
What dates📅 can @OpenAI, @AnthropicAI, @CohereAI models reliably answer questions for?🔭
I binary-search through "future" Wiki events to find out. Results ❌🟰❌documentation:
#GPT4 ➡️~Dec 19 ('21)
#ChatGPT ➡️~Oct 24
Claude v1.2➡️~Oct 10
Cohere XL Nightly➡️~Apr 24 ('22)
1/🧵
I binary-search through "future" Wiki events to find out. Results ❌🟰❌documentation:
#GPT4 ➡️~Dec 19 ('21)
#ChatGPT ➡️~Oct 24
Claude v1.2➡️~Oct 10
Cohere XL Nightly➡️~Apr 24 ('22)
1/🧵
GPT4 says it is trained up to Sept 2021.
I found it correctly answers unknowable events in Oct, Nov, and even Dec 11th & 19th.
In late Dec it begins to abstain.
2/
I found it correctly answers unknowable events in Oct, Nov, and even Dec 11th & 19th.
In late Dec it begins to abstain.
2/




Interestingly, GPT 3.5 "Default" answers correctly only until ~Oct 24, 2021, but GPT 3.5 "Legacy" answers correctly until ~Oct 31, 2021 then begins hallucinating false answers or abstaining in Nov.
Perhaps this is due to finetuning rather than pretraining data?
3/
Perhaps this is due to finetuning rather than pretraining data?
3/
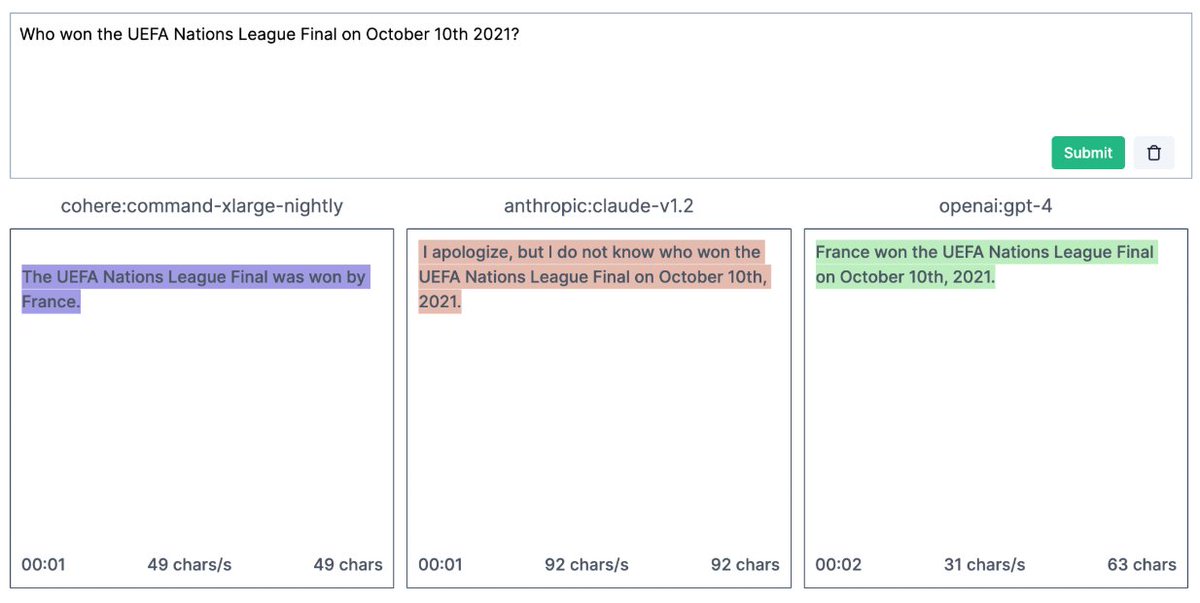
@AnthropicAI's Claude v1.2 model correctly answers questions July 11, Aug 12, Sept 26, Oct 10 but abstains at Oct 9 & Nov 2.
➡️The trick with Claude is to ask it about an event without telling it the date (see examples).
4/
➡️The trick with Claude is to ask it about an event without telling it the date (see examples).
4/


@CohereAI's Command XL Nightly provides the most recent correct answers of the 3 models! 🌟
✅It correctly answers Qs in March 9 & April 24, 2022 but hallucinates May onwards.
❌It does not seem to abstain from answering future info it doesn't know, like the others.
5/
✅It correctly answers Qs in March 9 & April 24, 2022 but hallucinates May onwards.
❌It does not seem to abstain from answering future info it doesn't know, like the others.
5/



#Wikipedia yearly event pages are an awesome resource for this: e.g. en.wikipedia.org/wiki/2022
I found national election results and sports tournaments the most reliable: they are sufficiently high profile, and (usually) unpredictable.
6/
I found national election results and sports tournaments the most reliable: they are sufficiently high profile, and (usually) unpredictable.
6/

Thanks to @natfriedman’s nat.dev tool for making this analysis possible!
Please feel free to leave thoughts/comments!
/🧵
Please feel free to leave thoughts/comments!
/🧵
• • •
Missing some Tweet in this thread? You can try to
force a refresh



















