
Started with a landscape in #midjourney. Used a depth map in @sidefx #houdini to create a scene mesh. Imported to #UnrealEngine5 @UnrealEngine to add grass and animate. Added music. Breakdown thread 1/8 #aiartprocess #MachineLearning #deeplearning #aiartcommunity #genart #aiia
I could have created a similar scene in just Unreal Engine and Quixel but I wanted to see what I could do with this landscape image I generated in #midjouney 2/8 #aiartprocess 

I'm also trying to do more collaborations with other AI Artists so I used this as an excuse to research depth maps further and see how I could push them. I generated this LeRes depth map using "Boosting Monocular Depth Estimation to High Resolution" on Github. 3/8 #aiartprocess

I applied the depth map as a displacement map on a high-poly plane in @sidefx #houdini. I like Houdini because of the way it helps me deconstruct process with nodes and code and I can experiment with workflows easily. Rendered this natively in Mantra. 4/8 #aiartprocess
I then took the scene mesh and imported it as a .obj into #UE5. I wanted to apply grass with the footage tool directly onto the mesh, but that didn't work. So I sculpted a plane in the shape of the foreground terrain using Unreal's native modelling tools. 5/8 #aiartprocess
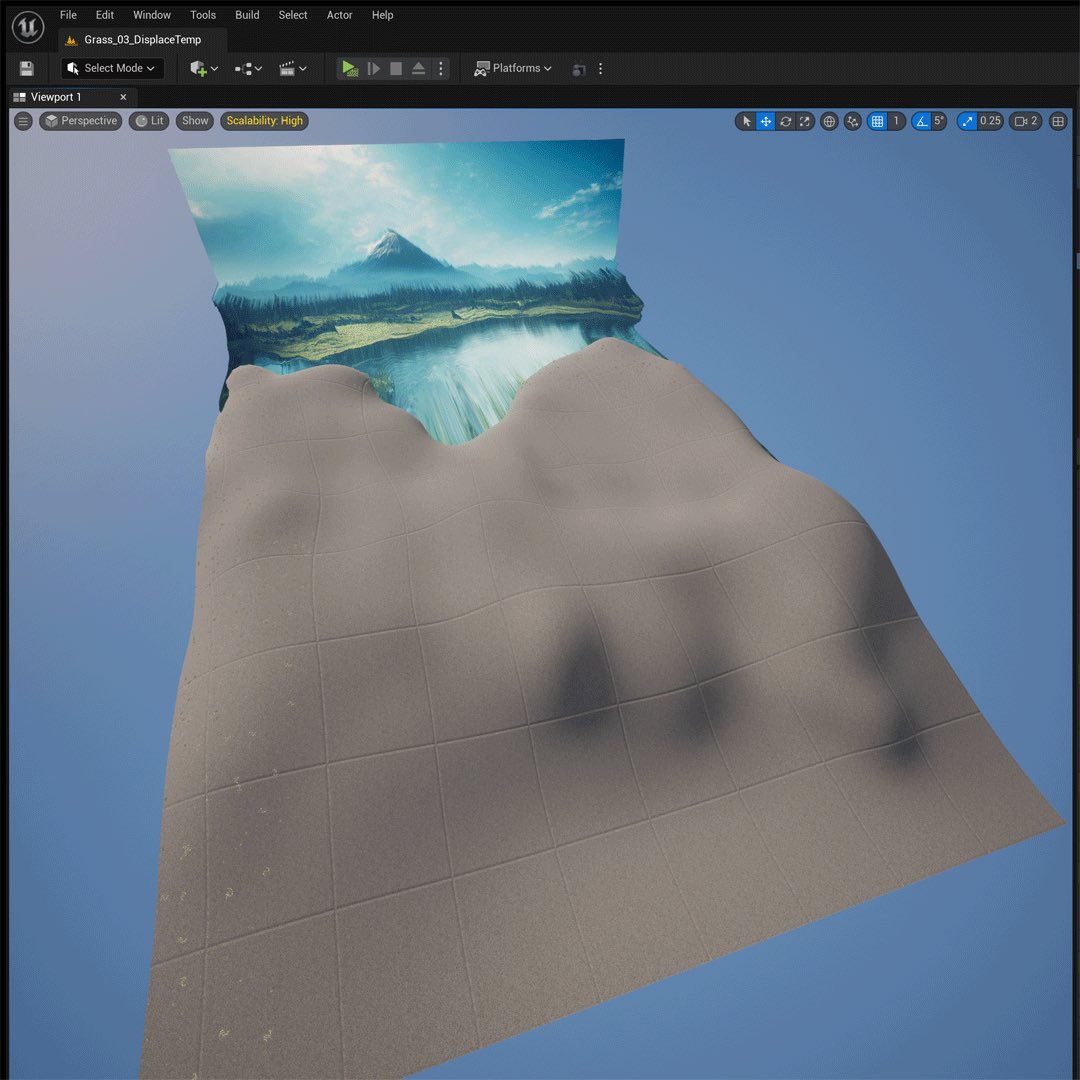
I then used the foliage brush to add grass to the plane. There's lots of YouTube tutorials like this one that explain how. 6/8 #aiartprocess
I applied a Third-Person game template in #UnrealEngine5 and did a screen recording of a character I controlled running around the scene in real-time. I also animated a camera and rendered a cinematic with Movie Render Queue. (1st post.) 7/8 #aiartprocess
There's clearly some rough edges to this project, but it's basically an exploration of different ways a 2D image might be coverted into 3D with depth maps. I have some other ideas I'm going try soon. If you have a cool process involving that please share! 8/8 #aiartprocess
• • •
Missing some Tweet in this thread? You can try to
force a refresh









