ARCH can improve your ARIMA Time Series forecast!
Learn how 👇👇
A thread 🧵
#Python #MachineLearning #DataScience
Learn how 👇👇
A thread 🧵
#Python #MachineLearning #DataScience

We've seen that ARCH is a model to forecast the variance of a time series.
It is frequently used in situations in which there may be short periods of increased variation or volatility.
It is frequently used in situations in which there may be short periods of increased variation or volatility.
They were created for finance and econometric problems. 💸
But...
But...
It can be also used for any data with periods of increased or decreased variance.
For example, it can model the residuals after an ARIMA model has been fit to our data. 🤯
For example, it can model the residuals after an ARIMA model has been fit to our data. 🤯
In this case, if we use it after fitting an ARIMA model, it can be proven that:
The variance of the error term is equivalent to the volatility of past error values → ARCH model 🎉
The variance of the error term is equivalent to the volatility of past error values → ARCH model 🎉
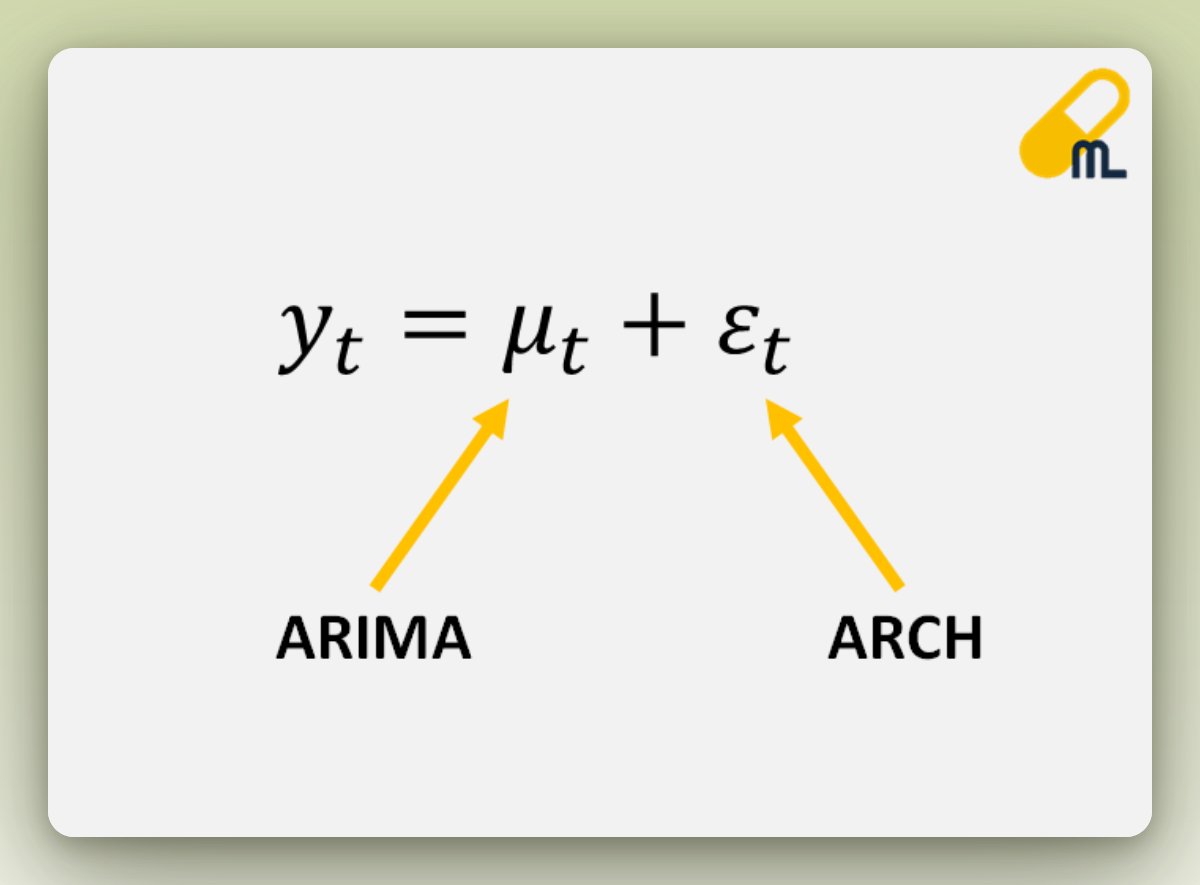
ARCH models help represent the error term as a product of:
• Variance of previous periods or volatility
• White noise (random and unpredictable): it will be the error term of the ARCH model
• Variance of previous periods or volatility
• White noise (random and unpredictable): it will be the error term of the ARCH model

So we can see in the image how the ARCH model can be beneficial in forecasting the error term 👇👇

Please 🔁Retweet if you found it useful to increase the reach!
🔔 Follow me @daansan_ml if you are interested in:
🐍 #Python
📊 #DataScience
📈 #TimeSeries
🤖 #MachineLearning
Thanks! 😉
🔔 Follow me @daansan_ml if you are interested in:
🐍 #Python
📊 #DataScience
📈 #TimeSeries
🤖 #MachineLearning
Thanks! 😉
• • •
Missing some Tweet in this thread? You can try to
force a refresh