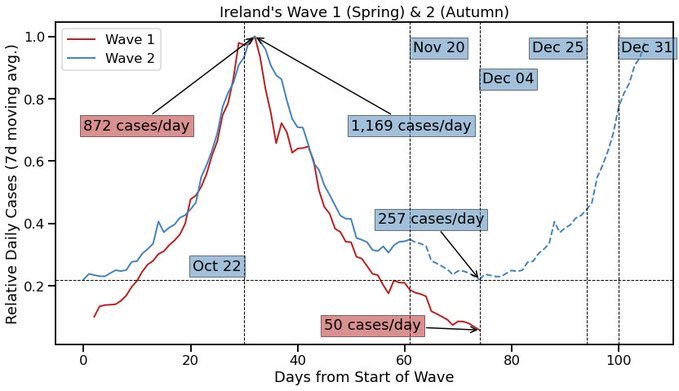
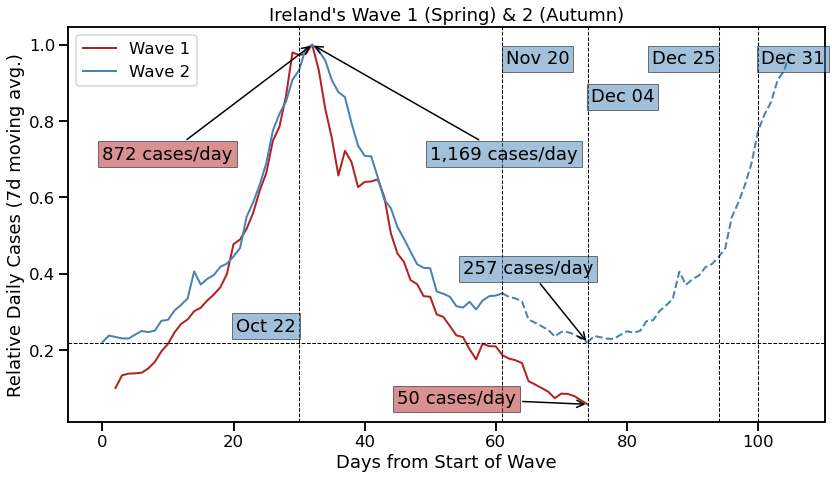
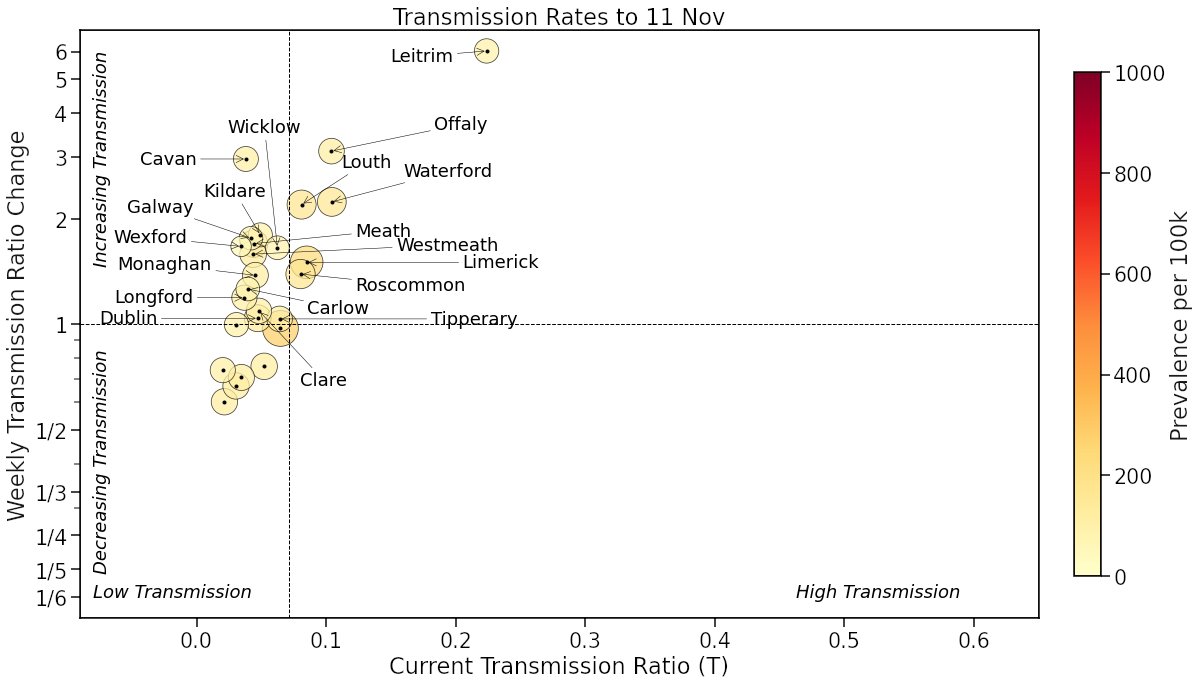
I teach a 15-credit course to 3rd yr #datascience ugrads @UCD. I've their full attention for ~10 wks. They work in pairs to produce a major project of their own design. Every year I'm amazed by how they grow during this time & the confidence they gain from what they achieve. 1\n
At the start of the module we've a 1-wk bootcamp where I work on a sample project from start to finish. Each year I pick a new topic & this year it was an analysis of #Wordle, the popular @nytime word puzzle. Here's a summary of the key findings... 2\n
towardsdatascience.com/big-data-in-li…
towardsdatascience.com/big-data-in-li…
The study was based on an analysis of almost 70M Wordle games: >53M simulated games (using a simulator designed to simulate realistic, not optimal, human gameplay) & >15M real games shared on Twitter. The simulated gameplay matches real gameplay in several important respects. 3\n
We found Wordle popularity peaked, on Twitter, at the start of Feb (~250k unique games posted), and by April postings had fallen to <100k per day. Are we just tired of sharing on Twitter? Google's search stats show just a 25% decline in interest in the same period, so maybe. 4\n 

We looked at the ubiquitous "what start word should I use?" question and found plenty of evidence that some start words (eg LEANT, TRACE, CRATE etc.) are much better than others in that they produce shorter games overall. 5\n

The Twitter data suggests that about 17% of players may use poor start words on a regular basis, and as a result they miss out on the opportunity to achieve short games (≤3 guesses). A good start word can mean >3.5x more short games compared to a poor start word. 6\n

Similarly, we looked at the difficulty of target words. Some words are easy to guess (eg WOULD, POINT have lots of short games, few long games & high win-rates) while others are much more challenging (eg JAUNT, SWILL have few short games, lots of long games & low win-rates). 7\n

And while most of Wordle's target words so far have been straightforward to guess (with more short games than long game) some have been especially challenging (e.g. PROXY, SWILL, LOWLY, FEWER). Why is this? 8\n

One reason is that the difficult words are less common and have unusual combinations of letters, but also because they have duplicate letters. Wordle's hints don't really help us much when it comes to repeating letters. 9\n

If you want to succeed at Wordle then you need to pay attention to all of the hints provided as feedback & consider carefully how they constrain your future guesses. Basically, if you ignore the hints then the number of rounds needed to guess a target word increases quickly. 10\n

We can estimate how important different hints/constraints are, based on how much new info they provide per guess. We analysed >250M rounds of play and found the information gained from the yellow hints to be the most important, then green, then grey. 11/n

You can read all about this analysis in my latest (long) @Medium post on @TDataScience at towardsdatascience.com/big-data-in-li…
And if you have any ideas for next year's bootcamp project then please shout. 12\12
And if you have any ideas for next year's bootcamp project then please shout. 12\12
• • •
Missing some Tweet in this thread? You can try to
force a refresh