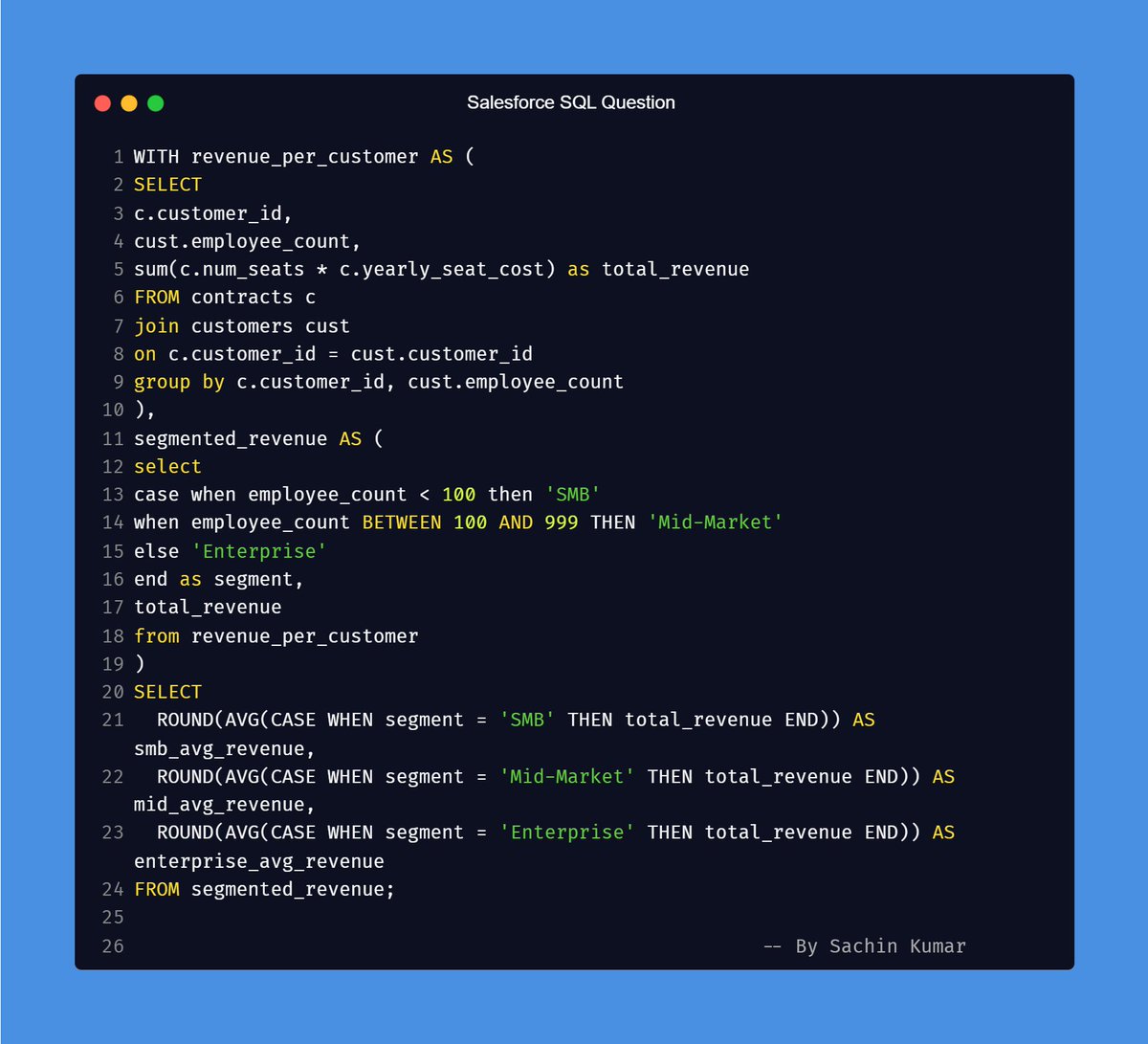
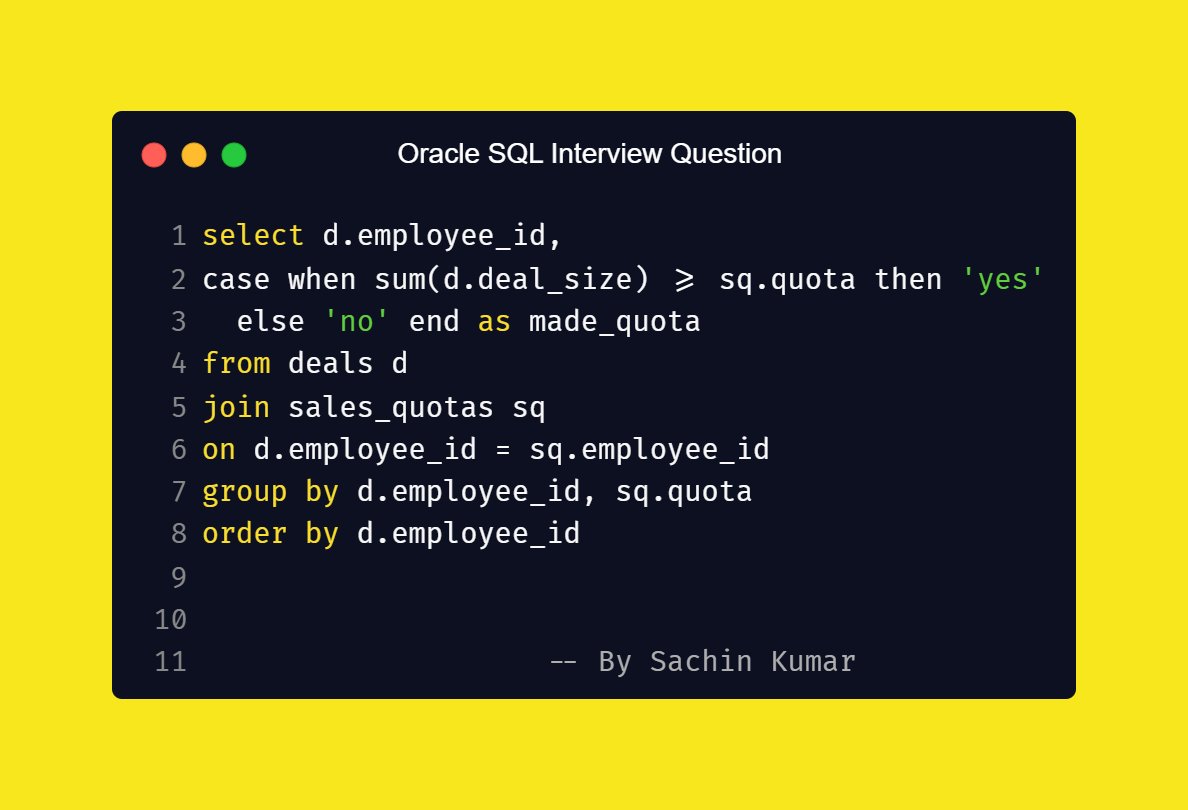
📝Which 𝗘𝘅𝗰𝗲𝗹 features you must know as 𝗗𝗮𝘁𝗮 𝗔𝗻𝗮𝗹𝘆𝘀𝘁? 🔥
🧵👇
🧵👇
- 𝗣𝗶𝘃𝗼𝘁 𝘁𝗮𝗯𝗹𝗲𝘀 𝗮𝗻𝗱 𝗽𝗶𝘃𝗼𝘁 𝗰𝗵𝗮𝗿𝘁𝘀
- 𝗖𝗼𝗻𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗳𝗼𝗿𝗺𝗮𝘁𝘁𝗶𝗻𝗴
- 𝗖𝗼𝗻𝗰𝗮𝘁𝗲𝗻𝗮𝘁𝗲
- 𝗜𝗳, 𝘀𝘂𝗺𝗶𝗳, 𝗰𝗼𝘂𝗻𝘁𝗶𝗳, 𝗮𝘃𝗲𝗿𝗮𝗴𝗲𝗶𝗳
- 𝗜𝗳 𝗲𝗿𝗿𝗼𝗿𝘀
- 𝗨𝗻𝗶𝗾𝘂𝗲
- 𝗧𝗿𝗶𝗺
- 𝗦𝗼𝗿𝘁
- 𝗖𝗼𝘂𝗻𝘁𝗯𝗹𝗮𝗻𝗸
- 𝗖𝗼𝗻𝗱𝗶𝘁𝗶𝗼𝗻𝗮𝗹 𝗳𝗼𝗿𝗺𝗮𝘁𝘁𝗶𝗻𝗴
- 𝗖𝗼𝗻𝗰𝗮𝘁𝗲𝗻𝗮𝘁𝗲
- 𝗜𝗳, 𝘀𝘂𝗺𝗶𝗳, 𝗰𝗼𝘂𝗻𝘁𝗶𝗳, 𝗮𝘃𝗲𝗿𝗮𝗴𝗲𝗶𝗳
- 𝗜𝗳 𝗲𝗿𝗿𝗼𝗿𝘀
- 𝗨𝗻𝗶𝗾𝘂𝗲
- 𝗧𝗿𝗶𝗺
- 𝗦𝗼𝗿𝘁
- 𝗖𝗼𝘂𝗻𝘁𝗯𝗹𝗮𝗻𝗸
- 𝗗𝗮𝘆𝘀 𝗮𝗻𝘀 𝗡𝗲𝘁𝘄𝗼𝗿𝗸𝗱𝗮𝘆𝘀
- 𝗥𝗮𝗻𝗸
- 𝗦𝘂𝗺𝗽𝗿𝗼𝗱𝘂𝗰𝘁
- 𝗦𝘂𝗺, 𝗖𝗼𝘂𝗻𝘁, 𝗔𝘃𝗲𝗿𝗮𝗴𝗲
- 𝗠𝗶𝗻, 𝗠𝗮𝘅, 𝗠𝗲𝗱𝗶𝗮𝗻, 𝗦𝘁𝗱𝗲𝘃
- 𝗥𝗶𝗴𝗵𝘁, 𝗟𝗲𝗳𝘁, 𝗠𝗶𝗱
- 𝗥𝗮𝗻𝗸
- 𝗦𝘂𝗺𝗽𝗿𝗼𝗱𝘂𝗰𝘁
- 𝗦𝘂𝗺, 𝗖𝗼𝘂𝗻𝘁, 𝗔𝘃𝗲𝗿𝗮𝗴𝗲
- 𝗠𝗶𝗻, 𝗠𝗮𝘅, 𝗠𝗲𝗱𝗶𝗮𝗻, 𝗦𝘁𝗱𝗲𝘃
- 𝗥𝗶𝗴𝗵𝘁, 𝗟𝗲𝗳𝘁, 𝗠𝗶𝗱
📌 Follow @SachinK02316651 for more Update
#Excel #ExcelTips #exceltricks #DataScience #Data #dataprotection #SQL #Python #PowerBI
#Excel #ExcelTips #exceltricks #DataScience #Data #dataprotection #SQL #Python #PowerBI

• • •
Missing some Tweet in this thread? You can try to
force a refresh