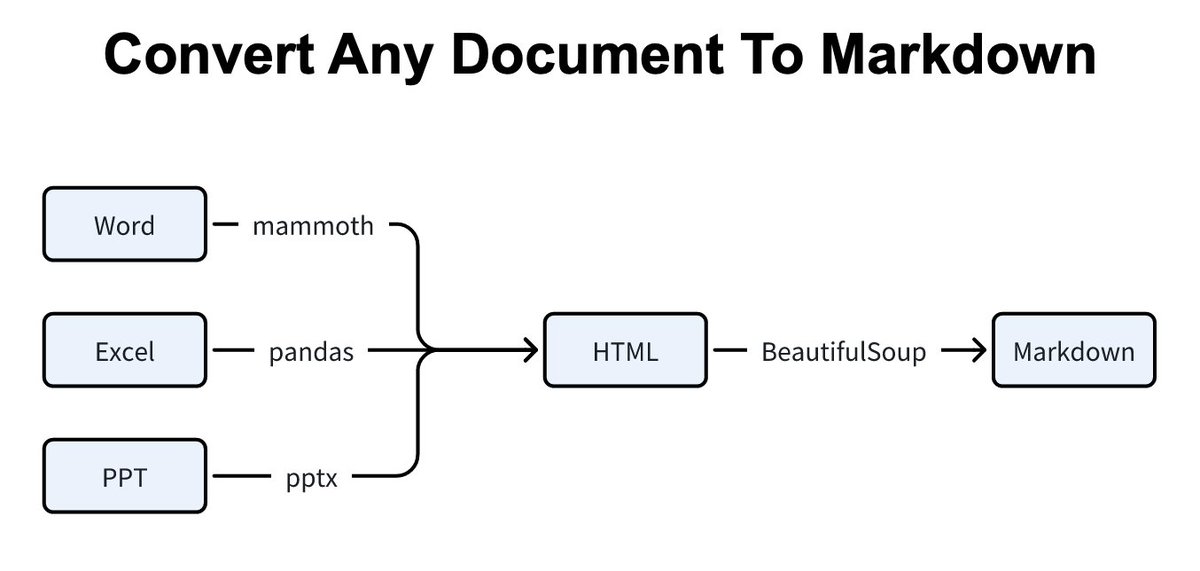
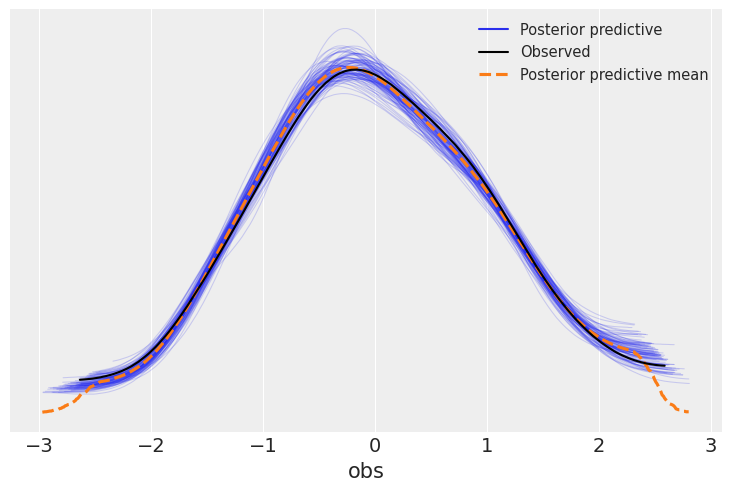
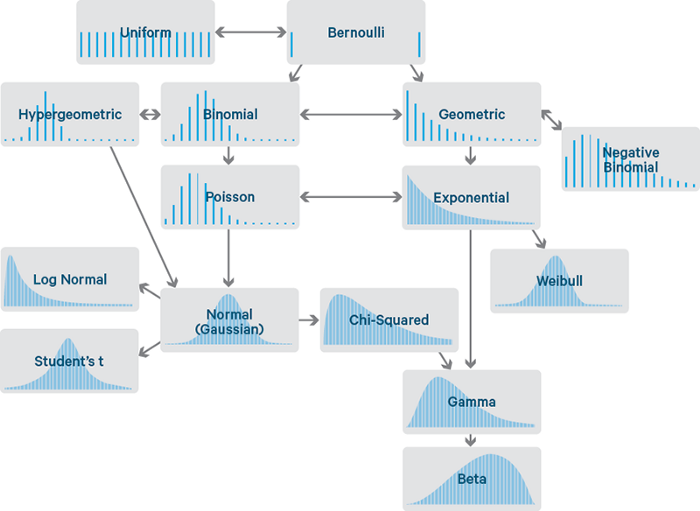
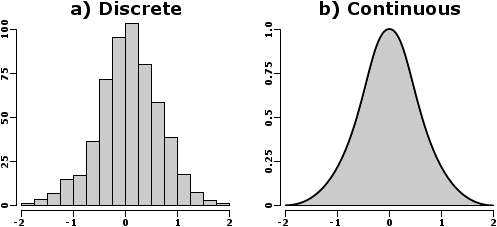
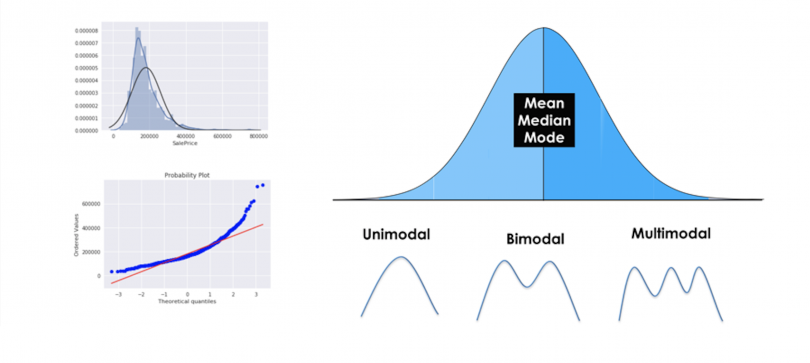
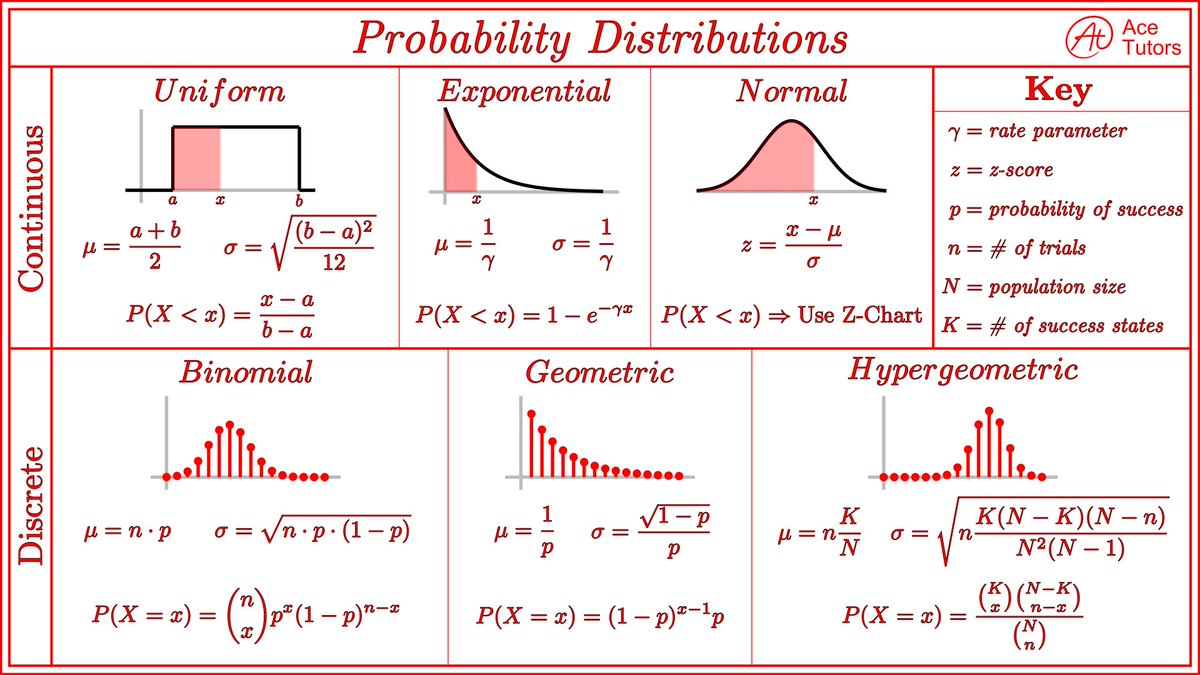
What could go wrong?
LOL. 😂
Plus the 3 #datascience books that helped me learn #stats the most. 🧵
#rstats
LOL. 😂
Plus the 3 #datascience books that helped me learn #stats the most. 🧵
#rstats

I’m not saying you need to be an expert in advanced calculus to do machine learning…
BUT, there is a big difference between someone that does vs someone that does NOT have a good foundation in stats when it comes to getting & explaining business results.
BUT, there is a big difference between someone that does vs someone that does NOT have a good foundation in stats when it comes to getting & explaining business results.
My thought process back in the day was to obtain a great foundation in stats and machine learning at the same time.
So here’s what helped me. I read a ton of books.
Here are the 3 books that helped me learn data science the most...
So here’s what helped me. I read a ton of books.
Here are the 3 books that helped me learn data science the most...
1. R for Data Science (Wickham & Grolemund) r4ds.had.co.nz
2. Introduction to Statistical Learning (James, Witten, Hastie, & Tibshirani) statlearning.com
3. Applied Predictive Modeling (Kuhn & Johnson) appliedpredictivemodeling.com
Keep in mind that I’ve read 300+ books on stats, ML, time series, …
But these were the 3 best. Ones I got a ton of applied value out of.
But these were the 3 best. Ones I got a ton of applied value out of.
Now you’re probably thinking reading these 3 books will take a long time, and still might not get you the whole way to data scientist.
That’s why I want to help you speed up the process.
So it doesn’t take you 5 years to learn data science (like it did me).
That’s why I want to help you speed up the process.
So it doesn’t take you 5 years to learn data science (like it did me).
I compiled the top 10 most important skills that helped me learn and get results from data science.
And I put these top 10 data science skills into a FREE 40-minute webinar.
Enjoy!
learn.business-science.io/free-rtrack-ma…
And I put these top 10 data science skills into a FREE 40-minute webinar.
Enjoy!
learn.business-science.io/free-rtrack-ma…

• • •
Missing some Tweet in this thread? You can try to
force a refresh