We find *huge* amounts of misinformation spread through images that has been missed by previous studies.
academic.oup.com/joc/advance-ar…
We went big, collecting more than 13 million posts, from more than 25,000 of the most popular politics pages and public groups, in August through October 2020.
Because FB activity is so concentrated, these pages and groups produce >95% of engagement about US politics.
Mar 30, 2018 • 17 tweets • 3 min read
SCOOP: I have learned how #CambridgeAnalytica built their Facebook targeting model.
How did I find out, you ask? Funny story.
I, um, emailed Aleksandr Kogan, and he told me.
theconversation.com/how-cambridge-…
Link to the story should be live shortly. But if you missed it, here’s the story so far. I was on the right track, it seems:
External Tweet loading...
If nothing shows, it may have been deleted
by @MattHindman view original on Twitter
Mar 23, 2018 • 25 tweets • 7 min read
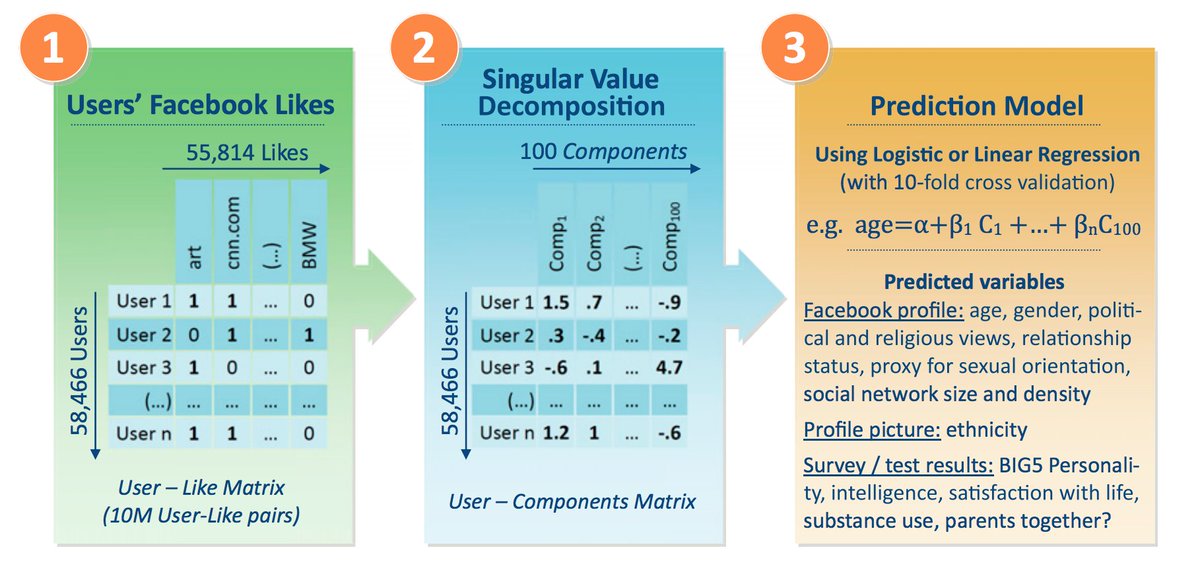
After digging a bit deeper, I have a strong suspicion about how #CambridgeAnalytica was doing their targeting.
My theory: Cambridge Analytica was matching users with political messages using the exact same technique Netflix uses to recommend you movies.
If I’m right, press coverage (and CA’s hype) has it backwards: The predictions themselves DO NOT depend on psychometrics, not really.
On the other hand, if my guess is correct, CA’s targeting was likely state of the art. I expect it worked exceedingly well.
Mar 19, 2018 • 8 tweets • 2 min read
I am seeing a lot of skepticism about #cambridgeanalaytica’s statistical methods that, while correct, mostly misses the point.
Getting good data on 50 million FB profiles would be a big deal _even_if_ CA’s psychometrics were bunk.
This is not about building an ultra-clever statistical model, it’s about being able to AVOID having to build a fancy model in the first place.