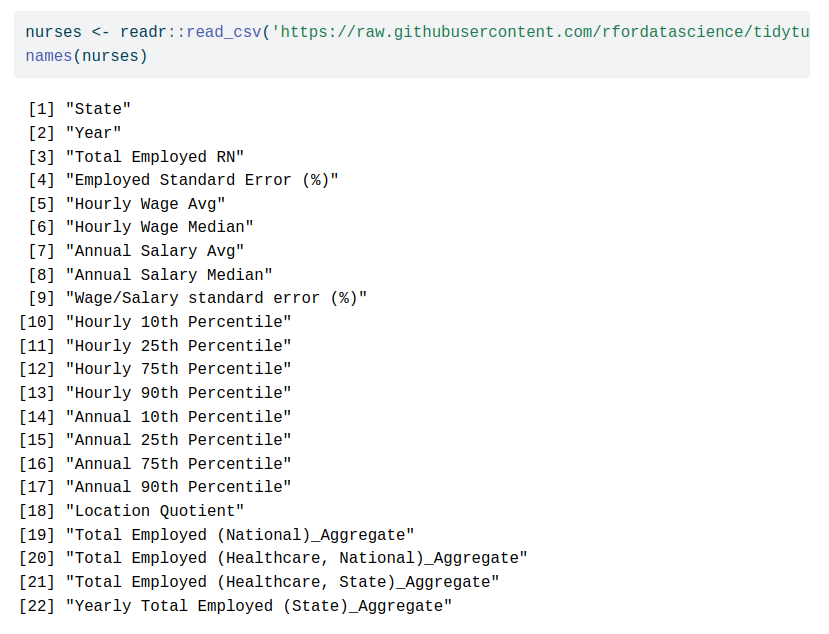
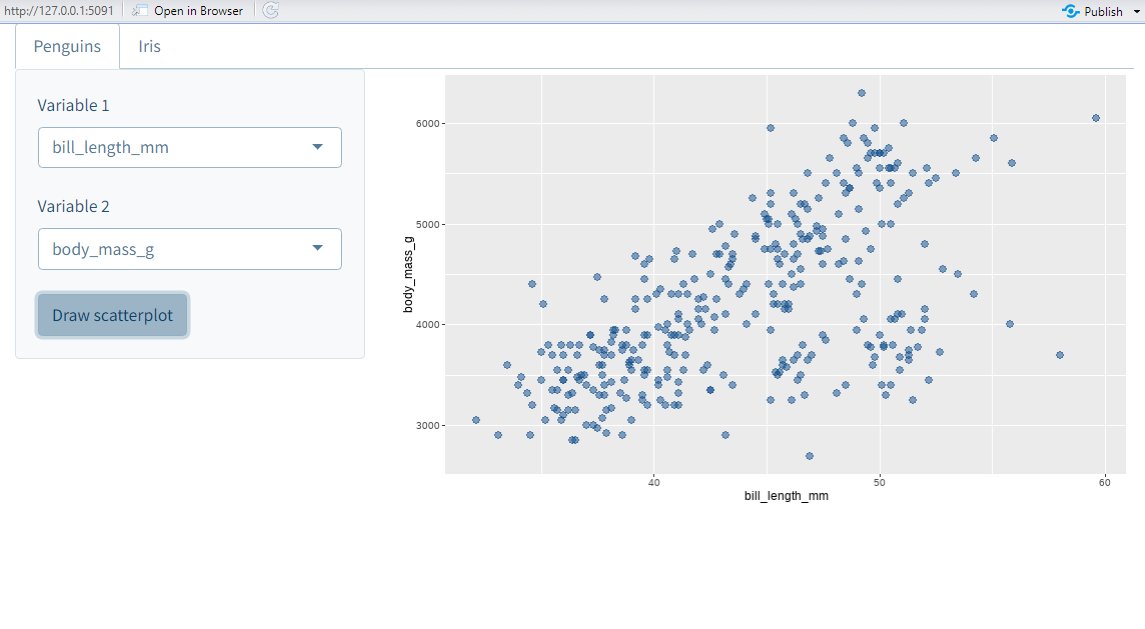
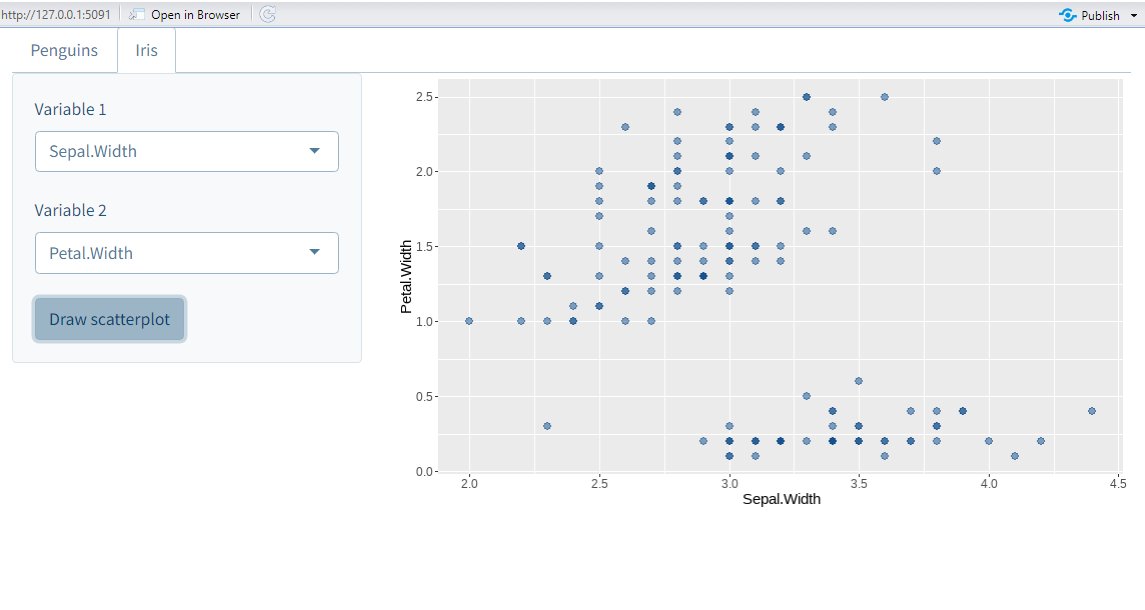
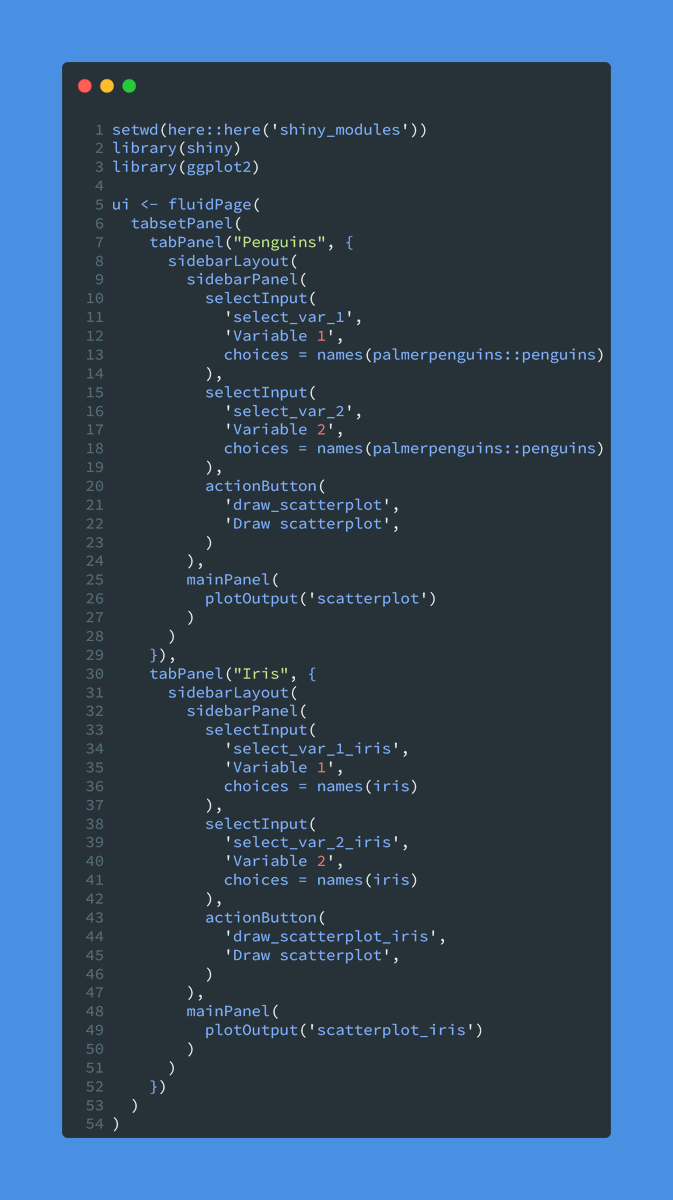
Everybody loves colors but only few know how to use them well.
With the right guidelines, using colors becomes super easy.
Let me show you how to implement these guidelines with ggplot 🧵
#rstats
With the right guidelines, using colors becomes super easy.
Let me show you how to implement these guidelines with ggplot 🧵
#rstats
Anyone can create a stacked bar chart with ggplot.
But that can end up in a colorful & messy plot.
Let's implement a couple of guidelines from this datawrapper blog post to level up our color game blog.datawrapper.de/10-ways-to-use…
But that can end up in a colorful & messy plot.
Let's implement a couple of guidelines from this datawrapper blog post to level up our color game blog.datawrapper.de/10-ways-to-use…

The key is to reduce the amount of colors and leverage the `alpha` aesthetic as well.

Once you have fewer colors. You can concentrate on a better choice. How about the color-blind safe okabe ito palette?
While you're at it. How about a better range of `alpha` values so that top and bottom blocks have the same transparency?
While you're at it. How about a better range of `alpha` values so that top and bottom blocks have the same transparency?

Now comes the hard part. Consolidate the two legends into one.
Overwriting the aesthetics in a guides() layer will do the trick.
Overwriting the aesthetics in a guides() layer will do the trick.

There you go. Same information as in the beginning but less of a rainbow mess. 🌈
Still it would be nice to make adjacent blocks stand out.
No problem. Use the `color` aesthetic to add lines.
But wait. There is more 🥳
Still it would be nice to make adjacent blocks stand out.
No problem. Use the `color` aesthetic to add lines.
But wait. There is more 🥳

Spaghetti plots are easy to create but hard to decipher.
This is a chance to shine for the {gghighlight} package.
This is a chance to shine for the {gghighlight} package.

{gghighlight} makes it dead-simple to emphasize parts of your plot.
And with a small annotation, we can immediately tell a story.
And with a small annotation, we can immediately tell a story.


Of course, this also works with more than just one color.
Once we get rid of too many colors, why not also get rid of other clutter like the legend?
Once we get rid of too many colors, why not also get rid of other clutter like the legend?


That's some efficient use of space and colors right there!
Finally, let's come full circle and apply the same labeling techniques to our initial bar plot.
Finally, let's come full circle and apply the same labeling techniques to our initial bar plot.

That's a wrap 🥳
For the full code and more explanations, check out my blog post at albert-rapp.de/posts/ggplot2-…
Let me know if you enjoyed this thread, by hitting the like button on the start of this thread below. ☺️
For more posts like this, follow @rappa753
See you next time 👋
For the full code and more explanations, check out my blog post at albert-rapp.de/posts/ggplot2-…
Let me know if you enjoyed this thread, by hitting the like button on the start of this thread below. ☺️
For more posts like this, follow @rappa753
See you next time 👋
https://twitter.com/rappa753/status/1667532091100372993
• • •
Missing some Tweet in this thread? You can try to
force a refresh