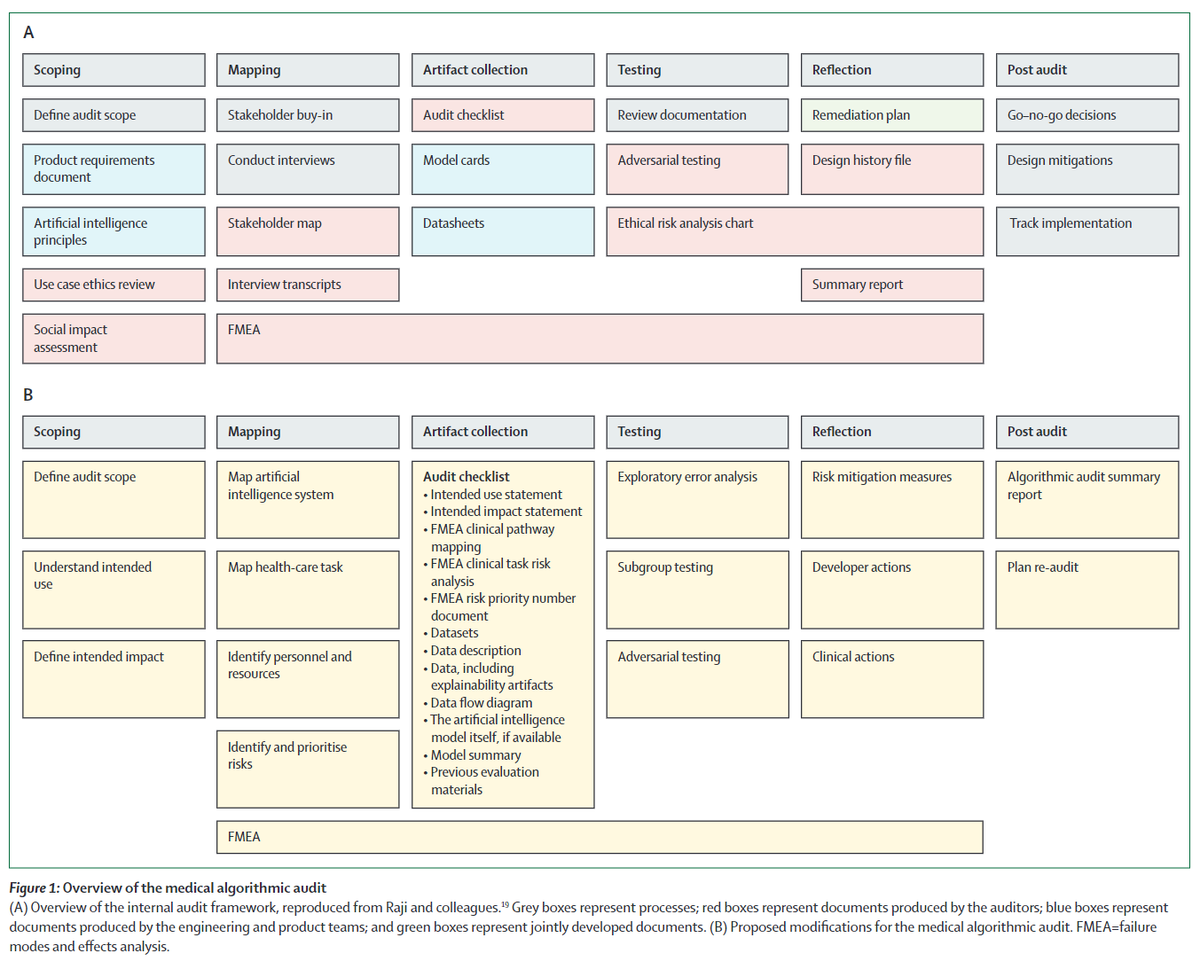
In this work we:
1) describe a step by step method for algorithmic auditing in health, building on the 🔥 work by Raji et al
2) audit a high accuracy model we developed @theAIML for hip fracture dx, ID-ing several serious risks that were not detected by standard testing.
3/7
1) describe a step by step method for algorithmic auditing in health, building on the 🔥 work by Raji et al
2) audit a high accuracy model we developed @theAIML for hip fracture dx, ID-ing several serious risks that were not detected by standard testing.
3/7
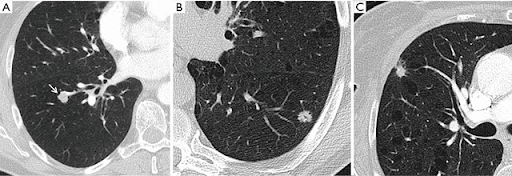
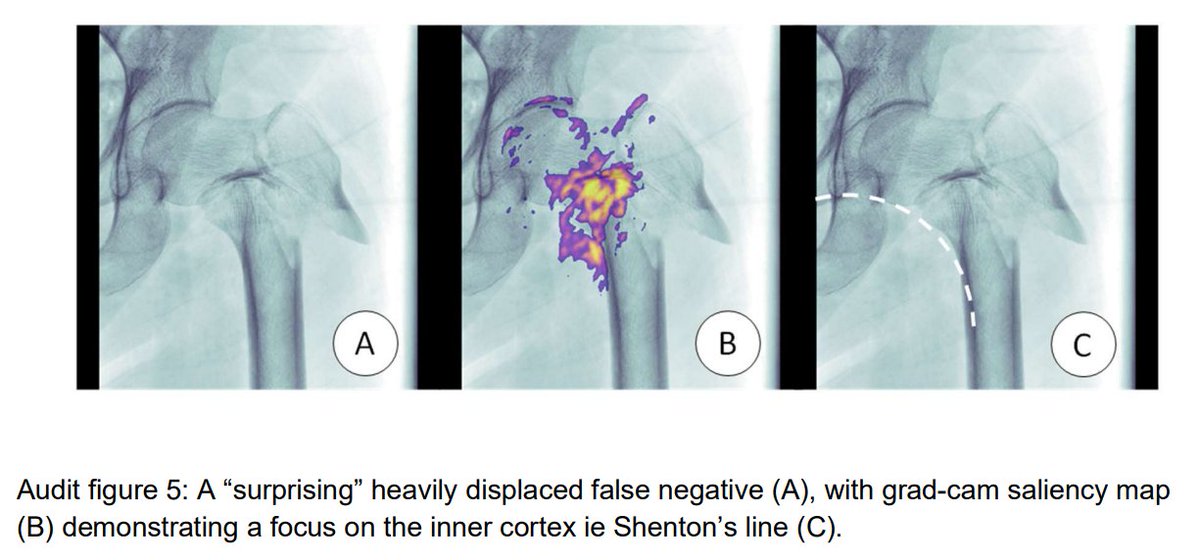
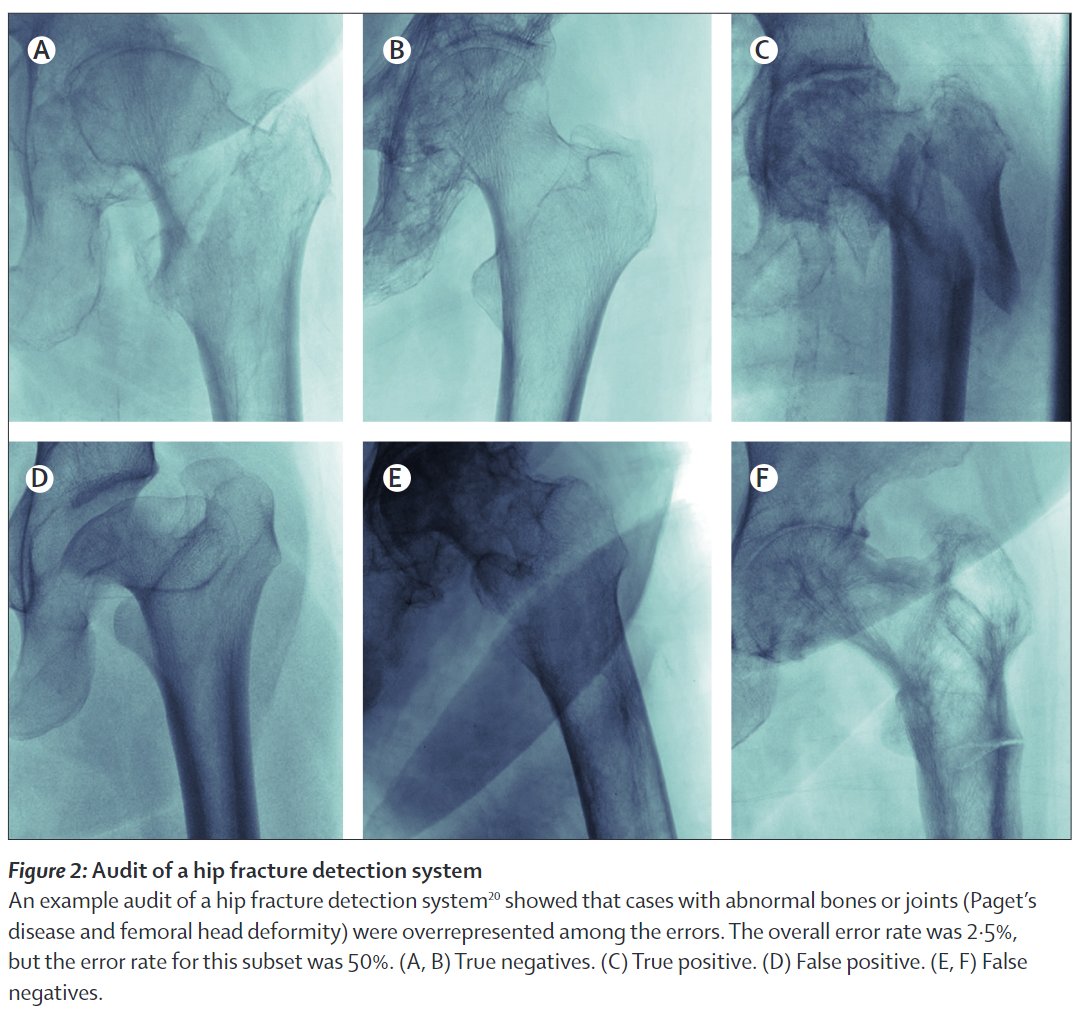
The high performance hip fracture model (AUC 0.994 vs 0.969 for radiologists) fails unexpectedly on an extremely obvious fracture and produces a cluster of errors in cases with abnormal bones (Paget's disease etc).
These findings (and risks) were only detected via audit.
4/7
These findings (and risks) were only detected via audit.
4/7
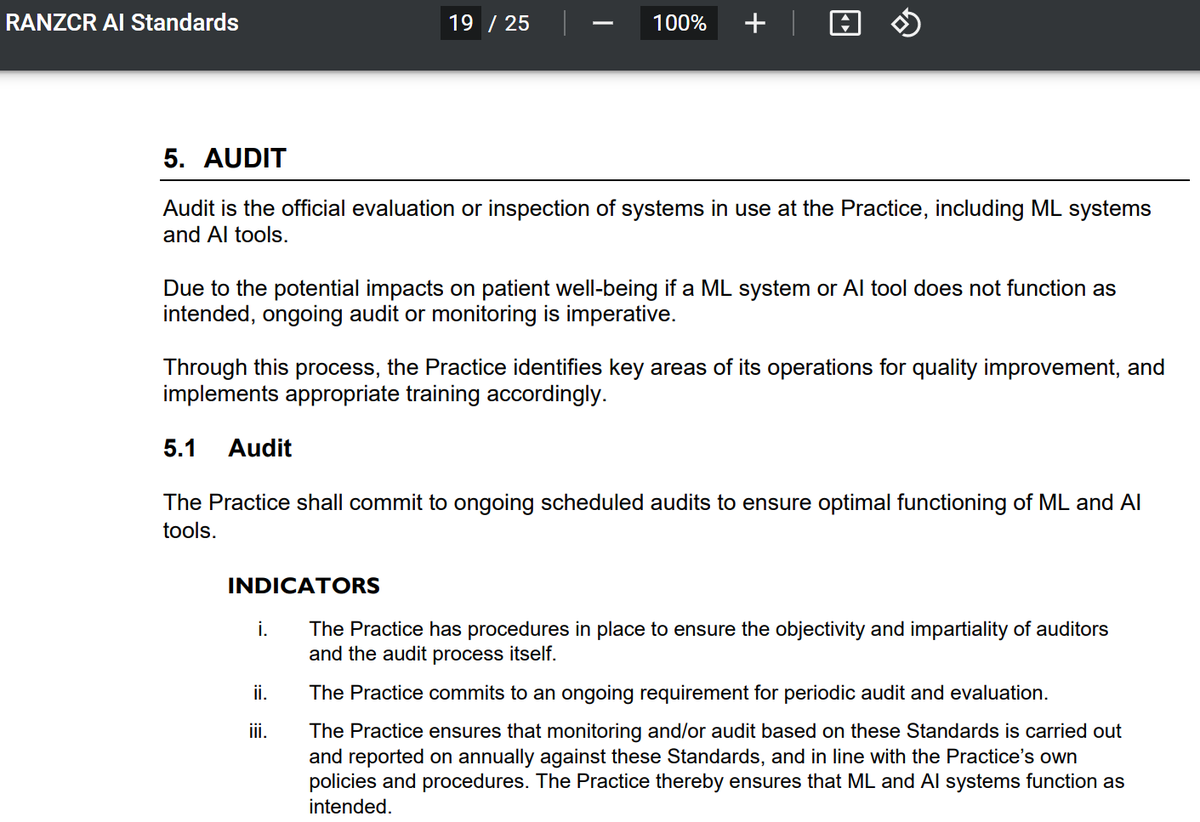
We are excited that this work is impacting policy. Professional orgs such as @RANZCRcollege are incorporating audit into their practice standards (ie ranzcr.com/college/docume…) and we are talking with regulators and governance groups on how audit can make AI systems safer.
5/7
5/7
I'll leave it at that for now (although expect a blog post in the near future 😂), so I'll just leave the links here:
Editorial: sciencedirect.com/science/articl…
Medical algorithmic audit: sciencedirect.com/science/articl…
Hip fractures: sciencedirect.com/science/articl…
6/7
Editorial: sciencedirect.com/science/articl…
Medical algorithmic audit: sciencedirect.com/science/articl…
Hip fractures: sciencedirect.com/science/articl…
6/7
Shoutouts:
Audit: @DrXiaoLiu @Denniston_Ophth in clinical AI governance, @MarzyehGhassemi @GlockerBen in ML4H, @MMccradden in AI bioethics.
Hips:
William Gale, @ghcarneiro @ApiBradley @PalmerLyle from Aus, and @mattlungrenMD and Thomas Bonham from @StanfordAIMI
7/7
Audit: @DrXiaoLiu @Denniston_Ophth in clinical AI governance, @MarzyehGhassemi @GlockerBen in ML4H, @MMccradden in AI bioethics.
Hips:
William Gale, @ghcarneiro @ApiBradley @PalmerLyle from Aus, and @mattlungrenMD and Thomas Bonham from @StanfordAIMI
7/7
Final celebrations/boasting (😂)
The audit paper is my first senior (last) author publication (co-seniored with the amazing @Denniston_Ophth), and both papers have been published under my new name!
They are also the final papers of my PhD, which is now completed!
🥳🥳🥳
8/7
The audit paper is my first senior (last) author publication (co-seniored with the amazing @Denniston_Ophth), and both papers have been published under my new name!
They are also the final papers of my PhD, which is now completed!
🥳🥳🥳
8/7
Urrgh I'm sorry, I don't know how I didn't link @rajiinio's profile here. If you don't know her, check her out, she does incredible work!
Also the other authors on the algorithmic audit paper are awesome too!
Also the other authors on the algorithmic audit paper are awesome too!
• • •
Missing some Tweet in this thread? You can try to
force a refresh