
@RevEconStudies @SNageebAli @PennStateEcon @econ_greg @MSFTResearch @StanfordGSB @nberpubs A few years ago, I wrote a thread introducing a paper on "Voluntary Disclosure & Personalized Pricing" with @SNageebAli and @econ_greg (threadreaderapp.com/thread/1186778…).
Now that the paper has been accepted for publication, an update on what the paper is about 👇 1/n
Now that the paper has been accepted for publication, an update on what the paper is about 👇 1/n
The gist: In the debate about privacy, info disclosure & price discrimination, it's important to think about the structure and verifiability of the disclosure technologies. 2/n
Classical intuitions from Grossman (81) and Milgrom (81) suggest that voluntary disclosure is ultimately self-defeating and unhelpful to consumers. These intuitions are often invoked in arguments for strong privacy protections meant to keep consumer data out of firms' reach 3/n
More recent work has focused on disclosure as a vehicle for customization (e.g. Hidir and Vellodi ('21); Ichihashi ('21)) or disclosure through an all-powerful intermediary who can act on behalf of the consumer (e.g. Bergemann, Brooks & Morris ('15)) 4/n
We focus on a simple model of disclosure in which i) consumers can send convex messages about their types to receive an offer that they can accept or reject; ii) Messages are verifiable by a 3rd party (eg type 1/3 can claim to be in the interval [0,.5] but not [.5, 1]) 5/n
We show that the structure of the message technology makes a big difference in what can result. 6/n
In a world w/ only "simple" messages (e.g. "tell me everything or tell me nothing") voluntary disclosure cannot help consumers in monopolistic markets; the classical intuition holds. 7/n
By contrast, partial disclosure through "rich" messages (e.g. "nothing but the truth, but not necessarily the whole truth") allows for equilibria in which nearly all consumer types strictly benefit from disclosing information. 8/n
This idea generalizes: it suffices for there to be a way to generate "group pricing" (e.g. info that separates low value types from high types in equilibrium) in order for voluntary disclosure to produce Pareto improvements. 9/n 

These results extend to natural relaxations of our basic model, such as when firms have external info about their consumers prior to interacting. If instead of a monopolist, there are multiple differentiated firms, even simple messages are beneficial to consumers. 10/n
A natural question is where this all fits in discussions of real life policy. For this, it's useful to revisit the assumptions in our model. 11/n
There are two key features in our messaging technologies: (i) messages are verifiable: there is a 3rd party who can ensure that consumers don't lie; (ii) consumers are never committed to sending a particular message or executing a given personalized offer. 12/n
First, note that there is verifiable disclosure all around us. Folks can submit gov't docs (EBT cards; W-2 receipts) to apply for discounts big and small. People regularly receive promotions based on their internet browsing record, or even their recent purchasing history. 13/n
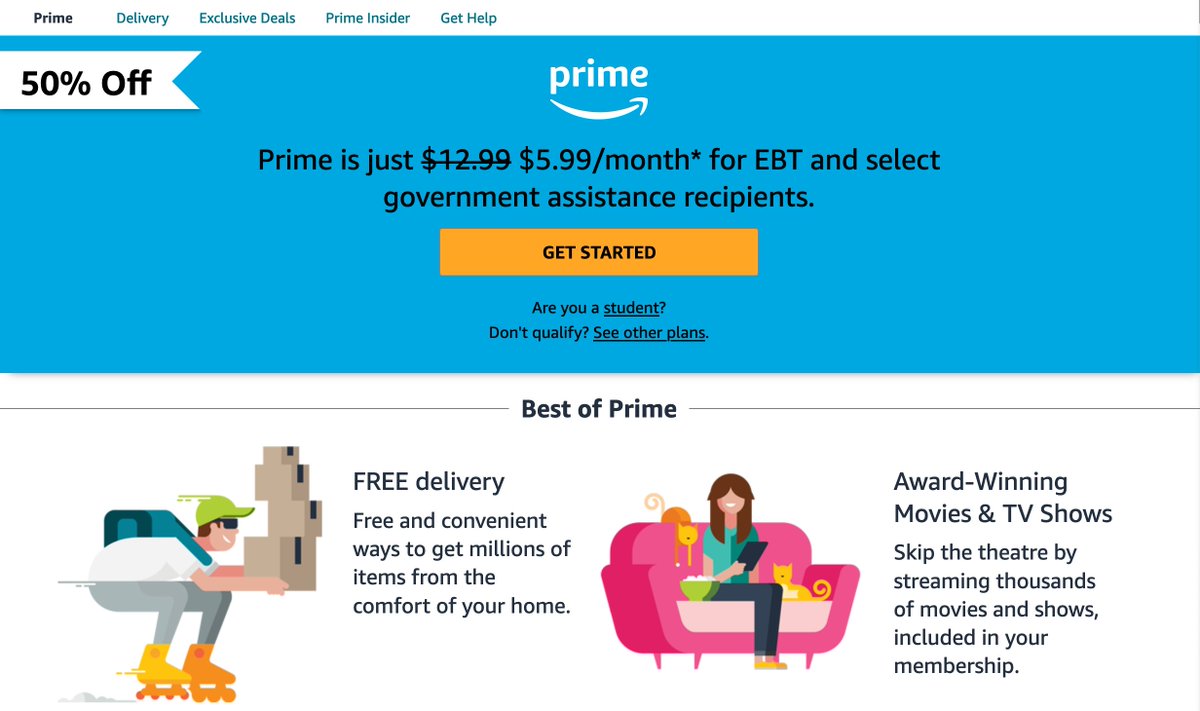
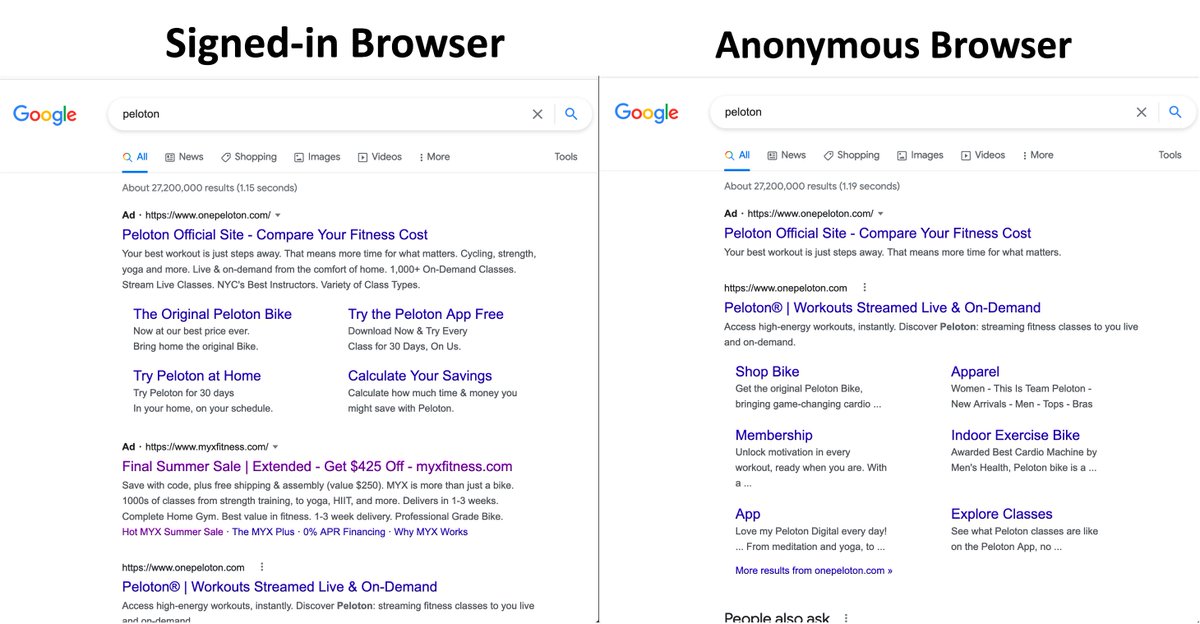
In some cases, voluntary disclosure is offered as a direct promotional program by the seller, as in the auto-insurance monitoring program that Yizhou and I study. 14/n
Second, our characterization has guidance for regulatory design.
Second, our characterization has guidance for regulatory design.

Consumer control over info, rather than rigid privacy, is what drives Pareto gains. But to implement gains, a "verifier" the gov't, a platform or a firm) can choose the coarseness of the message space. We argue that each potential verifier has interests in consumer gains 15/n
There's a lot more in the paper of course. I hope you read it and let us know what you think. This project started when I interned at @MSFTResearch as a PhD student. It's been a pleasure to work on. Thank you to all the amazing folks who've discussed it with us over the years n/n
@MSFTResearch @threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh










