
Medical AI safety.
Director of Research @ nRAH Medical Imaging. Senior Research Fellow, Australian Institute for Machine Learning.
She/her 🏳️⚧️🏳️🌈


 Here's some more. If anyone doesn't understand why all these statements are explicitly transphobic ... well, it is because you don't face it. These are all extremely hurtful.
Here's some more. If anyone doesn't understand why all these statements are explicitly transphobic ... well, it is because you don't face it. These are all extremely hurtful.




 @huggingface as the model custodian (an interesting new concept) should implement an #ethics review process to determine the harm hosted models may cause, and gate harmful models behind approval/usage agreements.
@huggingface as the model custodian (an interesting new concept) should implement an #ethics review process to determine the harm hosted models may cause, and gate harmful models behind approval/usage agreements.


 #Medical #AI has a problem. Preclinical testing, including regulatory testing, does not accurately predict the risks that AI models pose once they are deployed in clinics.
#Medical #AI has a problem. Preclinical testing, including regulatory testing, does not accurately predict the risks that AI models pose once they are deployed in clinics.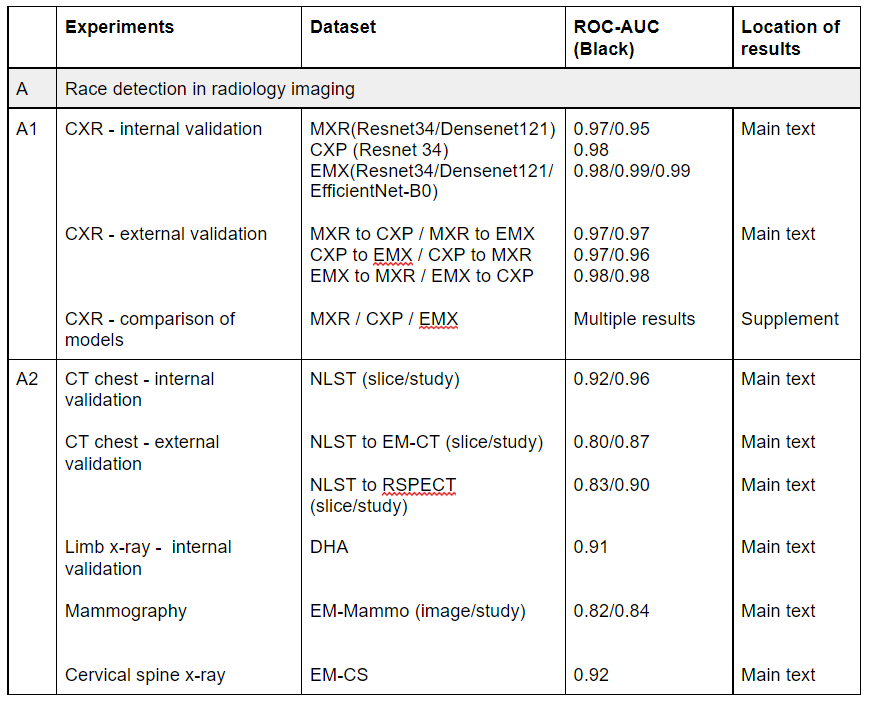


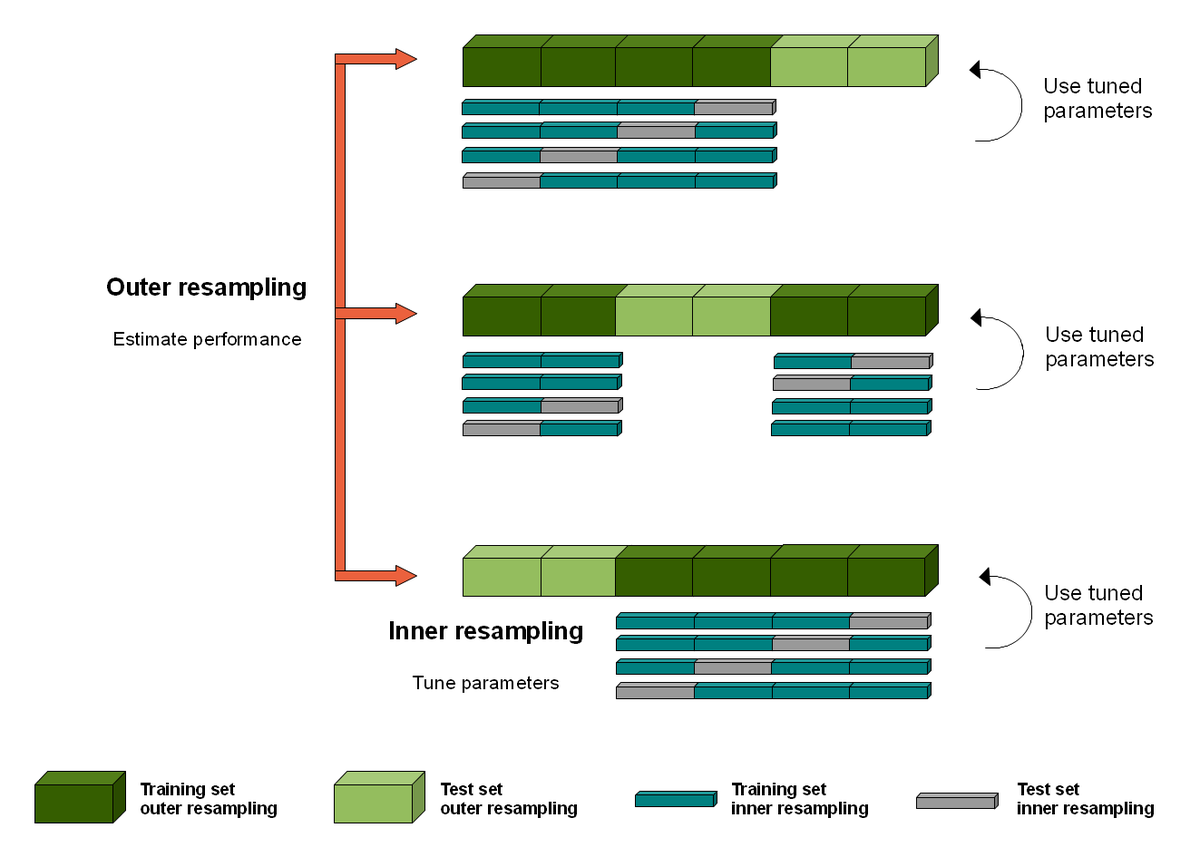 @weina_jin The weird thing about CV in AI is that you don't actually end up with a single model. You end up with k different models and sets of hyperparameters.
@weina_jin The weird thing about CV in AI is that you don't actually end up with a single model. You end up with k different models and sets of hyperparameters.