

 A few comments.
A few comments.

 Let's consider a very simple app called FitGPT.
Let's consider a very simple app called FitGPT. 
 Let's get back first to the fundamentals of fine-tuning a model. 📚
Let's get back first to the fundamentals of fine-tuning a model. 📚 2/
2/ 
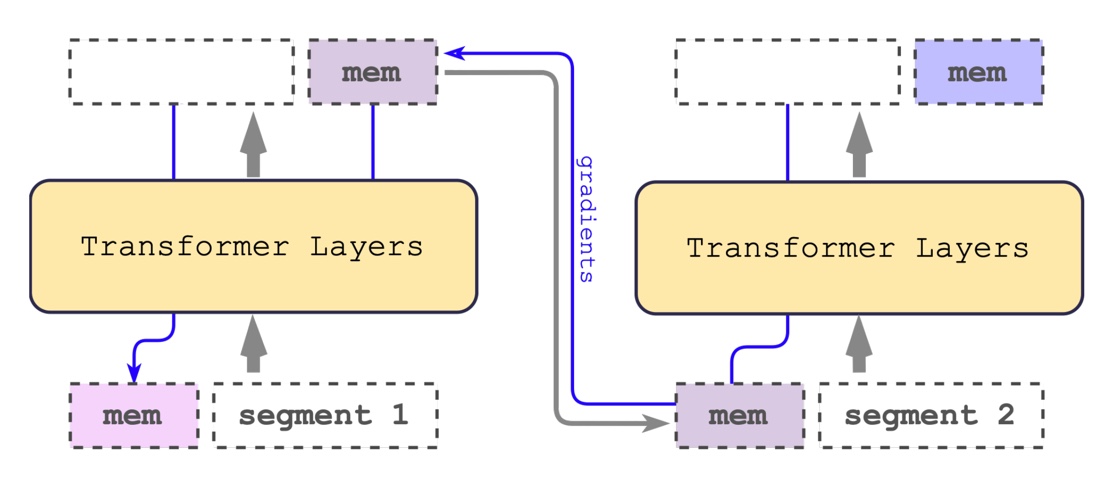
 2/♾ RMT, Recurrent Memory Transformer, is able to retain information across up to 2 million tokens!
2/♾ RMT, Recurrent Memory Transformer, is able to retain information across up to 2 million tokens! 2/📦 Stuffing
2/📦 Stuffing  2/
2/ Microsoft just released DeepSpeed Chat, a game-changing end-to-end RLHF pipeline for training ChatGPT-like models! 😍👏
Microsoft just released DeepSpeed Chat, a game-changing end-to-end RLHF pipeline for training ChatGPT-like models! 😍👏
 I will publish in the following days (tinyurl.com/yxf5xpku) a technical report* on this paper. Please follow to get notified. It will be accessible for everyone (not only patrons). You are welcome to follow.
I will publish in the following days (tinyurl.com/yxf5xpku) a technical report* on this paper. Please follow to get notified. It will be accessible for everyone (not only patrons). You are welcome to follow. 1/
1/ 1/
1/ When you are asking an LLM, let's say GPT-4, to code something, it is fair to say (although I am simplifying things a bit) that it is converging to the expectancy level of the training data.
When you are asking an LLM, let's say GPT-4, to code something, it is fair to say (although I am simplifying things a bit) that it is converging to the expectancy level of the training data. 
 The paradox is often misunderstood as being about the probability of two people in a group having the same birthday, but it's actually about the probability of any two people in the group having the same birthday.
The paradox is often misunderstood as being about the probability of two people in a group having the same birthday, but it's actually about the probability of any two people in the group having the same birthday.  RNNs, first introduced in 1986 by David Rumelhart, form the foundation of it all. RNNs are specialized artificial neural networks designed to work with time-series or sequence data (paper: lnkd.in/d4jeAZnJ).
RNNs, first introduced in 1986 by David Rumelhart, form the foundation of it all. RNNs are specialized artificial neural networks designed to work with time-series or sequence data (paper: lnkd.in/d4jeAZnJ). 1/Revolutionary new open-source large language model beats GPT-3 and PALM! And the best part? You can run it for free on your own computer-
1/Revolutionary new open-source large language model beats GPT-3 and PALM! And the best part? You can run it for free on your own computer-