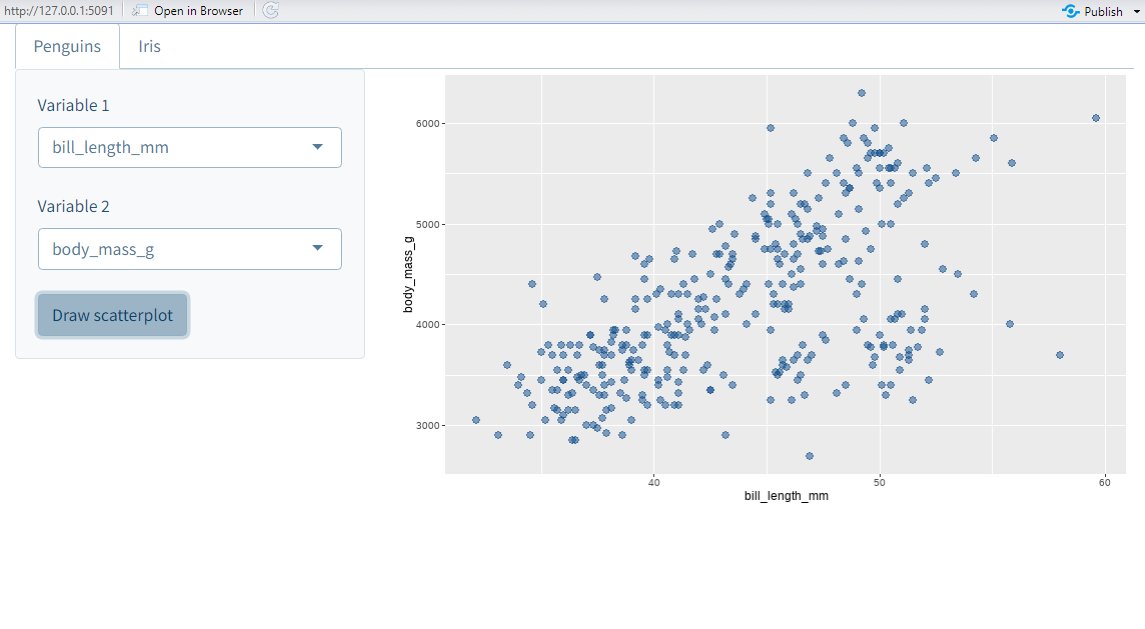
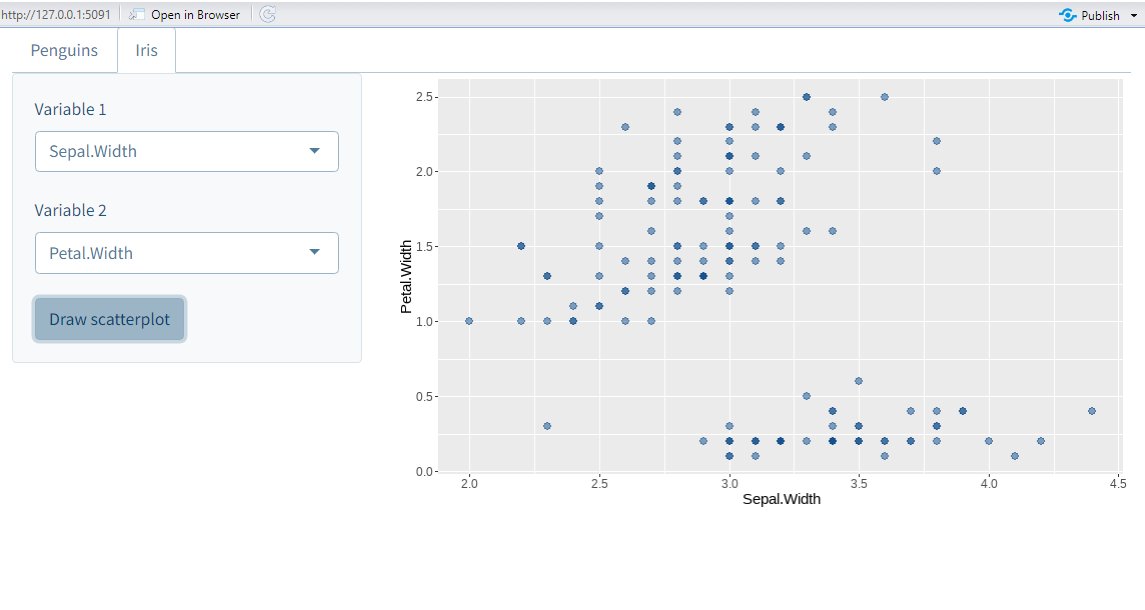
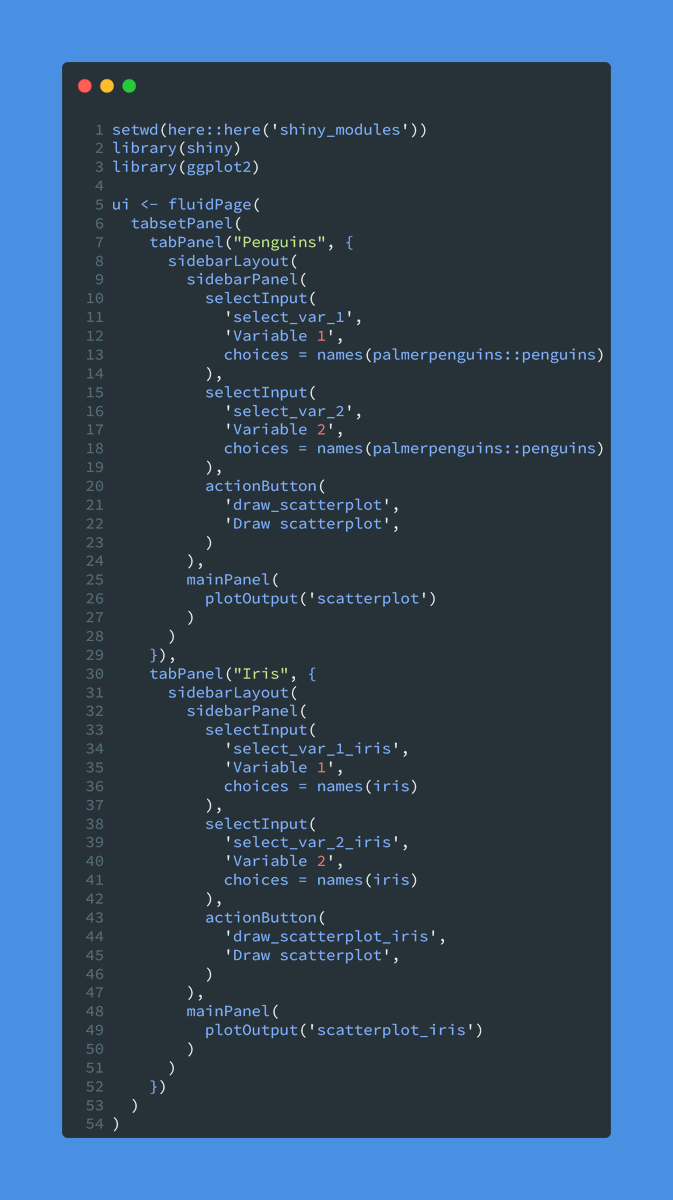
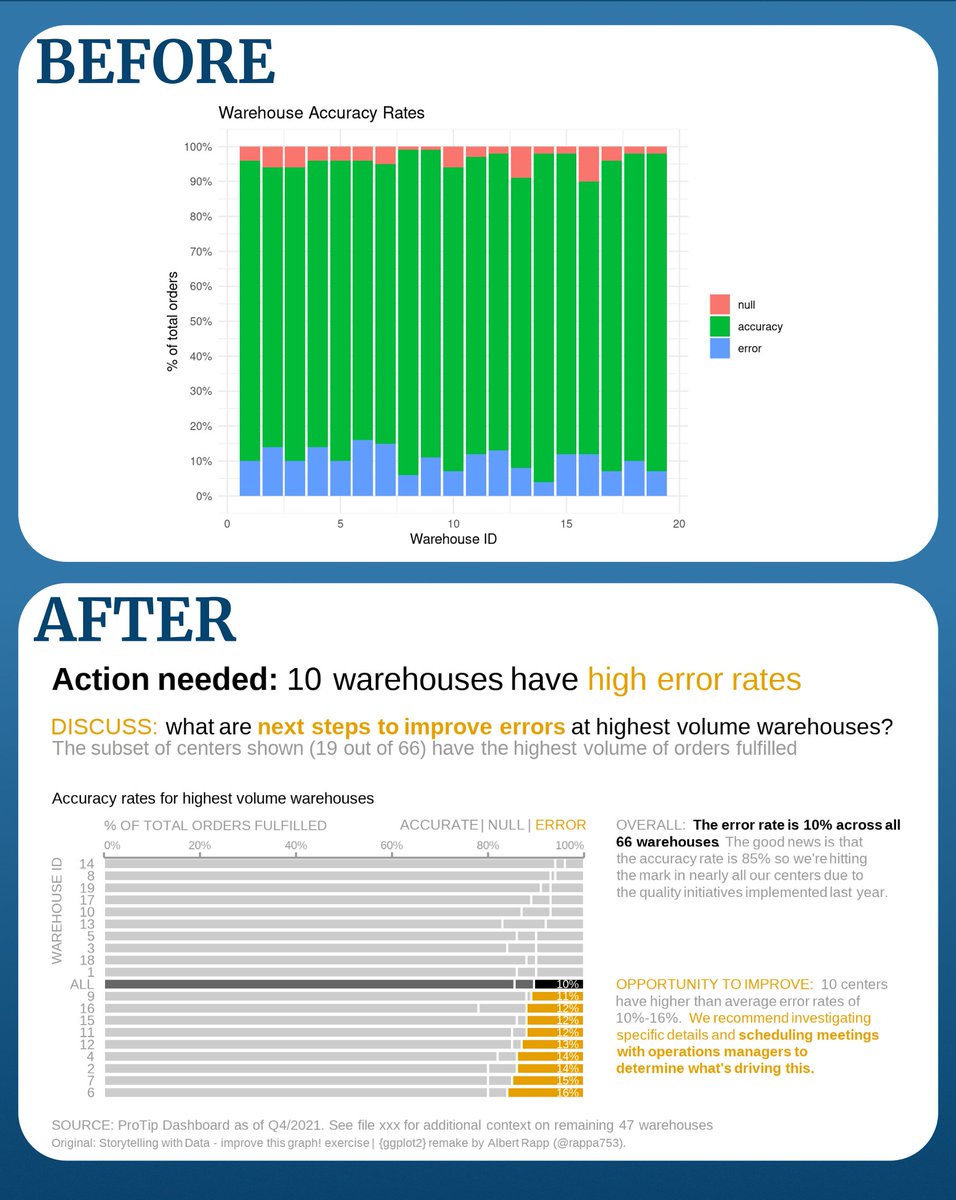
Data cleaning is tedious.
But it's much easier with the {janitor} package. Especially if you work with Excel files.
Here are 5 underrated features from {janitor}. #rstats
But it's much easier with the {janitor} package. Especially if you work with Excel files.
Here are 5 underrated features from {janitor}. #rstats
1 // Create clean names
This is absolutely the best function. It transforms column names such that they are easier to use for programming.
Left: Bad for programming
Right: Good for programming
This is absolutely the best function. It transforms column names such that they are easier to use for programming.
Left: Bad for programming
Right: Good for programming
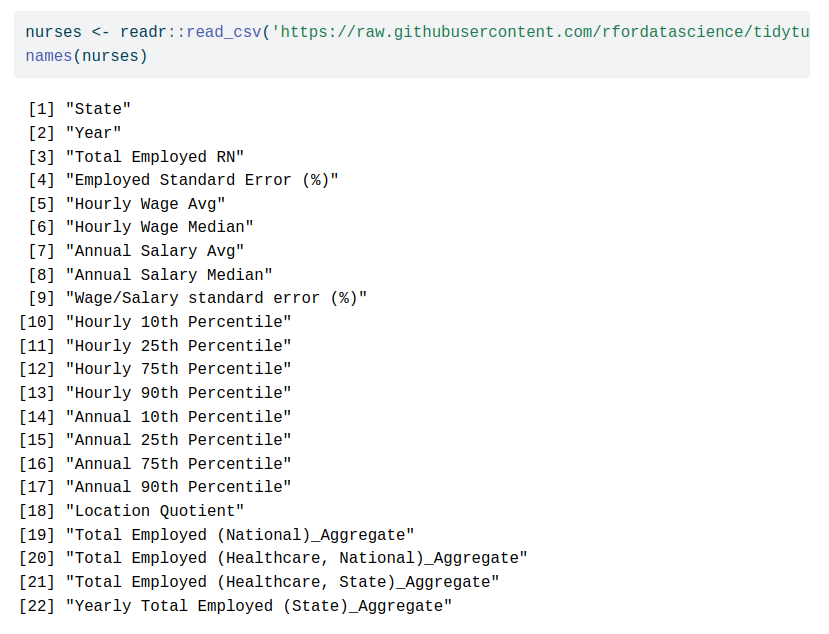

2 // Remove empty or constant cells from Excel files
Excel files can be messy to read in R. Lots of weird column names and empty cells.
{janitor} takes care of that for us.
Excel files can be messy to read in R. Lots of weird column names and empty cells.
{janitor} takes care of that for us.


3 // Convert stupid Excel dates
Our lovely {janitor} can even convert those pesky Excel dates to something we can work with.
Check out how the hire_date column from our previous output is transformed to actual dates.
Our lovely {janitor} can even convert those pesky Excel dates to something we can work with.
Check out how the hire_date column from our previous output is transformed to actual dates.


4 // Rounding
R does not always round up numbers that end with .5
R uses Banker's rounding 🤦 🤯
Instead of implementing the rounding yourself, just use {janitor} functions.
R does not always round up numbers that end with .5
R uses Banker's rounding 🤦 🤯
Instead of implementing the rounding yourself, just use {janitor} functions.

5 // Find duplicates
Sometimes you need to find duplicate observations based on a set of characteristics.
In that case, get_dupes() is your friend.
Sometimes you need to find duplicate observations based on a set of characteristics.
In that case, get_dupes() is your friend.

That was our short list. I hope you'll give {janitor} a try now.
All code examples can be found in my blog at albert-rapp.de/posts/07_janit…
Let me know if you liked this thread by liking its first post below ☺️
And for more content like this, follow @rappa753. See you next time 👋
All code examples can be found in my blog at albert-rapp.de/posts/07_janit…
Let me know if you liked this thread by liking its first post below ☺️
And for more content like this, follow @rappa753. See you next time 👋
https://twitter.com/rappa753/status/1663908243666530304
If you liked this post, you may enjoy my 3-minute newsletter too.
Every week, my newsletter shares insights on
- R & dataviz,
- Shiny and web dev
Reading time: 3 minutes or less
You can join at
alberts-newsletter.beehiiv.com/subscribe
Every week, my newsletter shares insights on
- R & dataviz,
- Shiny and web dev
Reading time: 3 minutes or less
You can join at
alberts-newsletter.beehiiv.com/subscribe
• • •
Missing some Tweet in this thread? You can try to
force a refresh